







前面已经知道了用点估计量来估计总体的均值、方差或一定比例的精确值 :是根据样本数据有可能做出的最好的猜测。现介绍另一种估计总体统计量的方法——一种考虑了不确定性的方法。:是根据样本求出总统统计量的一个有高可信度的数值范围。
为什么要用置信区间
在利用点估计量求出总体的主要统计量时,就算我们取到了无偏估计量,但是我们在取其他样本来做分析时也不会是该估计量,这就会对我们的分析做出错误的引导,而且现实生活中我们也没有把握样本能100%地代表总体。
所以在这里我们就对点估计量取一个区间,我们就可以求出点估计量落在这个区间的概率,这个概率就称为置信区间。我们区间的选取是建立在点估计量上的,所以我们要尽量地保证点估计量的无偏程度,这样才能保证置信区间的可信度。
*可以认为要先求出点估计量,再依据点估计量求出置信区间。
求置信区间的四个步骤
1.选择总体统计量 :是指希望用于构建置信区间的总体统计量
2.求出其抽样分布 :获取无偏样本,求出选择的总体统计量的概率分布
3.决定置信水平 :选择区间中包含总体统计量的概率大小
4.求出置信区间的上下限 :求出这个区间的具体数值
置信区间的简便算法
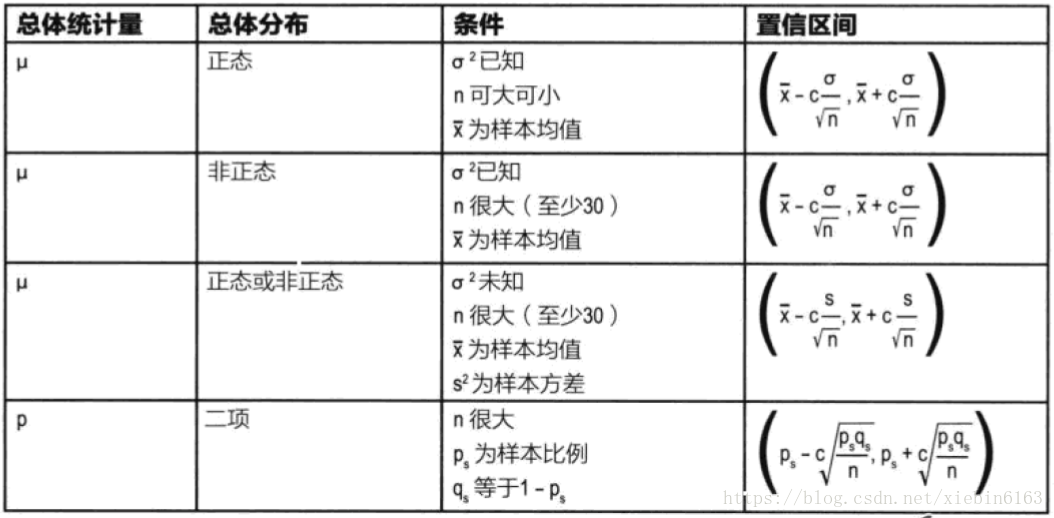
当样本不服从正态分布时
在抽样的数量很大时,我们可以认为样本的均值服从正态分布(也就是中心极限定理)。但是在样本很小时,我们就不能保证中心极限定理有效了。
尽管总体服从正态分布,可样本也有可能不服从正态分布这是因为:
- 当不了解总体分布方差的确切值时,虽然可以通过样本的点估计量求出。但是如果样本数量较小,求出来的方差误差就会比较大,就不能保证准确性。
小样本时无法精确地体现总体的方差,这时候用t分布来估计会更精确。
因为t分布的参数v值(n-1)考虑了样本的大小,也就是t分布的形状与v值有关,v值较小分布越宽。这样t分布给出的置信区间比正态分布的置信区间更宽,在相同的置信水平情况下,得到的置信区间的准确性就更高。















 689
689











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









