







 本文汇总了三篇CVPR2022的计算机视觉论文,包括FAIR团队提出的ConvNeXt,它在不逊色于Transformer性能的同时,复兴了ConvNet;研究发现增大卷积核尺寸可以提升模型性能;以及MPViT,一种结合多路径结构与Transformer的新型视觉模型,适用于密集预测任务。这些工作展示了卷积与Transformer在视觉领域的最新进展。
本文汇总了三篇CVPR2022的计算机视觉论文,包括FAIR团队提出的ConvNeXt,它在不逊色于Transformer性能的同时,复兴了ConvNet;研究发现增大卷积核尺寸可以提升模型性能;以及MPViT,一种结合多路径结构与Transformer的新型视觉模型,适用于密集预测任务。这些工作展示了卷积与Transformer在视觉领域的最新进展。
今日推荐几篇最新/经典计算机视觉方向的论文,涉及诸多方面,都是CVPR2022录用的文章,具体内容详见论文原文和代码链接。
Convnet新活力

- 论文题目:A ConvNet for the 2020s
- 论文链接:https://arxiv.org/abs/2201.03545
- 代码链接:https://github.com/facebookresearch/ConvNeXt
“文艺复兴”,ConvNet卷土重来,压过Transformer。本文是FAIR的Zhuang Liu(DenseNet的作者)与Saining Xie(ResNeXt的作者)关于ConvNet的最新探索,以ResNet为出发点,逐步引入近来ViT架构的一些设计理念而得到的纯ConvNet新架构ConvNeXt,取得了优于SwinT的性能,让ConvNet再次性能焕发。
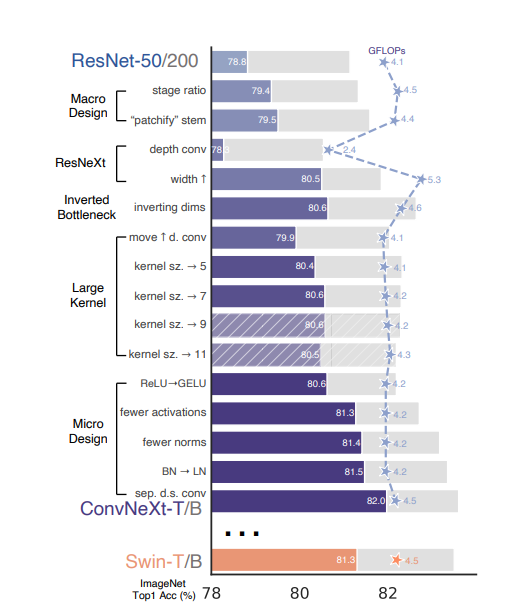
从上图可以看到网络架构每一次进化所能取得的性能(ConvNeXt-T取得了82%,超越了Swin-T的81.3%),由于模型复杂度与最终性能相关,故FLOPs进行了一定程度的控制。
卷积核越大越涨点
-
论文题目:Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNN
-
论文链接:https://arxiv.org/abs/2203.06717
-
代码链接:https://github.com/MegEngine/RepLKNet

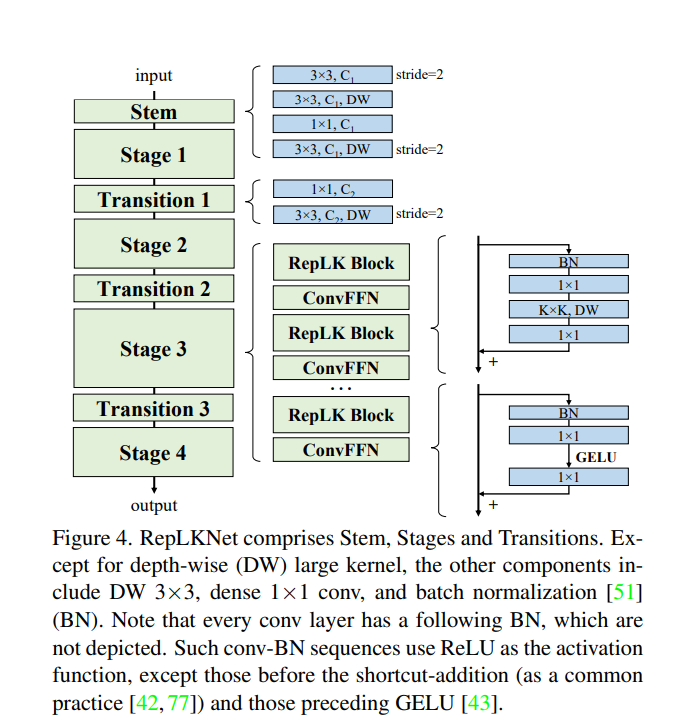
我们发表于CVPR 2022的工作表明,CNN中的kernel size是一个非常重要但总是被人忽略的设计维度,在现代模型设计的加持下,卷积核越大越暴力,既涨点又高效,甚至大到31x31都非常work(如下表所示,左边一栏表示模型四个stage各自的kernel size)!即便在大体量下游任务上,我们提出的超大卷积核模型RepLKNet与Swin等Transformer相比,性能也更好或相当!
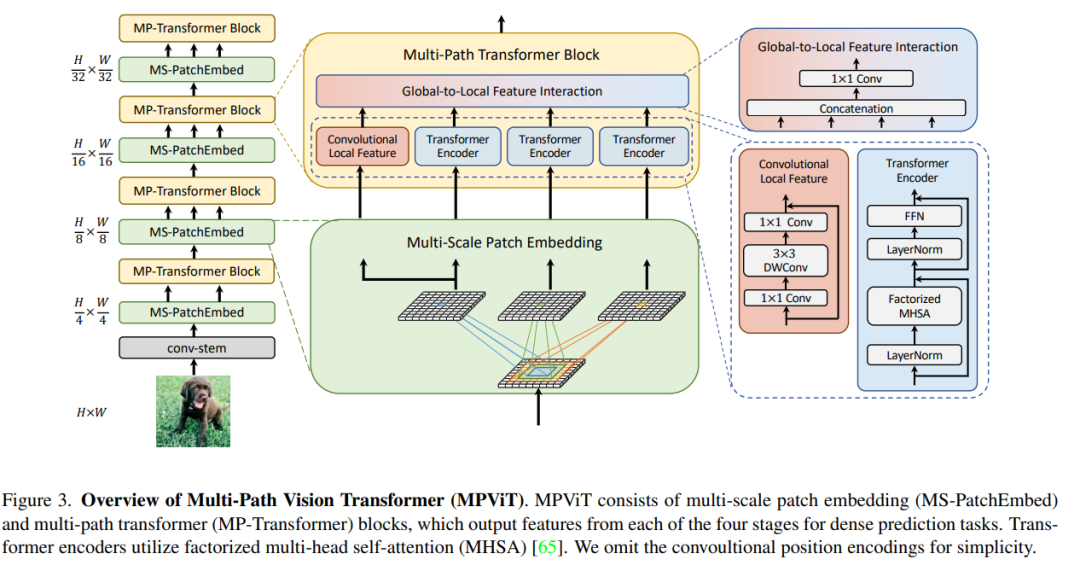
新主干!MPViT:用于密集预测的多路径视觉Transformer
-
论文题目:MPViT: Multi-Path Vision Transformer for Dense Prediction
-
论文链接:https://arxiv.org/abs/2112.11010
-
代码链接:https://github.com/youngwanLEE/MPViT

-
在这项工作中,作者以不同于现有Transformer的视角,探索多尺度path embedding与multi-path结构,提出了Multi-path Vision Transformer(MPViT)。
-
通过使用 overlapping convolutional patch embedding,MPViT同时嵌入相同大小的patch特征。然后,将不同尺度的Token通过多条路径独立地输入Transformer encoders,并对生成的特征进行聚合,从而在同一特征级别上实现精细和粗糙的特征表示。
-
在特征聚合步骤中,引入了一个global-to-local feature interaction(GLI)过程,该过程将卷积局部特征与Transformer的全局特征连接起来,同时利用了卷积的局部连通性和Transformer的全局上下文。
后续
下一期最新/经典视觉cvpr顶会论文敬请期待!


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











