










java其实更多用来写业务代码,代码写得好不好,关键看抽象能力如何,不过如果你要用java写很核心的插件和高并发的片段,那么可能还是需要注意一些写法,那种写法可能会更好,才能使得并发量提高,而且更少的使用CPU和内存;我最近在一段采集系统访问的java代码,通过过滤器切入到应用中,遇到的一些小细节的调整,感觉还有点意思,以下为收集信息中碰到的两个需要判定的地方(对java优化没有任何要求的,本文纯属扯淡,呵呵):
原始代码片段1(用于判定是否为静态资源):
if(servletPath == null
|| servletPath.endsWith(".gif")
|| servletPath.endsWith(".png")
|| servletPath.endsWith(".jpg")
|| servletPath.endsWith(".bmp")
|| servletPath.endsWith(".js")
|| servletPath.endsWith(".css")
|| servletPath.endsWith(".ico")) return true;
原始代码片段2(用于判定浏览器类型):
if(StringUtils.isEmpty(userAgent)) return null;
if(userAgent.contains("MetaSr")) return "metasr";
if(userAgent.contains("Chrome")) return "chrome";
if(userAgent.contains("Firefox")) return "firefox";
if(userAgent.contains("Maxthon")) return "maxthon";
if(userAgent.contains("360SE")) return "360se";
if(userAgent.contains("Safari")) return "safari";
if(userAgent.contains("opera")) return "opera";
if(userAgent.contains("MSIE")) return "ie";
貌似一眨眼的样子,这个代码没啥优化的余地,代码片段1无非是将出现概率高的放在前面,就尽快判定成功,片段2也是这样,但是片段1里头其实有很多请求都不是静态资源,不是静态资源的话就会将7个endwith全部执行一遍下来了,也就是有很多很多的请求都将遍历所有的内容。
endWith做什么?看看源码,就是将字符串最后那部分截取下来(截取和对比串一样长的,然后和对比串对比),那么7个就会发生7次substring,每个substring操作将会生成一个新的java对象(这个大家应该清楚),每个字符串进行对比是按照字符对比的,所以按照4个四个字符进行计算,也就是会发生20多次对比操作(最坏情况),当然说最好的情况就是进行一次substring,4次对比操作(因为对比成功是每个字符对比成功才算成功)。
那么怎么优化呢,这个貌似除了调试顺序,没有太多优化的空间,根据数据你会发现一个规律,对比的结束字符有5种可能性,那么通过结束字符,就可以定位到一到两个字符串上面,所以我们第一个考虑就是取出要对比的那个字符串的结束符,看下结束符是那个字符串的结束符,然后就在一两个字符串上使用endWith,那么概率就很低了,于是乎,我们对代码片段1,做第一步优化就是:
if(servletPath == null) return false;
int length = servletPath.length();
char last = servletPath.charAt(length - 1);
if((last == 'f' && servletPath.endsWith(".gif"))
|| (last == 'g' && (servletPath.endsWith(".png") || servletPath.endsWith(".jpg")))
|| (last == 'p' && servletPath.endsWith(".bmp"))
|| (last == 's' && (servletPath.endsWith(".js")|| servletPath.endsWith(".css")))
|| (last == 'o' && servletPath.endsWith(".ico"))) return true;
此时判定完首字母后,就使用最多2个字符串进行endWith操作,经过测试,在上面最坏的情况下,效率要高出5-8倍,最初的写法在最好的情况下,和现在速度基本保持一致,但是我们上面说了,很多请求都不是静态资源,所以有很多请求都是走的最坏情况。
好了,如果你的代码不需要极高级别的优化,走到这一步已经够用了,或者说这个已经非常非常够用了,虽然优化的思路非常简单,再写就写成C++了;呵呵,不过我喜欢钻牛角尖,我也有点点洁癖,就是要玩什么,就喜欢玩到我认为的至高境界,所以我又再进行分析,画个图看看:
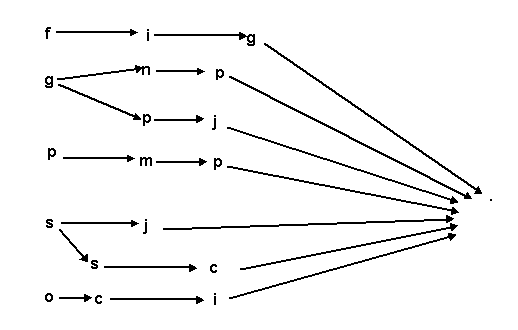
想办法是否可以去掉subtring的操作,也就是不做字符串截取的操作,我看到就那么几个字母,那么就匹配几个字母而已嘛!
于是乎代码有点像C写的了,做了进一步的改动:
if(servletPath == null) return false;
int length = servletPath.length();
if(length < 3) return false;
char last = servletPath.charAt(length - 1);
char second = servletPath.charAt(length - 2);
char third = servletPath.charAt(length - 3);
char forth;
if(length > 3 && third != '.')
forth = servletPath.charAt(length - 4);
else
forth = 0;
if((last == 'f' && second == 'i' && third == 'g' && forth == '.')
|| (last == 'g' && ((second == 'n' && third == 'p' && forth == '.') || (second == 'p' && third == 'j' && forth == '.')))
|| (last == 'p' && (second == 'm' && third == 'b' && forth == '.'))
|| (last == 's' && ((second == 'j' && third == '.')|| (second == 's' && third == 'c' && forth == '.')))
|| (last == 'o' && (second == 'c' && third == 'i'))) return true;
改动后的代码,更加像低级语言在写代码,呵呵,不过效率的确提高了一些,这个时候提高就不是太明显了,只是减少substring创创建中间对象生成时间,能到这一步,我想很少有人再去想了,但是但是代码洁癖超级高的话,还会去想,五个字符,最坏情况要匹配5次才能找到自己想要的入口,有没有办法一次性找到,还有,找到后通过路径直接匹配到内容,回到那个图上,看到很像图形结构
首先考虑入口应该如何处理?看到入口全是字母,这些字母的ascii都是数据0-127的,所以我们想直接用字母的ascii作为下标,我们姑且浪费点空间,创建一个长度为128的数组,使用结束字母ascii作为入口位置;
再考虑,进入后该如何算?我们就想通过图上的路由,最终可以找到最后一个字符的就是成立的,此时设计到子节点的查找,理论上这样是最快的,但是,实现起来每一层需要循环到自己要的那个路由,循环体本身对CPU的开销也是有的,而且要构造对象和指针来实现,访问数据需要通过间接访问,理论上的最优化,并不是我们想要的最优,但是我们的优化到此结束了吗?不是,算法行不通,我更喜欢钻牛角尖了,呵呵,
怎么解决第二步无法完成的情况呢?我考虑到虽然不能按照图的结构完成,那么我发现开始字符都是 "."将它抛开算,如果入参不是这样直接错误,另外,剩余的字符,就只有1-2个字符,而且这个字符的ascii都是数据0-127的,我惊喜了,0-127就是在byte的范围内,我可以组织成任何我想要的内容,我此时将两个字符,按照byte拼接,就可以拼接为2个byte位的数字,也就是short int 类型,因为java在JVM内核实现中其实在局部变量中都是一样大的,所以我们就直接用int了,如果int和int匹配就是一个compare,而不是按照每个字符去compare了;
再发现,上面的图结构中,按照路由向下走,每个入口下面最多2个可匹配的内容,所以我们就定死一个结构就是一个入口下两个int,默认为-1,如下(我这里定义的是内部类,写成static是为了静态方法调用):
static class TempNode {
int c1 = -1;
int c2 = -1;
}OK,开始尝试,首先我们初始化我们需要进行对比的信息,就像编译时完成一些东西一样:
我们首先初始化一个128长度的数组:
private static TempNode[] tempNode1 = new TempNode[128];
private static void addNode(char []chars) {
int b = (int)chars[0];
TempNode node = tempNode1[b];
if(node == null) {
node = new TempNode();
tempNode1[b] = node;
}
int size = chars.length;
int tmp = 0;
if(size == 2) {
tmp = (int)(chars[1]);
}else if(size == 3) {
tmp = (int)(chars[1] << 8 | chars[2]);
}
if(node.c1 == -1) node.c1 = tmp;
else node.c2 = tmp;
}
static {
addNode(new char[] {'f' , 'i' , 'g'});
addNode(new char[] {'g' , 'n' , 'p'});
addNode(new char[] {'g' , 'p' , 'j'});
addNode(new char[] {'p' , 'm' , 'b'});
addNode(new char[] {'s' , 'j'});
addNode(new char[] {'s' , 's' , 'c'});
addNode(new char[] {'o' , 'c' , 'i'});
}这部分访问这个类的时候,就会被初始化掉,初始化的目的就是为了可以被反复使用,而没有将这部分运算时间抛开掉了;此时怎么运算呢?代码描述如下:
1、取出访问字符最后一个字母,根据ascii到tempNode1取出对象,如果对象为空,则就没有任何匹配的,直接返回错误。
2、倒转访问字符,如果长度超过3个,且第三个字符不是“.”,则看第四个字符是不是“.”。
3、上述成立后,根据字符长度拼接处对应的int数据,与取出的TempNode对象中的两个int值进行匹配,得到boolean类型的值返回。
实际代码如下:
private static boolean testServletPath(String servletPath) {
int length = servletPath.length();
char last = servletPath.charAt(length - 1);
TempNode node = tempNode1[(int)last];
if(node == null) return false;
char second = servletPath.charAt(length - 2);
char third = servletPath.charAt(length - 3);
char forth;
int tmp = -1;
if(length > 3 && third != '.') {
forth = servletPath.charAt(length - 4);
if(forth != '.') return false;
tmp = (int)(second << 8 | third);
}else if(third != '.') {
return false;
}else {
forth = 0;
tmp = second;
}
return tmp == node.c1 || tmp == node.c2;
}我想这已经快到极点了,可以看到上面有进行 ‘.’ 的compare,也就是多进行操作了,那么是否可以直接将这个字符也放入到int中呢,int本身还有2个byte的空位,是的,可以这样做,但是会增加一次位偏移操作,所以和多一次判定,所以总体的效率会看不出多大的区别,但是也是可以那样做的,因为你会发现compare操作会做2次。
也就是只要能挖,在这种代码中能挖出很多宝贝,在高并发的应用系统中,如果在极高并发的代码段,尤其是无论任何程序都会经过的代码段,而且经过多次的那种,那么,这种优化就会产生总体上的提升。
最后,我们看看代码片段2,其实和片段1类似,只不过第一步是考虑endWith,第二个是contains,contarins其实有可能会更加慢,因为会在内部在到相应的字符做一次匹配;就像对比MSIE这个字符串,如果文本中出现多次M开头就又要开始匹配,这里将同一个文本和8种情况对比是很痛苦的事情,其实我们完全可以将上面8个字符串的第一个字母取出来,后面字符串作为byte位,最后组成一个long数据,代表一个数字,放在一个小数组中(此时就是用起始字符作为数组下标了);然后,在使用传入字符串时,每位进行位偏移,将数字和对应下标下的数组看看是否一致,一致就直接返回那个下标记录下的常量,若不是就继续向后了,也就是一遍扫描下来8个字符串可以对比到,而且每次内部对比的时候,就是一个简单的数字对比而已,这就是一种优化。
不论不论怎么说,优化还是归结到能不做的就不做,能少做的就少做,能只做一次就只做一次!















 3513
3513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









