







目录
路径类
1. 获取一个路径最后一个目录或文件的名字
os.path.basename("D:\Project\AI-learning\Pytorch-UNet\data\masks\IMG_100_mask.npy")
# 输出: IMG_100_mask.npy
或者:
head,tail = os.path.split("D:\Project\AI-learning\Pytorch-UNet\data\masks\IMG_100_mask.npy")
# head='D:\\Project\\AI-learning\\Pytorch-UNet\\data\\masks',tail='IMG_100_mask.npy'2. 获得文件名的拓展名
import os
file = "Hello.py"
# 获取前缀(文件名称)
assert os.path.splitext(file)[0] == "Hello"
# 获取后缀(文件类型)
assert os.path.splitext(file)[-1] == ".py"
assert os.path.splitext(file)[-1][1:] == "py"图片处理类
1. 数据增强,图像左右反转
可以对Image对象进行如下操作:
new_img = img.transpose(Image.Transpose.FLIP_LEFT_RIGHT)
也可以对2维度np数组:
kpoint = np.fliplr(kpoint)2. 数据增强,随机缩放
模板例子:
if self.args['scale_aug'] == True and random.random() > (1 - self.args['scale_p']):
self.rate = random.choice([0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1.05, 1.1, 1.15, 1.2, 1.25, 1.3]) # 缩放倍数
width, height = img.size
width = int(width * self.rate)
height = int(height * self.rate)
img = img.resize((width, height), Image.ANTIALIAS)
3. 数据增强,随机裁剪
crop_size_x = random.randint(0, img.shape[1] - width)
crop_size_y = random.randint(0, img.shape[2] - height)
sub_img = img[:, crop_size_x: crop_size_x + width, crop_size_y:crop_size_y + height]4. 读取图片的shape格式
- cv2.imread: 读取返回一个数组,它的shape含义:(h,w,c) c是BGR格式
- 先读取为Image对象,再转换为np.ndarray对象,shape含义和上面的一致
5. cv2 BGR转RGB
cv2里面都是默认BGR的,所以在打开或者保存文件之前,都要转换成BGR。
img = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)6. 给图片设置边界框、边界填充
方法:cv2.copyMakeBorder
作用:给图片设置边界框,可以用于填充。
参数:
- src: 输入的图片
- dst: 目标图片
- top
- bottom
- left
- right: 这四个参数是设置图片四个方向上填充多少个像素
- borderType: 只介绍常用的
- cv2.BORDER_CONSTANT:添加的边界框像素值为常数(需要额外再给定一个参数)
- cv2.BORDER_REFLECT:添加的边框像素将是边界元素的镜面反射
- cv2.BORDER_REPLICATE:使用最边界的像素值代替
- value: 如果borderType为
cv2.BORDER_CONSTANT时需要填充的常数值。
7. pyplot子图标题
使用pyplot画图时,经常需要画出如下的图:

即:一张大图里面包含几张子图,大图有总的标题,子图也有其子标题。画法如下:
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
img = Image.open('./example_images/1.png').convert('RGB')
img = np.array(img)
# 根据图片大小来设定画布大小
dpi = 100
fig_size = [img.shape[0]*4.0/dpi,img.shape[1]*3.0/dpi]
plt.figure(dpi=dpi,figsize=fig_size)
# 主标题
plt.suptitle("main title")
for i in range(1,5):
ax = plt.subplot(2,2,i)
# 子标题
ax.set_title(F'fig{i}')
# 不显示坐标轴
plt.axis('off')
plt.imshow(img)
plt.show()8. 排列堆叠图片
看到有一份代码里面出现了np.hstack np.vstack,适合拼接图片。留个坑,以后有空了仔细研究一下。
9. 获取图片中非零像素的索引
np.nonzero: 返回b中的非零元素坐标。以二维数组为例:
a = np.array([[0,0,3],[0,0,0],[0,0,9]])
b = np.nonzero(a)
print(b)
输出:
(array([0, 2], dtype=int64), array([2, 2], dtype=int64))输出两个数组,分别是非零元素的x坐标和y坐标。是一一对应的。
10. pyplot保存图片白边太多
1. 保存少量白边
可以在savefig时指定参数:
plt.savefig('test.jpg', bbox_inches='tight',dpi=200)但是可能导致对图片尺寸大小的设置失效。另外需要设定一下dpi,否则图片会很模糊。
2. 完全不要白边
plt.subplots_adjust(top=1, bottom=0, right=1, left=0, hspace=0, wspace=0)
plt.margins(0, 0)11. 不同库的坐标
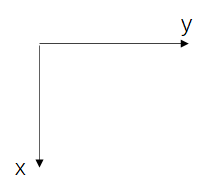
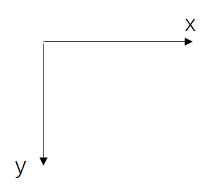
下图中x表示第一个维度,y表示第二个维度
opencv-python:
PIL:
12. cv2画矩形框
cv2.rectangle,是靠 确定对角线 来画矩形的。
cv2.rectangle(img, (bbox.left, bbox.top), (bbox.right, bbox.bottom), (0,0,255), 2)。后面两个一个是RGB颜色,另一个是线条宽度
13. 框出图片中的某一区域并且取得坐标
可以使用cv2.selectROI。回自动输出一个坐标。按空格或者回车完成绘制,按C退出。
selectROI(windowName, img, showCrosshair=None, fromCenter=None):
. 参数windowName:选择的区域被显示在的窗口的名字
. 参数img:要在什么图片上选择ROI
. 参数showCrosshair:是否在矩形框里画十字线.
. 参数fromCenter:是否是从矩形框的中心开始画
返回的是一个元组r = [min_x,min_y,w,h]:
如果要切片出来需要转换一下:[int(r[1]):int(r[1]+r[3]),int(r[0]):int(r[0]+r[2])]14. numpy的c_和r_
np.c_是np.r_['-1,2,0', index expression]的一种简写,就是沿着矩阵的第二个轴拼接。对于二维矩阵,就是按照列column,要求两个矩阵的行数相等
# -*- coding: utf-8 -*
import numpy as np
x_1 = np.array([1, 2, 3, 4, 5, 6]).reshape(2, 3)
x_2 = np.array([3, 2, 1, 8, 9, 6]).reshape(2, 3)
x_new = np.c_[x_1,x_2]
print("x_1 = \n",x_1)
print("x_2 = \n",x_2)
print("x_new = \n",x_new)
# 输出如下:
x_1 =
[[1 2 3]
[4 5 6]]
x_2 =
[[3 2 1]
[8 9 6]]
x_new =
[[1 2 3 3 2 1]
[4 5 6 8 9 6]]np.r_是沿着row进行拼接
15. numpy有用的api
1. 返回排序后数组的索引: np.argsort
2. np.argwhere:返回一个二维数组,每一行代表一个满足条件的元素的索引,即使是在一个一维数组中查找,也会返回一个二维数组
3. np.where 有时候会返回一个包含一个元素的元组
1.np.where(condition,x,y) 当where内有三个参数时,第一个参数表示条件,当条件成立时where方法返回x,当条件不成立时where返回y
2.np.where(condition) 当where内只有一个参数时,那个参数表示条件,当条件成立时,where返回的是每个符合condition条件元素的坐标,返回的是以元组的形式
读取数据集
1. ShanghaiTech
import scipy.io as sio
# anno_path是标注文件的路径
data = sio.loadmat(anno_path)
# 标注点位置
xy = data['image_info'][0][0][0][0][0] # (n,2)格式数据
cnt = data['image_info'][0][0][0][0][1][0][0] # 人数
需要注意的是,这里的坐标格式是(w_idx,h_idx)
附上一个可视化查看标注位置是否对应正确的代码:
for xy in xys:
w_idx = int(xy[0])
h_idx = int(xy[1])
img[h_idx-5:h_idx+5,w_idx-5:w_idx+5,:] = [0,0,255]
plt.imshow(img)
plt.show()2. UCF-QNRF
这个数据集文件夹下有train test两个文件夹,标注和图片都在同一个文件夹里。标注是.mat文件格式,读取标注文件后,在其'annPoints'键的值中就是标注的数据。是(人头数目,2)格式,其中的2是(w_idx,h_idx)。示例代码如下:
test_img_path = r"./qnrf\img_0001_ann.mat"
test_anno_path = test_img_path.replace('.jpg','_ann.mat')
data = sio.loadmat(test_anno_path)
data = data['annPoints']
x = [i[0] for i in data]
y = [i[1] for i in data]
x = np.array(x).astype(np.int16)
y = np.array(y).astype(np.int16)
for i in range(len(x)):
img[y[i]-5:y[i]+5,x[i]-5:x[i]+5,...] = [255,0,0]
plt.imshow(img)
plt.axis('off')
plt.show()数据持久化
1. h5py存储数据
import h5py
with h5py.File(h5_path,'w') as hf:
hf['key'] = data
读取数据:
file = h5py.File(h5_path,'r')
data = np.asarray(file['key'])2. numpy存储:数组、字典
1. 保存一般的数组文件直接用np.save就可以保存为npy文件了
2. 保存与读取字典格式数据:
import numpy as np
a = {'alpha':1,'beta':'b','gamma':[2,3]}
# 保存
np.save('test',a)
# 读取
b = np.load('test.npy',allow_pickle=True).item()













 563
563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









