







中文命名实体识别 Lattice LSTM
同步滚动:
论文题目:Chinese NER Using Lattice LSTM
论文地址:https://arxiv.org/pdf/1805.02023.pdf
相关源码:GitHub - jiesutd/LatticeLSTM: Chinese NER using Lattice LSTM. Code for ACL 2018 paper. 约1.5K Star
中文翻译:中文实体抽取(NER)论文笔记
中文翻译2:ChineseNER Using LatticeLSTM笔记
介绍
这是一篇2018年发表于 ACL(自然语言处理顶会) 的论文,文中提出了一种基于格子(Lattice)结构的LSTM模型,用于优化中文的命名实体识别。具体方法结合了字序列和词序列两种方式(考虑可能出现的各种分词情况)。相对于基于"字序列”的方法,模型能兼顾词间关系;相对于”词序列“的方法,模型不受分词错误的影响。门控单元让模型选择最为相关的字和词以实现实体识别。
近年来英文命名实体识别(NER)常用LSTM-CRF方法实现。中文的NER直觉上似乎应该是先做分词,再进行实体识别。然而由于跨界领域的分词问题难以解决,所以中文以字符为单位的NER往往优于以词为单位的NER。
模型
定义t(i,k),其中i是词的位置,k是在词中字的位置,如“南京市 长江大桥”中,t(2,1)是“长”,t(1,3)是“市”。
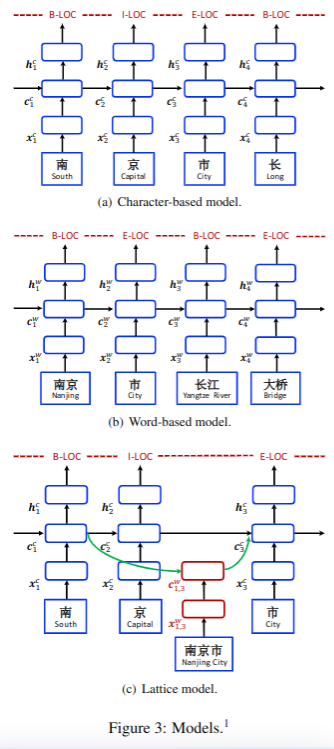
4.1 基于字符的模型
基础方法
如图3-a所示,其中
e是通过查表得到的字符c的词嵌入。
双向的lstm从前后两个方向分别计算隐藏层,得到两组参数
隐藏层的输出最终代入CRF模型。
Char + bichar
与基础方法不同的是,除了当前字符外,还考虑了下一字符, 用于查询双字对应的词嵌入。
Char + softword
将分段方法作为标签与词嵌入相连接,并作为软特征代入模型。用于查询分词标记的嵌入。也使用双向的LSTM,最终将隐藏层代入CRF模型。
4.2 基于词的模型
基础方法
基于词的模型结构如图3-b所示,
其中用于词嵌入查询,双向的lstm最终也生成了两个方向的隐藏层。
Word + char LSTM
将词嵌入和字符嵌入结合在一起:
其中表征了词i包含所有的字符嵌入,通过以下公式计算:
使用双向LSTM,学习隐藏层(我理解:由于LSTM计算的是一个序列,所以从左向右的最后一个就能代表整个串,同右向左的的1能代表所有隐藏层传递结果)。
Word + char LSTM'
这是对上一模型的微调,它使用同一个LSTM结构去训练正向和反向的词隐藏层h。
Word + char CNN
使用CNN方法对每个词生成一个字符表征,其计算方法如下:
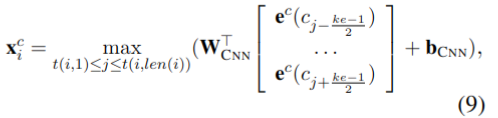
取一个最佳值j,使上式结果值最大,其中W和b是网络参数,ke=3是卷积核大小。
4.3 格子模型
LSTM的格子模型结构如下图所示:
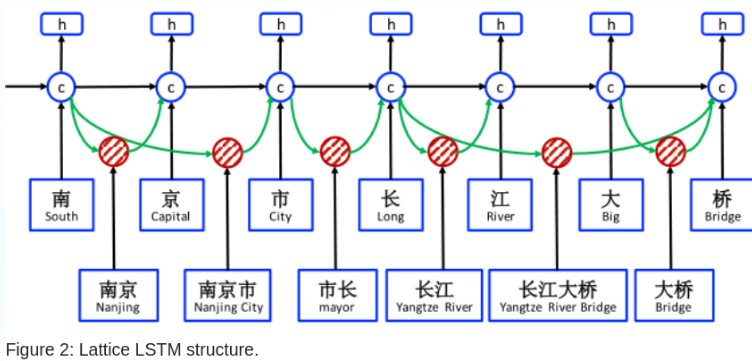
它扩展了基于字符的LSTM,加入了基于词的记忆单元和门控。
从上面的图3-c可以看到,输入是字符序列,同时增加了由该字符开头的字典D中可能出现的所有词。用来表示字符串从位置b开始,到位置e结束,比如在图1中的
南京,
大桥,
(我觉得下标好像是写错了)
模型涉及了四种类型的向量:输入向量、输出隐藏向量、记忆单元向量、门控向量。作为重要元素,每一个输入字符和基于字符的模型一样:
每个字符都被代入基本循环结构
和
,记忆单元
用于记录从头到j的信息,隐藏层
用作CRF(条件随机场)的输入。
LSTM的基本结构如下:
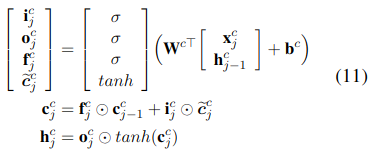
其中的i,f,o分别是输入,遗忘和输出门,和
是模型参数,σ是sigmoid激活函数。
本文提出的方法与基于字符方法不同的是:计算还涉及了词序列
:
这里的与词嵌入模型的查表方法相同。
用于表示记忆单元,具体计算方法如下:
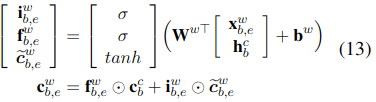
i是输入向量,f是遗忘门,需要注意的是由于没有对词元素的标签,所以这里不考虑词相关的输出门。
上式中的有多种可能性,比如:“桥“、“大桥“、“长江大桥“都是可选词,所有以”桥“结尾的词,最终都被连接到单元”桥“,用
表示。对每个
加入门控
,用于控制每个词对记忆单元
的贡献度:
对于记忆单元的计算变为(通过前一个单元和本次输入计算):
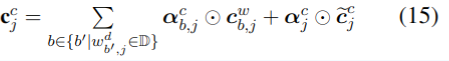
其中α是输入门i归一化的方法,具体计算方法如下:
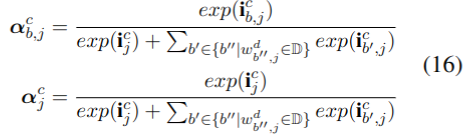
通过对损失函数的反向传播训练模型参数W和b,让模型动态地聚焦于与词更相关的label。
3.4 解码和训练
最终的CRF层使用最上层的隐藏层结果作为输入。
标签y=l1,l2....lτ,最终计算概率:
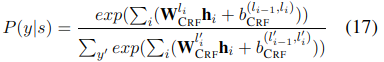
式中的W是对应标签第i个位置的模型参数,b是li-1到li的偏移。
文中使用维特比算法找到对于基于词或基于字的输入打分最高的标签,利用L2损失函数训练模型:

其中λ是正则化参数,Θ是设置参数。
4. 实验
4.1 实验设置
数据
实验部分使用了四个数据集:OntoNotes 4(新闻), MSRA(新闻), Weibo NER, Chinese resume(金融领域简历)。
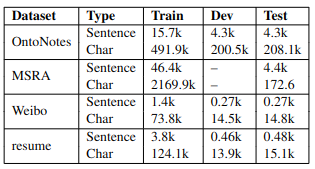
分词方法
OntoNotes的训练和测试集,MSRA的训练集,都提供了分词的金标准,而其它的数据则没有直接可用的分词方法,则使用了Yang等人提出的自动分词算法,以及通过上述金标准训练的分词器。
词嵌入
使用 word2vector 的方法提取了 704.4k 个词的词嵌入作为预训练词典,其中两字词57.7k,三字词291.5k,四字词278.1k。并在模型训练时进行了微调。
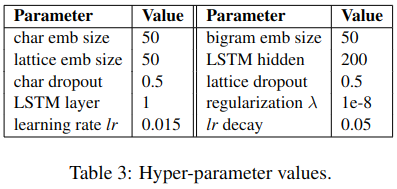
超参数设置
超参数如下表所示:
4.2 进一步实验
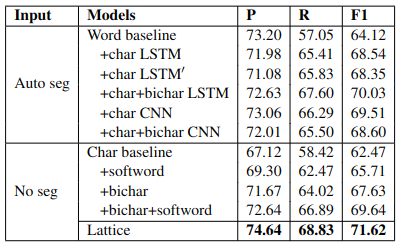
表4中对比了基于字符、词、格子三种模型的效果,
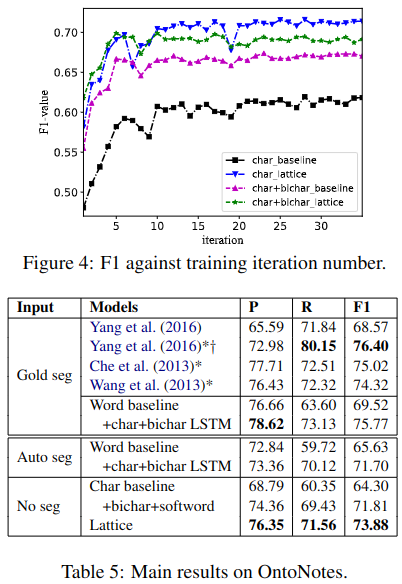
从图4,表5中可以看出Lattice方法不仅效果好,在没有分词器的情况下,也达到了好于自动分词器,仅次于金标准的效果。















 734
734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









