






背景
这是我们团队负责的一个不太核心的服务。之前与外部交互时应外部要求由普通kafka集群改成加密kafka集群。我们是数据生产端。

改的过程中并跑上线,60%的请求耗时增加了2倍,也还是在百毫秒的量级可以接受。但是每次重启的第一个请求要5s以上,会超过;运行过程中,一两个月也会有一次超时。因为我们有三次重试,整体没有影响成功率。
上线的时候我们问过网络组,还专门请教过公司专业负责kafka的团队。结论是:第一,这个慢是外部交互方的问题,不是咱们这边可以处理的;第二,参数上也没有什么可以调优的。
我们团队内部还是不信邪,调了几个参数,加测之后上线了。频繁度降到了现在的一两个月一次超时,但是没有根治。因为本身这个服务不是特别核心,本身外部是允许有一定失败率的,而且现在实际上也没有失败,几年内业务量也是很平稳的:1分钟4笔。
而我上班时间的状态基本上是我站在两个人中间,我目的是想问一个人问题,结果却先要回答另外一个人的问题,这时候还会出现第四个人说别的事。这个优先级排不上。但是心疼开发小哥哥,每一两个月就要处理一下因为这件事引起的告警。虽然实际不影响,告警出来了,我们就要排查核对是否还是这个问题,并且确实通过重试将消息推送出去了。
所以本次利用周末,希望可以根治这个疑难杂症,减少运维成本。
思路
前期已经明确了这个外部的加密集群建立连接和数据传输速度都慢于之前的普通集群。之所以第一次慢和每一两个月会慢一次都是连接断开重连造成的。之前我们进行过参数调优,调优做的就是因为1分钟4笔请求,线上以最小部署单元3台机器部署,每台机器1分钟预计处理一笔请求。根据这个数据调整了空闲自动断开连接的时间间隔,保证连接不会因为空闲自动断开。线上验证有效,也侧面证实了是连接过程慢引起的超时。
因为建立连接过程慢,这个主要是外部提供的集群就是如此。既然目前并不影响实际发送成功率。人家代表的是大佬,我们也不好太强硬的去推他们解决。所以我的思路有两个:
第一,探索将建立连接与发送数据分离的可行性:程序启动后先将连接建立好再提供服务。如果生产端是这样实现的。那也许还可以进行连接自动探测,如果连接断开则自动重连,不要等发送数据时再发现连接已断开。
第二,其实第一种思路的可行性渺茫,只是需要验证一下自己的想法。一般的这种消息中间件,消费端是这样实现的。但是生产端采用了更简单的方式:读写数据的时候再探测连接是否可用,不可用则重新建立连接。这种用在发送本来就是异步的,对发送延迟本身敏感度也不高的场景。生产端本来就是这种场景,并且通过测试实际上也确实是在发送时建立的第一次连接。kafka生产端原本就是这种设计的可能性极大。如果是这种情况,那就在生产端真正使用异步,给调用方返回“受理成功”,保证调用方不超时。自己再通过接受回调保证实际的成功。
这个事情真要做,还有两个隐形需求:
1、因为外部有需求,数据可以偶尔少发,但是不能重复发送。所以不能使用业务级别的数据发送来实现探测功能。重试也要保证上条确实没有收到。
2、改造不能太大,研发成本要小。
过程
因为我在网上搜到的这方面都是入门级,没有什么解决这个问题的相关资料。所以采用的主要方法是读源码和官方文档。当然,本文的方法是有前提知识储备基础的。就是《白话TCP/IP原理》系列的相关内容。
步骤一,查询版本特性
我们目前用到的kafka客户端版本是
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.5.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.5.0</version>
</dependency>spring-kafka对应的官网的大版本是2.5,所以先点开了2.5.17.RELEASE对应的参考文档。看到一句有用信息:
The default consumer and producer factories can now invoke a callback whenever a consumer or producer is created or closed.
默认消费者和生产者工厂现在已经可以在生产者和消费者创建和关闭时引发一个回调。耗时的连接建立过程是可以监听的,我们可以通过打日志进行监控。
步骤二,查源码
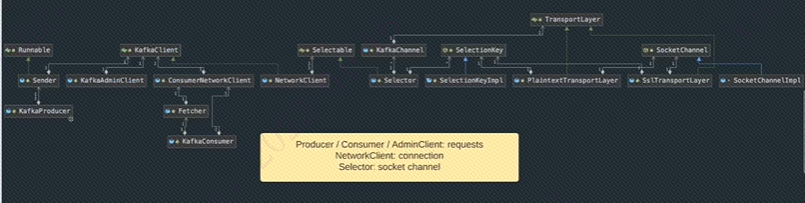
首先我们看一下类图,看不清楚没有关系。看这里就好:
首先发现Producer、Consumer和Sender都是通过KafkaClient(接口),也就是NetworkClient(实现类)进行网络活动的。其次发现NetworkClient是在传输层和应用层之间起了一个缓冲的作用,解耦了各个部件。
Producer、Consumer和AdminClient主要管理requests;NetworkClient主要管理connection;Selector主要管理sockets channel。这些被管理对象我在之前的网络系列里都讲过。
如果不看代码,我站在设计者角度结合类图猜想:生产端实际使用的是KafkaTemplate的send方法,具体的参数都是由DefaultKafkaProducerFactory接收。实际上连接的建立是Producer类进行。而在Producer类依赖于NetworkClient。而实际上进行连接应该在Sender类。Sender是一个Runnable异步线程来做,那实际建立连接的是run方法中。
我跟踪源码验证了猜想。NetworkClient里有个initiateConnect的私有方法,是建立连接用的,跟踪它就可以知道调用的地方。跟踪下来,主要入口在NetworkClient的poll方法,注释如下:
/**
* Do actual reads and writes to sockets.
*
* @param timeout The maximum amount of time to wait (in ms) for responses if there are none immediately,
* must be non-negative. The actual timeout will be the minimum of timeout, request timeout and
* metadata timeout
* @param now The current time in milliseconds
* @return The list of responses received
*/
@Override
public List<ClientResponse> poll(long timeout, long now) {人家明确说了是读写时才会调用。证实了思路一不可行。
步骤三,查自身的代码
按照思路二,进行异步化。本身生产端就应该是异步的,为什么异步没有生效呢?结合KafkaTemplate的send方法源代码和项目中自己写的代码。异步部分大体是这样:
SettableListenableFuture future = new SettableListenableFuture();
future.set("OK");
future.get();
future.addCallback((sendResult) -> {
try {
System.out.println("成功");
} catch (Exception e) {
}
}, r -> {
System.out.println("失败");
});
System.out.println("============end==============");就是说KafkaTemplate的异步是靠使用SettableListenableFuture实现的,实际上它的set方法会马上触发callback,是同步的。代码是先同步调用set,并且还手动调用了get(这个方法会等待直到返回结果)。所以整体是同步的。或者直接这么看,future实现异步要有一个Callable或者Runnable的线程方法,人家SettableListenableFuture第一行源码就禁用了Callable。这个我看了2.5.17.RELEASE这个更高版本的spring-kafka,实现没有做更改。
也就是说spring-kafka自身起码在2.5.X版本里异步没有起到作用。
问题清楚了修改也很简单,比如可以加个异步注解将整个发送方法做异步,重试等逻辑也放到这个方法中。给调用方只返回受理成功。具体怎么解决交给开发小哥哥。
总结
幸亏我上周已经提前规划好周一要休假。否则现在都2点半了明天上班也没精神。主要时间花在异步不生效的问题上。其实排查异步不生效的思路是很简单清晰的。耗时长是因为:第一,不敢相信spring官方实现的,竟然使用异步的代码实际效果没有异步;第二,关于异步我在网上搜索了一下,都是按照项目中配置的那样。官方这样说,大家这样说,我总得考虑是不是自己搞错了。
所以我反复的验证、反复的debug之后也不敢下结论。仔细研究了源码仍然不敢下结论。直到终于搜索到一篇文章说要实现异步除了要使用addCallback之外还要加异步标签。人间清醒的我,马上意识到文章实际用了两种不同方法实现异步。作者之所以认为这是一个方法的两个部分大概也是发现其实spring-kafka的异步没好使吧。

















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









