






本文的叙事结构是由浅入深,大家可根据自身情况选择跳过前面,直接往后看。
基础认知
并发和并行
并发和并行概念的不同:
1、并发:并发是指两个或多个事件在同一时间间隔发生。
2、并行:并行是指两个或者多个事件在同一时刻发生。
狭义一点理解:在同一台机器上,从CPU处理来看,并行度是有几个CPU内核并行度就是几,因为同一个时刻1个CPU只能做一件事;而并发度一般用每秒做多少事情来衡量,就出现了QPS、TPS等指标。
并发压测
压测工具如jmeter有发和收的过程,发的过程是客户端的并发度,实际测量是需要测服务端的并发数。需要通过收的结果来统计分析。
压测工具一般需要设置发压(发出对服务端的请求)的线程数。比如设置为10,这时候会对服务端产生多少压力呢?发压就好比射箭,射出去就不管了,就有精力发下一支箭。假设发压工具1个线程1ms发出一个请求,那1s就可以发出一千个请求。10个线程发压1万QPS/TPS(QPS/TPS可以统一用吞吐量来表示)。主要就看服务端的处理能力了。
并发数意义
并发数是容量评估的重要手段。业务容量包含数据量和并发量两方面。数据存储量可以通过数据归档、合理规划的磁盘容量来保证。因为磁盘相比CPU、内存,成本不高,易扩展。所以一般来说大家更关注并发量。但不管数据量还是并发量,容量问题都需要关注三个方面:可衡量、可观测、可应对。
并发数与响应时间
响应时间是指从发出请求到收到响应所花费的总时间。并发数用于容量评估,而响应时间关注点在用户体验。但理论上单笔请求响应时间越短,总体能承担的并发量就越大。它们之间相辅相成,所以性能优化考虑的指标既有并发数也有响应时间。
一般小key小value的缓存,请求响应时间平均在几百纳秒。一次数据库访问在两三毫秒。简单数据库访问的用户请求算上网络延时是十几毫秒。一般复杂度逻辑计算一般响应时长在几十到几百毫秒。
并发数衡量和观测
并发连接数
并发数和并发连接数有一定关联。
nginx在内核优化后可同时容纳10万并发连接数。注意这里面提到了内核优化后,因为nginx处理任务占用资源极少,它的性能瓶颈主要在linux的文件句柄限制。
Tomcat 默认配置的最大请求并发数为150。可以改大,但是有一定限制。瓶颈在于操作系统中对于进程中的线程数有限制:Windows 每个进程中的线程数不允许超过 2000,Linux 每个进程中的线程数不允许超过 1000。在 Java 中每开启一个线程需要耗用 1MB(可配置) 的 JVM 内存空间用于作为线程栈之用。
Jetty的并发量一般来说要优于Tomcat。但是只是在BIO、NIO上处理的区别。资源占用上区别不大,所以Jetty较Tomcat的性能有提升,但提升并不是量级上的。目前流行的组合是SpringBoot里将默认的Tomcat替换成Jetty做容器。
一台高配物理机的并发连接数可支持1万。但是这是一个很危险的数值。连接数据库的应用服务器如果是4C8G,建议默认连接数设置为5,这样数据库就可以承受千台服务器同时连接,提供比较高的扩展性。
实际处理能力
并发连接数只是并发处理的上限,并非实际处理能力。实际处理能力要受多方制约。如下图:
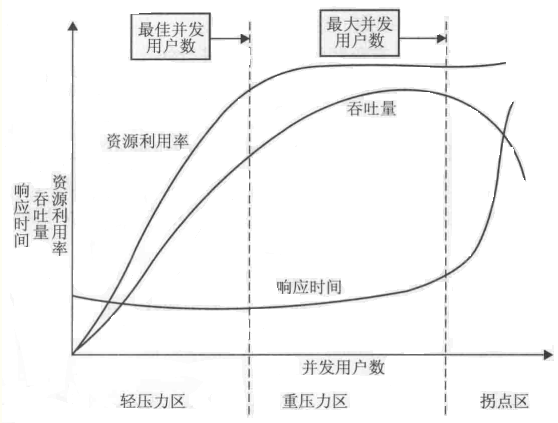
图中坐标轴的横轴从左到右表现了并发用户数(Number of Concurrent Users)的不断增长。
在进行性能测试的时候,我们需要对图中曲线进行分析。分开来看的时候,相应时间(RT)、吞吐量(TPS)和资源利用率的变化情况分别是:
响应时间:随着并发用户数的增加,在前两个区,响应时间基本平稳,小幅递增。在第三个区域:急剧递增。在第三个区的点为拐点。
吞吐量:随着并发用户数的增加,在前两个区,对于一个良好的系统来说,并发用户数的增加,请求增加,吞吐量增加,中间的区域,处理达到顶点。
资源利用率:在第三个区呈直线,表示饱和。
其实上图还少了一个主要指标:错误率。在轻压力区到重压力区的临界点,错误率也是相对少的一个最优解。
Google的四大黄金指标包括延迟(latency)、流量(traffic)、错误(errors)和饱和度(saturation)。其中延迟对应响应时间,流量对应吞吐量。
可观测
可观测主要靠容量大盘等可视化手段和容量巡检。
应对并发
应对并发的手段分为两方面,一方面是防御,另一方面是扩展。防御方面的手段比如:隔离、混部、流控、熔断和降级。先让系统柔性地提供服务,争取一个扩容的时间。
扩展又可以分为单机扩展和集群扩展。
单机扩展除了增加CPU、内存等物理扩展手段之外,还可以通过加速和增加吞吐量技术常用的比如:CDN加速、缓存、JVM调优、SQL优化、还可以考虑使用webflux等响应式编程框架提高并发量。
集群扩展主要遵循 AKF 扩展立方。X 轴水平扩容,Y 轴垂直领域拆分扩容,Z 轴按一定的算法规则扩容。
X轴扩展关注无差别的服务和数据的复制。对服务来说就是集群扩容;对数据库来说就是主从复制的方案。
Z轴拆分一种是单元化架构拆分。对数据库来说还有两种:一种就是数据库分库分表;还有一种是使用日表、月表这样方便定期删除归档的手段冷热分离来提高热数据的性能。
Y 轴垂直领域就需要用到DDD了。常用技术比如:DDD四层架构、六边形架构、微内核架构,还有像k8s架构那种基于角色的拆分。
还有异步化,基于事件驱动来分阶段处理。并发连接数是有限的,但是吞吐量的角度,可以通过队列技术,复用已有连接来处理请求。这时候想要在达到并发连接数极限时优化,就要化简请求,让单个请求响应时间更短。















 1007
1007

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









