







一、进程表示
Linux内核涉及进程和程序的所有算法都围绕一个名为task_struct的数据结构建立,该结构定义在include/sched.h中。这是系统中主要的一个结构。在阐述调度器的实现之前,了解一下Linux管理进程的方式很有必要。
task_struct包含很多成员,将进程与各个内核子系统联系起来,会逐一讨论。
task_struct定义如下:
include/sched.h



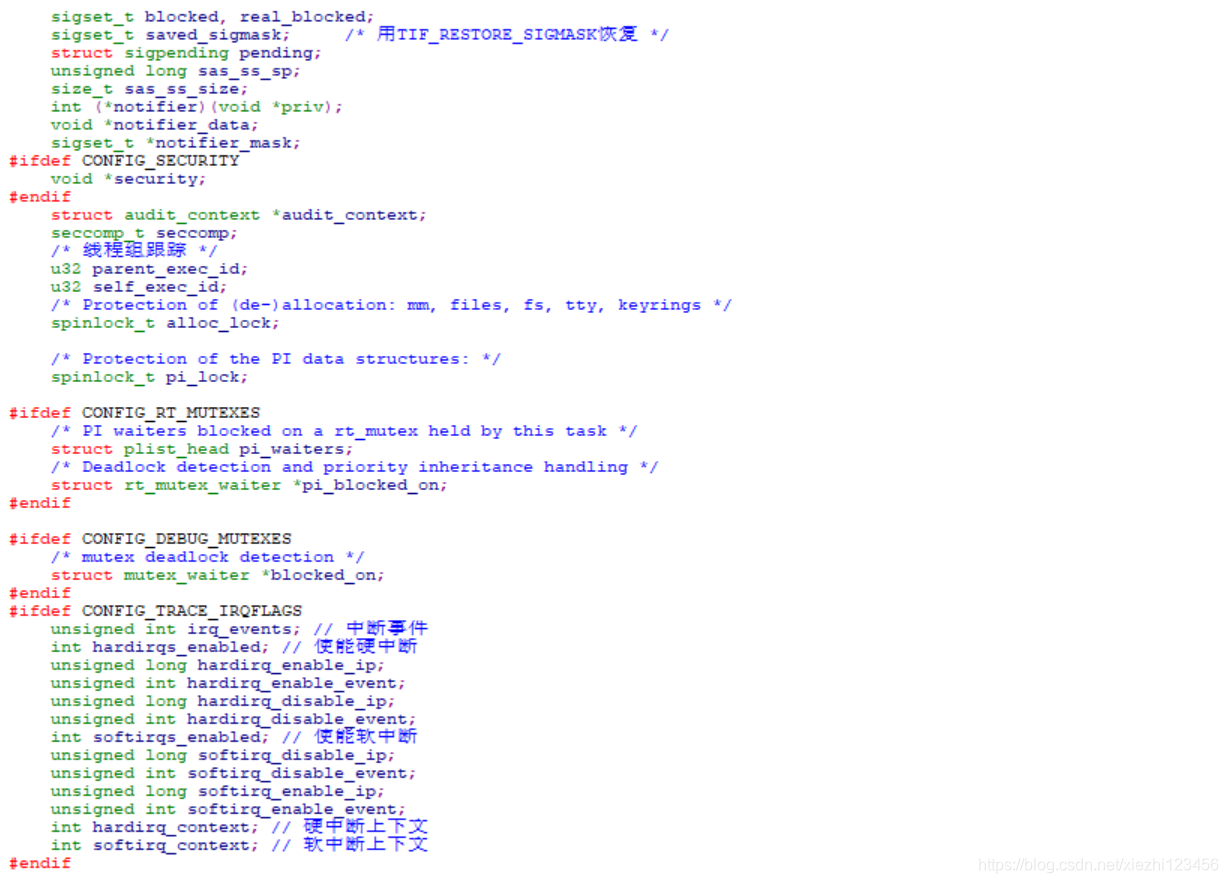


该结构的内容可以分解为各个部分,每个部分表示进程的一个特定方面。
进程和执行信息,如待决信号、使用的二进制格式(和其他系统二进制格式的任何仿真信息)、进程ID号(pid)、到父进程及其他有关进程的指针、优先级和程序执行有关的时间信息(例如CPU时间)。
有关已经分配的虚拟内存的信息。
进程身份凭据,如用户ID、组ID以及权限(权限是授予进程的特定许可。它们使得进程可以执行某些本来只能由root进程执行的操作)等。可使用系统调用查询或修改这些数据。
使用的文件包含程序代码的二进制文件,以及进程所处理的所有文件的文件系统信息,这些都必须保存下来。
线程信息记录该进程特定于CPU的运行时间数据(该结构的其余字段与所使用的硬件无关)。
在与其他应用程序协作时所需的进程之间通信有关的信息。
该进程所用的信号处理程序,用于响应到来的信号。
介绍task_struct中对进程管理的实现特别重要的一些成员。
state指定进程的当前状态,可使用如下值(这些是预处理器常数,定义在<linux/sched.h>中)
TASK_RUNNING:进程处于可运行状态。这并不意味着已经实际分配了CPU。进程可能会一直等到调度器选中它。该状态确保进程可以立即运行,而无需等待外部事件。
TASK_INTERRUPTIBLE:针对等待某事件或其他资源的睡眠进程设置的。在内核发送信号给该进程表明事件已经发生时,进程状态变为TASK_RUNNING,它只要调度器选中该进程即可恢复执行。
TASK_UNINTERRUPTIBLE:用于因内核指示而停用的睡眠进程。它们不能由外部信号唤醒,只能由内核亲自唤醒。
TASK_STOPPED 表示进程特意停止运行,例如,由调试器暂停。
TASK_TRACED 本来不是进程状态,用于从停止的进程中,将当前被调试的那些(使用ptrace机制)与常规的进程区分开来。
下列常量既可以用于struct task_struct的进程状态字段,也可以用于exit_state字段,后者明确地用于退出进程。
EXIT_ZOMBIE:僵尸状态。
EXIT_DEAD:指wait系统调用已经发出,而进程完全从系统移除之前的状态。只有多个线程对同一个进程发出wait系统调用时,该状态才有意义。
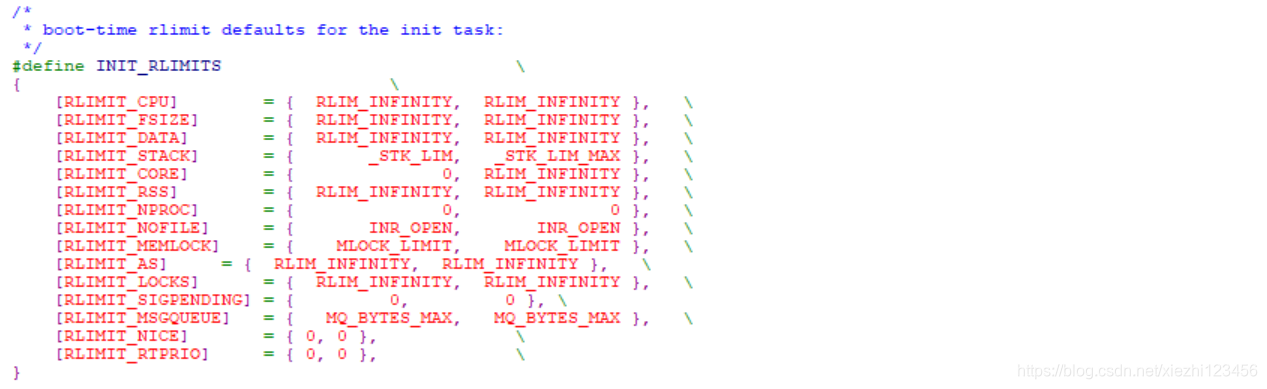
Linux提供资源限制(resource limit,rlimit)机制,对进程使用系统资源施加某些限制。该机制利用task_struct中的rlim数组,数组项类型为struct rlimit。
<linux/resource.h>

上述定义设计得通用,可以用于许多不同的资源限制。
系统调用 setrlimit 来增减当前限制,但不能超出rlim_max指定的值。getrlimits用于检查当前限制。
rlim数组中的位置标识了受限制资源的类型,这也是内核需要定义预处理器常数,将资源与位置关联起来的原因。表2-1列出可能的常数及其含义。

备注:由于Linux试图建立与特定的本地UNIX系统之间的二进制兼容性,因此不同体系结构的数值可能不同。
因为限制涉及内核的各个部分,内核必须确认子系统遵守了相应限制。
如果某一类资源没有使用限制,则将rlim_max设置为 RLIM_INFINITY 。例外情况包括下面所列举的。
打开文件的数目( RLIMIT_NOFILE ,默认限制在1 024)。
每用户的最大进程数( RLIMIT_NPROC ),定义为 max_threads/2 。 max_threads 是一个全局变量,指定在把八分之一可用内存用于管理线程信息的情况下,可以创建的线程数目。在计算时,提前给定20个线程的最小可能内存用量。
init 进程的限制在系统启动时即生效,定义在 include/asm-generic-resource.h 中的INIT_RLIMITS 。
2.6.24版本的内核在proc文件系统中对每个进程都包含对应的一个文件,可以查看当前的rlimit值:

1、进程类型
UNIX进程包括:由二进制代码组成的应用程序、单线程、分配给应用程序的一组资源(如内存、文件等)。新进程使用fork和exec系统调用产生的。
fork生成当前进程的一个相同副本,该副本称之为子进程。原进程的所有资源都以适当的方式复制到子进程,该系统调用之后,原来的进程有两个独立的实例。这两个实例的联系包括:同一组打开文件、同样的工作目录、内存中同样的数据(两个进程各有一份副本),等等。此外二者别无关联。
exec从一个可执行的二进制文件加载另一个应用程序,来代替当前运行的进程。加载一个新程序。因为exec并不创建新进程,所以必须首先使用fork复制一个旧的程序,然后调用exec在系统上创建另一个应用程序。
Linux还提供clone系统调用。clone的工作原理基本上与fork相同,但新进程不是独立于父进程的,而可以与其共享某些资源。可以指定需要共享和复制的资源种类,例如,父进程的内存数据、打开文件或安装的信号处理程序。
clone用于实现线程,但仅仅该系统调用不足以做到这一点,还需要用户空间库才能提供完整的实现。
2、命名空间
命名空间提供虚拟化的一种轻量级形式,使得可以从不同的方面来查看运行系统的全局属性。
1)概念
传统上,在Linux以及其他衍生的UNIX变体中,许多资源是全局管理的。例如,系统中的所有进程是通过PID标识的,这意味着内核必须管理一个全局的PID列表。而且,所有调用者通过uname系统调用返回的系统相关信息(包括系统名称和有关内核的一些信息)都是相同的。用户ID的管理方式类似,即各个用户是通过一个全局唯一的UID号标识。
全局ID使得内核可以有选择地允许或拒绝某些特权。虽然UID为0的root用户基本上允许做任何事,但其他用户ID则会受到限制。例如UID为n的用户,不允许杀死属于用户m的进程(m≠ n)。但这不能防止用户看到彼此,即用户n可以看到另一个用户m也在计算机上活动。只要用户只能操纵他们自己的进程,这就没什么问题,因为没有理由不允许用户看到其他用户的进程。
但有些情况下,这种效果可能是不想要的。如果提供Web主机的供应商打算向用户提供Linux计算机的全部访问权限,包括root权限在内。传统上,这需要为每个用户准备一台计算机,代价太高。使用KVM或VMWare提供的虚拟化环境是一种解决问题的方法,但资源分配做得不是非常好。计算机的各个用户都需要一个独立的内核,以及一份完全安装好的配套的用户层应用。
命名空间提供了一种不同的解决方案,所需资源较少。在虚拟化的系统中,一台物理计算机可以运行多个内核,可能是并行的多个不同的操作系统。而命名空间则只使用一个内核在一台物理计算机上运作,前述的所有全局资源都通过命名空间抽象起来。这使得可以将一组进程放置到容器中,各个容器彼此隔离。隔离可以使容器的成员与其他容器毫无关系。但也可以通过允许容器进行一定的共享,来降低容器之间的分隔。例如,容器可以设置为使用自身的PID集合,但仍然与其他容器共享部分文件系统。
本质上,命名空间建立了系统的不同视图。此前的每一项全局资源都必须包装到容器数据结构中,只有资源和包含资源的命名空间构成的二元组是全局唯一的。虽然在给定容器内部资源是自足的,但无法提供在容器外部具有唯一性的ID。
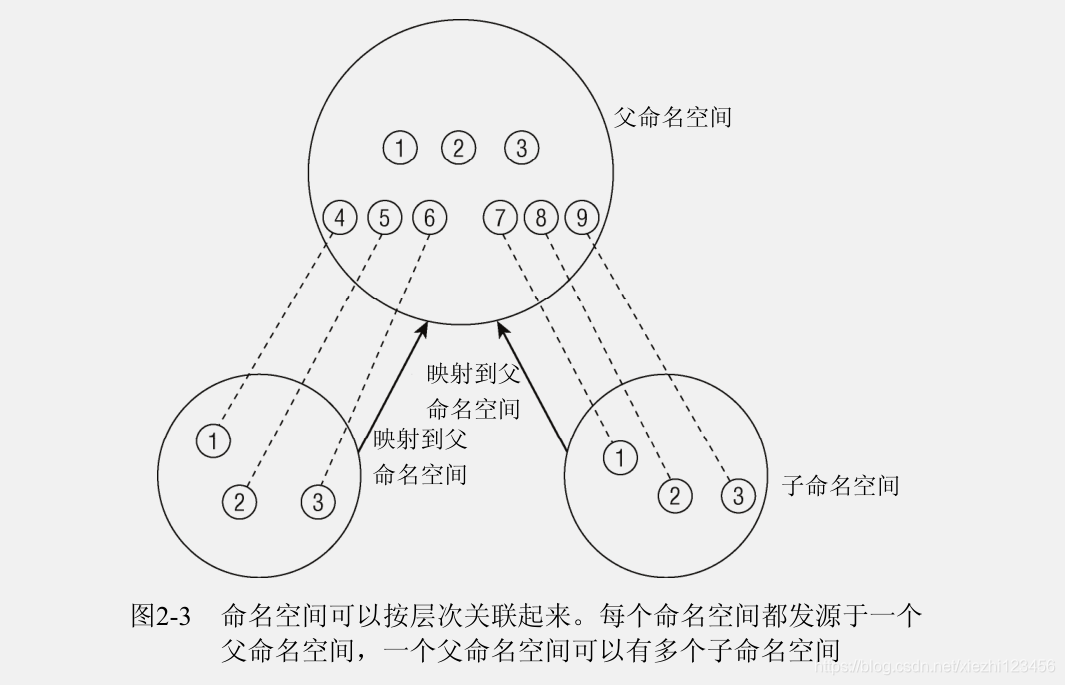
考虑系统上有3个不同命名空间的情况。命名空间可以组织为层次,在这里讨论这种情况。一个命名空间是父命名空间,衍生两个子命名空间。假定容器用于虚拟主机配置中,其中的每个容器必须看起来像是单独的一台Linux计算机。因此其中每一个都有自身的 init 进程,PID为0,其他进程的PID以递增次序分配。两个子命名空间都有PID为0的 init 进程,以及PID分别为2和3的两个进程。由于相同的PID在系统中出现多次,PID号不是全局唯一的。
虽然子容器不了解系统中的其他容器,但父容器知道子命名空间的存在,也可以看到其中执行的所有进程。图中子容器的进程映射到父容器中,PID为4到9。尽管系统上有9个进程,但却需要15个PID来表示,因为一个进程可以关联到多个PID。至于哪个PID是“正确”的,则依赖于具体的上下文。
如果命名空间包含的是比较简单的量,也可以是非层次的,例如UTS(UNIX Timesharing System: UNIX分时系统)命名空间。在这种情况下,父子命名空间之间没有联系。
注意:Linux系统对简单形式的命名空间的支持已有一段时间,主要是chroot系统调用。该方法可以将进程限制到文件系统的某一部分,是一种简单的命名空间机制。但真正的命名空间能够控制的功能远远超过文件系统视图。
新的命名空间用如下两种方法创建。
(1)在用 fork 或 clone 系统调用创建新进程时,有特定的选项可以控制是与父进程共享命名空间,还是建立新的命名空间。
(2)unshare 系统调用将进程的某些部分从父进程分离,其中也包括命名空间。
在进程已经使用上述的两种机制之一从父进程命名空间分离后,从该进程的角度来看,改变全局属性不会传播到父进程命名空间,而父进程的修改也不会传播到子进程,至少对于简单的量是这样。对于文件系统来说,情况比较复杂,其中共享机制非常强大,带来了大量的可能性。
2)实现
命名空间的实现需要两个部分:每个子系统的命名空间结构,将此前所有的全局组件包装到命名空间中;将给定进程关联到所属各个命名空间的机制。图2-4说明具体情形。
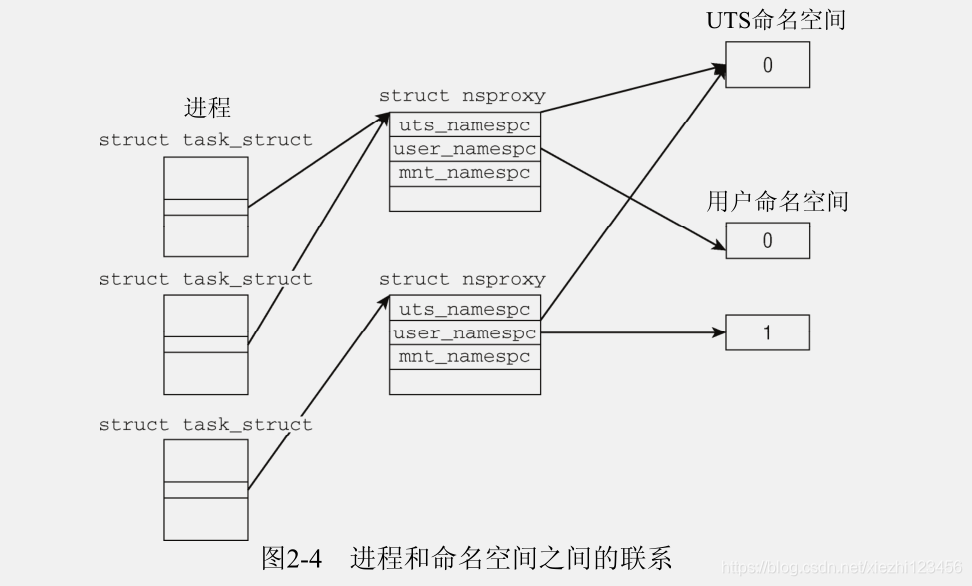
子系统此前的全局属性现在封装到命名空间中,每个进程关联到一个选定的命名空间。每个可以感知命名空间的内核子系统都必须提供一个数据结构,将所有通过命名空间形式提供的对象集中起来。 struct nsproxy 用于汇集指向特定于子系统的命名空间包装器的指针:
<linux/nsproxy.h>

当前内核的以下范围可以感知到命名空间。
UTS命名空间包含运行内核的名称、版本、底层体系结构类型等信息。UTS是UNIX Timesharing System(UNIX分时系统)的简称。
保存在 struct ipc_namespace 中的所有与进程间通信(IPC)有关的信息。
已经装载的文件系统的视图,在 struct mnt_namespace 中给出。
有关进程ID的信息,由 struct pid_namespace 提供。
struct user_namespace 保存的用于限制每个用户资源使用的信息。
struct net_ns 包含所有网络相关的命名空间参数。
主要讲解UTS和用户命名空间。在创建新进程时可使用 fork 建立一个新的命名空间,必须提供控制该行为的适当的标志。每个命名空间都有一个对应的标志:
<linux/sched.h>

每个进程都关联到自身的命名空间视图:
<linux/sched.h>

因为使用了指针,多个进程可以共享一组子命名空间。这样,修改给定的命名空间,对所有属于该命名空间的进程都可见。
注意,对命名空间的支持必须在编译时启用,而且必须逐一指定需要支持的命名空间。但对命名空间的一般性支持总是会编译到内核中。 这使得内核不管有无命名空间,都不必使用不同的代码。除非指定不同的选项,否则每个进程都会关联到一个默认命名空间,这样可感知命名空间的代码总是可以使用。但如果内核编译时没有指定对具体命名空间的支持,默认命名空间的作用则类似于不启用命名空间,所有的属性都相当于全局的。
init_nsproxy 定义初始的全局命名空间,其中维护了指向各子系统初始的命名空间对象的指针:
<kernel/nsproxy.c>
![]()
<linux/init_task.h>

1)UTS(UNIX分时系统)命名空间
UTS命名空间几乎不需要特别的处理,因为它只需要简单量,没有层次组织。所有相关信息都汇集到下列结构的一个实例中:
<linux/utsname.h>

使用 uname 工具可以取得这些属性的当前值,也可以在 /proc/sys/kernel/ 中看到:

初始设置保存在 init_uts_ns 中:
init/version.c

相关的预处理器常数在内核中各处定义。
注意,UTS结构的某些部分不能修改。例如,把 sysname 换成 Linux 以外的其他值没有意义,但改变机器名是可以的。
内核如何创建一个新的UTS命名空间?这属于 copy_utsname 函数的职责。在某个进程调用fork 并通过 CLONE_NEWUTS 标志指定创建新的UTS命名空间时,则调用该函数。这种情况下,会生成先前的 uts_namespace 实例的一份副本,当前进程的 nsproxy 实例内部的指针会指向新的副本。由于在读取或设置UTS属性值时,内核会保证总是操作特定于当前进程的 uts_namespace 实例,在当前进程修改UTS属性不会反映到父进程,而父进程的修改也不会传播到子进程。

2)用户命名空间
用户命名空间在要求创建新的用户命名空间时,则生成当前用户命名空间的一份副本,并关联到当前进程的 nsproxy 实例。
<linux/user_namespace.h>

对命名空间中的每个用户,都有一个 struct user_struct 的实例负责记录其资源消耗,各个实例可通过散列表 uidhash_table 访问。
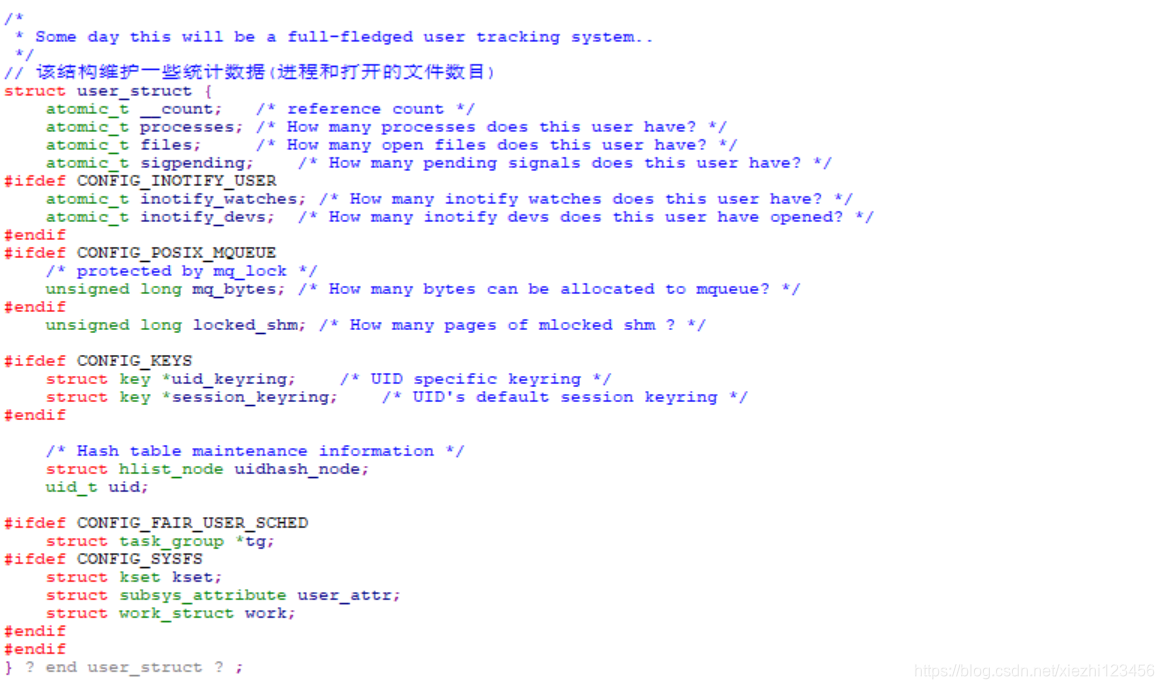
每个用户命名空间对其用户资源使用的统计,与其他命名空间完全无关,对root用户的统计也是如此。这是因为在克隆一个用户命名空间时,为当前用户和root都创建了新的 user_struct 实例:
kernel/user_namespace.c

alloc_uid 是一个辅助函数,对当前命名空间中给定UID的一个用户,如果该用户没有对应的user_struct 实例,则分配一个新的实例。在为root和当前用户分别设置了 user_struct 实例后,switch_uid 确保从现在开始将新的 user_struct 实例用于资源统计。实质上就是将 struct task_struct 的 user 成员指向新的 user_struct 实例。
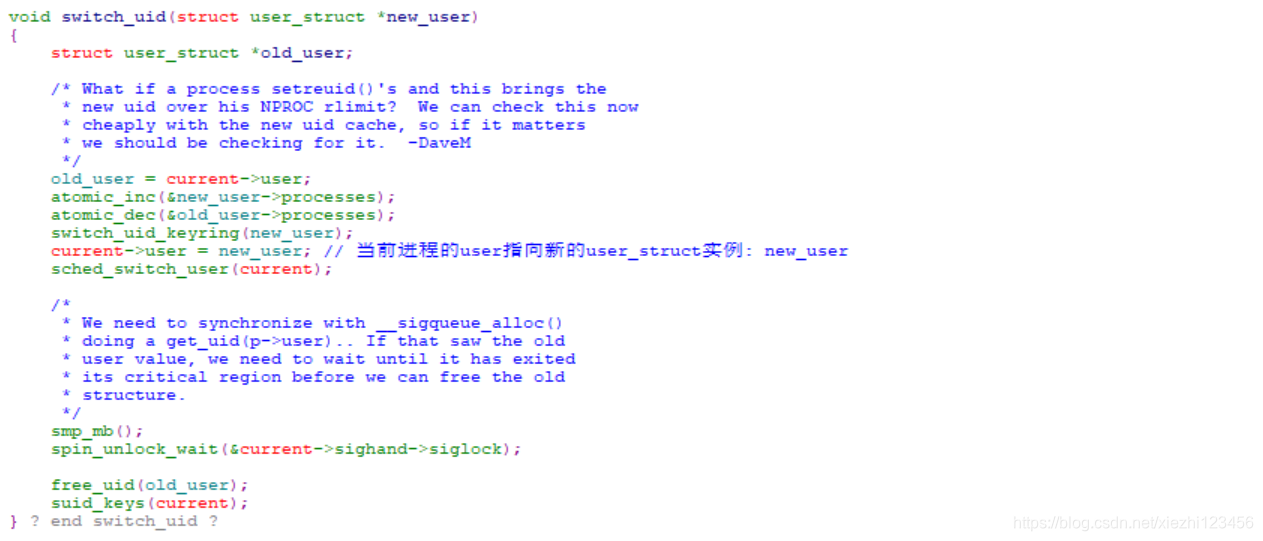
注意:如果内核编译时未指定支持用户命名空间,那么复制用户命名空间实际上是空操作,即总是会使用默认的命名空间。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









