






一、为什么要自定义函数?难道内置函数不香吗?
作为一名资深 Hive 搬砖工,我曾经天真地以为内置函数就是全世界:ABS 求绝对值、COUNT 数星星、CONCAT 拼字符串... 直到有一天产品经理甩来需求:"把用户昵称首字母大写,其他小写,还要兼容 emoji!"
我自信满满敲下SELECT UPPER(name) FROM users,结果得到一堆全大写的 "ZHANGSAN"。产品经理嘴角扬起神秘微笑:"这就是你说的首字母大写?" 那一刻我明白:内置函数就像超市里的速食面,能填饱肚子但永远吃不出妈妈的味道。ε(┬┬﹏┬┬)3
Hive 自定义函数(UDF)就是程序员的 "瑞士军刀",当内置函数不够用,我们就自己造轮子。先记住这三兄弟:
- UDF(User Defined Function):一对一的翻译官,输入一个值输出一个值,比如把 "lisi" 变成 "LISI",把-1变成1
- UDAF(User Defined Aggregation Function):聚众开会做总结,输入一堆值输出一个结果,比如求平均数,求和。
- UDTF(User Defined Table-Generating Function):一变多的魔术表演,输入一行输出多行,比如拆分 JSON 数组,explode展开函数
二、UDF 实战:教 Hive 把 "zhangsan" 变成 "Zhangsan"
1. 搭建你的Maven 项目
首先打开 IDEA,像搭积木一样创建 Maven 项目
然后在 pom.xml 里加入依赖:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-common -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.3.1</version>
</dependency>2. 编写你的第一个 UDF:首字母大写转换器
新建一个 Java 类,比如FirstUpper,记住必须继承GenericUDF,然后重写他的方法,这是 Hive 大佬们定的规矩:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class FirstUpper extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
if (objectInspectors.length != 1) {
// 说明参数的数量不对
throw new UDFArgumentException("参数数量错误");
}
// 返回值类型检查
return PrimitiveObjectInspectorFactory.javaStringObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
// 获取参数的值
String inputString = deferredObjects[0].get().toString();
if (inputString != null) {//逻辑部分,截取首字母
String upperFirst = inputString.substring(0,1).toUpperCase();
return upperFirst + inputString.substring(1);
}
return null;
}
@Override
public String getDisplayString(String[] strings) {
return "首字母大写";
//getDisplayString方法的主要目的是为自定义函数提供用户友好的字符串表示,用于日志、执行计划(EXPLAIN输出)或错误信息中,以提高可读性和调试效率
}
}3. 把代码打包成 "魔法药水"(jar 包)
点击 IDEA 的 Maven 工具栏,找到package命令,成功后会在target目录下生成HiveFunctionDemo1-1.0-SNAPSHOT.jar。这个 jar 包就像你炼制好的魔法药水,需要传给 Hive 服用。
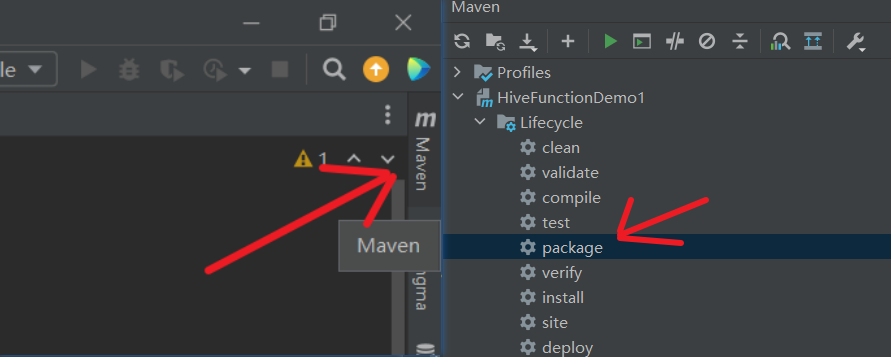
4. 让 Hive 加载自定义的函数
方式一:临时加载(一次性筷子,用完就扔)
-- 先把jar包放到Hive的lib目录下,比如/opt/hive/lib/
hive> add jar /opt/hive/lib/HiveFunctionDemo1-1.0-SNAPSHOT.jar;
-- 创建临时函数,注意temporary关键字
hive> create temporary function first_upper as 'com.bigdata.FirstUpper';
//这里单引号里的路径应与Java类的路径一致
-- 测试一下,输入"zhang"应该输出"Zhang"
hive> select first_upper('zhang');单引号里的Java类路径可以参考以下步骤:

方式二:开机自动加载(居家常用工具)
- 创建初始化文件:
vi $HIVE_HOME/conf/hive-init
#$HIVE_HOME为自己的Hive安装目录- 在文件中写入加载命令:
add jar /opt/hive/lib/HiveFunctionDemo1-1.0-SNAPSHOT.jar;
create temporary function 函数名 as 'com.bigdata.FirstLetterUpper';- 启动 Hive 时指定初始化文件:
hive -i $HIVE_HOME/conf/hive-init以上,创建的都是临时函数,当窗口关闭就消失了,函数失效 ,假如我自定义的函数每天都需要时会用,但是我使用的是远程连接,如何配置?(⊙—⊙)?
方式三:永久加载(传家宝级别)
--需要将jar包放置在hdfs存储路径下才行,不然会报错。
hdfs dfs -put /opt/installs/hive/lib/HiveFunctionDemo1-1.0-SNAPSHOT.jar /home
-- 创建永久函数,不加temporary
hive> create function first_upper as 'com.bigdata.FirstUpper' using jar 'hdfs://machine01:9820/home/HiveFunctionDemo1-1.0-SNAPSHOT.jar';
--注意不要加temporary
--这里单引号里的hdfs地址和自己的保持一致三、UDAF 和 UDTF:进阶玩家的秘密武器
1. UDAF:聚众开会的统计大师
想象一下你要计算每个部门的平均工资,内置的 AVG 函数就是一个 UDAF。如果需要自定义复杂统计(比如求中位数),就需要自己写 UDAF。
UDAF 的核心是 "累加器" 模式:
init():初始化累加器iterate():每次处理一条数据,更新累加器merge():合并多个累加器(分布式计算时有用)terminate():返回最终结果
2. UDTF:一变多的魔术大师
比如你有一个 JSON 数组字段tags=["java","hadoop","spark"],想拆分成多行,就可以用lateral view explode(tags) as tag。这时候explode就是一个 UDTF。
自定义 UDTF 需要继承GenericUDTF,实现initialize()、process()和close()方法,其中process()负责输出多行数据。
四、实战翻车现场:这些坑我替你踩过了
ClassNotFoundException:
Error: java.lang.ClassNotFoundException: com.bigdata.FirstUpper原因:Hive 找不到你的类,可能是 jar 包没加载,或者类路径写错了。
解决方案:用show functions确认函数存在,检查类名和包名是否正确。
UDFArgumentException
UDFArgumentException: Invalid parameter type原因:你的函数要求字符串参数,却传了数字。
解决方案:在initialize()方法中增加参数类型检查。
永久函数跨会话失效:
原因:你以为创建了永久函数,但 jar 包只在当前会话加载。
解决方案:创建永久函数时一定要用using jar指定 HDFS 路径。
五、面试装 X 指南:如何优雅回答自定义函数问题
面试官:"你在项目中自定义过 Hive 函数吗?"
普通回答:"用过,写过一个首字母大写的 UDF。"
大佬回答:" 哦,你说 UDF 啊,我们项目里用得挺多的。比如有个需求是解析嵌套 JSON,内置函数搞不定,我就写了个 UDTF,用递归解析嵌套结构,然后通过forward()方法输出多行数据。当时遇到一个性能问题,发现频繁创建 JSON 解析器很耗资源,后来改成单例模式,性能提升了 30%。对了,你知道 UDAF 和 UDTF 在底层实现上的区别吗?UDAF 需要处理分布式环境下的累加器合并,而 UDTF..."
记住这个套路:先讲需求背景,再讲技术方案,最后抛出更深层次的问题,把面试官绕晕。
六、结语:从 "调包侠" 到 "造包侠" 的蜕变
自定义函数是 Hive 开发的进阶之路,当你能熟练编写 UDF/UDAF/UDTF 时,恭喜你已经从 "调包侠" 升级为 "造包侠"。下次产品经理再提奇葩需求,你可以自信地说:"这个简单,我写个 UDF 搞定!"
最后送大家一句话:代码是死的,人是活的。内置函数不够用?那就自己创造!毕竟程序员的终极浪漫,就是用代码改变世界(哪怕只是让首字母大写)。
彩蛋:输入出生年月日计算年龄的UDF(面试常考):
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
import java.time.LocalDate;
import java.time.format.DateTimeFormatter;
// 彩蛋:输入出生年月日计算年龄的UDF(面试常考)
public class Age extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {
if(objectInspectors.length != 1){
throw new UDFArgumentException("参数数量错误");
}
ObjectInspector inspector = objectInspectors[0];
if (!(inspector instanceof StringObjectInspector)) {
// 检查参数是否为字符串
throw new UDFArgumentException("参数的类型错误");
}
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] deferredObjects) throws HiveException {
String inputBirthday = deferredObjects[0].get().toString();
DateTimeFormatter formatter = DateTimeFormatter.ofPattern("yyyy-MM-dd");
try {
LocalDate birthday = LocalDate.parse(inputBirthday, formatter);
int birthdayYear = birthday.getYear();
int birthdayMonth = birthday.getMonthValue();
int birthdayDay = birthday.getDayOfMonth();
LocalDate now = LocalDate.now();
int nowYear = now.getYear();
int nowMonth = now.getMonthValue();
int nowDay = now.getDayOfMonth();
if(nowMonth>birthdayMonth){
return nowYear-birthdayYear;
}else if(nowMonth==birthdayMonth){
if(nowDay>=birthdayDay){
return nowYear-birthdayYear;
}else {
return nowYear-birthdayYear-1;
}
}else{
return nowYear-birthdayYear-1;
}
}catch (Exception e){
return -1;
}
}
@Override
public String getDisplayString(String[] strings) {
return null;
}
}

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









