







mysql数据库的索引的实现方式(
B-Tree和B+Tree 这里以mysql数据库为例)
关于B树和B+树请参考关于B树的一些总结,这篇文章介绍的比较详细,同时容易理解。
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构,在本文的下一节会结合存储器原理及计算机存取原理讨论为什么B-Tree和B+Tree在被如此广泛用于索引,这一节先单纯从数据结构角度描述它们。
B-Tree
为了描述B-Tree,首先定义一条数据记录为一个二元组[key, data],key为记录的键值,对于不同数据记录,key是互不相同的;data为数据记录除key外的数据。那么B-Tree是满足下列条件的数据结构:
- d>=2,即B-Tree的度;
- h为B-Tree的高;
- 每个非叶子结点由n-1个key和n个指针组成,其中d<=n<=2d;
- 每个叶子结点至少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶结点的指针均为NULL;
- 所有叶结点都在同一层,深度等于树高h;
- key和指针相互间隔,结点两端是指针;
- 一个结点中的key从左至右非递减排列;
- 如果某个指针在结点node最左边且不为null,则其指向结点的所有key小于v(key1),其中v(key1)为node的第一个key的值。
- 如果某个指针在结点node最右边且不为null,则其指向结点的所有key大于v(keym),其中v(keym)为node的最后一个key的值。
- 如果某个指针在结点node的左右相邻key分别是keyi和keyi+1且不为null,则其指向结点的所有key小于v(keyi+1)且大于v(keyi)。
图2是一个d=2的B-Tree示意图。
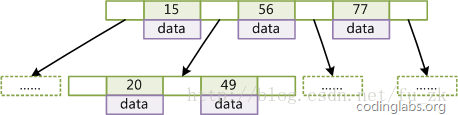
图2
由于B-Tree的特性,在B-Tree中按key检索数据的算法非常直观:首先从根节点进行二分查找,如果找到则返回对应节点的data,否则对相应区间的指针指向的节点递归进行查找,直到找到节点或找到null指针,前者查找成功,后者查找失败。B-Tree上查找算法的伪代码如下:

BTree_Search(node, key) { if(node == null) return null; foreach(node.key) { if(node.key[i] == key) return node.data[i]; if(node.key[i] > key) return BTree_Search(point[i]->node); } return BTree_Search(point[i+1]->node); } data = BTree_Search(root, my_key);
关于B-Tree有一系列有趣的性质,例如一个度为d的B-Tree,设其索引N个key,则其树高h的上限为logd((N+1)/2),检索一个key,其查找结点个数的渐进复杂度为O(logdN)。从这点可以看出,B-Tree是一个非常有效率的索引数据结构。
B+Tree
B-Tree有许多变种,其中最常见的是B+Tree,例如MySQL就普遍使用B+Tree实现其索引结构。
与B-Tree相比,B+Tree有以下不同点:
- 每个结点的指针上限为2d而不是2d+1。
- 内结点不存储data,只存储key;叶子结点不存储指针。
图3是一个简单的B+Tree示意。
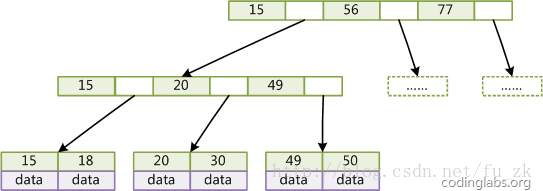
图3
由于并不是所有节点都具有相同的域,因此B+Tree中叶结点和内结点一般大小不同。这点与B-Tree不同,虽然B-Tree中不同节点存放的key和指针可能数量不一致,但是每个结点的域和上限是一致的,所以在实现中B-Tree往往对每个结点申请同等大小的空间。
一般来说,B+Tree比B-Tree更适合实现外存储索引结构,具体原因与外存储器原理及计算机存取原理有关,将在下面讨论。
带有顺序访问指针的B+Tree
一般在数据库系统或文件系统中使用的B+Tree结构都在经典B+Tree的基础上进行了优化,增加了顺序访问指针。
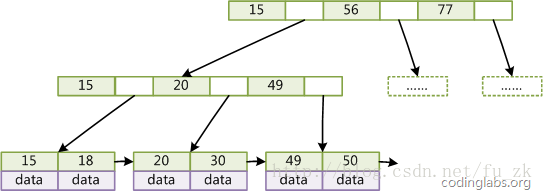
图4
如图4所示,在B+Tree的每个叶子结点增加一个指向相邻叶子结点的指针,就形成了带有顺序访问指针的B+Tree。做这个优化的目的是为了提高区间访问的性能,例如图4中如果要查询key为从18到49的所有数据记录,当找到18后,只需顺着结点和指针顺序遍历就可以一次性访问到所有数据结点,极大提到了区间查询效率。
这一节对B-Tree和B+Tree进行了一个简单的介绍,下一节结合存储器存取原理介绍为什么目前B+Tree是数据库系统实现索引的首选数据结构。
为什么使用B-Tree(B+Tree)
上文说过,红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构,这一节将结合计算机组成原理相关知识讨论B-/+Tree作为索引的理论基础。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。下面先介绍内存和磁盘存取原理,然后再结合这些原理分析B-/+Tree作为索引的效率。
)
B-Tree和B+Tree
关于B树和B+树请参考关于B树的一些总结,这篇文章介绍的比较详细,同时容易理解。
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构,在本文的下一节会结合存储器原理及计算机存取原理讨论为什么B-Tree和B+Tree在被如此广泛用于索引,这一节先单纯从数据结构角度描述它们。
B-Tree
为了描述B-Tree,首先定义一条数据记录为一个二元组[key, data],key为记录的键值,对于不同数据记录,key是互不相同的;data为数据记录除key外的数据。那么B-Tree是满足下列条件的数据结构:
- d>=2,即B-Tree的度;
- h为B-Tree的高;
- 每个非叶子结点由n-1个key和n个指针组成,其中d<=n<=2d;
- 每个叶子结点至少包含一个key和两个指针,最多包含2d-1个key和2d个指针,叶结点的指针均为NULL;
- 所有叶结点都在同一层,深度等于树高h;
- key和指针相互间隔,结点两端是指针;
- 一个结点中的key从左至右非递减排列;
- 如果某个指针在结点node最左边且不为null,则其指向结点的所有key小于v(key1),其中v(key1)为node的第一个key的值。
- 如果某个指针在结点node最右边且不为null,则其指向结点的所有key大于v(keym),其中v(keym)为node的最后一个key的值。
- 如果某个指针在结点node的左右相邻key分别是keyi和keyi+1且不为null,则其指向结点的所有key小于v(keyi+1)且大于v(keyi)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1063
1063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









