







目录
一、操作系统概述
1、操作系统是什么
操作系统是硬件与用户及应用程序之间的媒介,向程序员提供硬件的抽象以及管理硬件资源。是一种运行在内核态的软件。
2、操作系统的核心功能
资源管理:
-
处理器(CPU)调度:CPU的管理和分配,主要指的是进程管理。通过时间片轮转、优先级调度等算法,协调多任务运行。
-
内存管理:内存的分配和管理,主要利⽤了虚拟内存的⽅式。分配与回收内存空间,支持虚拟内存扩展物理内存限制。
-
设备管理(I/O管理):对输⼊/输出设备的统⼀管理。通过驱动程序控制硬件(如打印机、磁盘),处理输入/输出操作。
-
文件系统(外存管理):管理数据存储(如NTFS、ext4),组织文件目录,控制读写权限。外存(磁盘等)的分配和管理,将外存以⽂件的形式提供出去。
用户接口:
-
图形界面(GUI):如Windows的桌面、macOS的Finder,提供直观交互。
-
命令行界面(CLI):如Linux的终端,支持脚本化操作。
系统服务:
-
多任务处理:并行或并发执行多个程序。
-
安全与权限:用户身份验证、文件访问控制(如Linux的chmod)。
-
网络通信:管理网络协议栈(TCP/IP)、防火墙配置。
3、操作系统的内核
内核是一个计算机程序,是操作系统的核心,直接与硬件交互,负责进程调度、内存管理等底层任务。
大多数操作系统将内存分成了两个区域:
- 内核空间,这个内存空间只有内核程序可以访问,可以访问所有的内存空间
- ⽤户空间,这个内存空间专⻔给应⽤程序使⽤,权限⽐较⼩,只能访问一个局部的内存空间
当程序使用用户空间时,称该程序在用户态执行;当程序使用内核空间时,程序在内核态执行。
切换机制:应用程序通过系统调用(或硬件中断、或异常),此时产生一个中断,发生中断后,CPU会保存用户态的上下文(寄存器、程序计数器等),中断当前在执行的用户程序,切换模式开始执行内核程序,内核处理完后,主动触发中断,把CPU执行权限交回用户程序,恢复上下文,继续执行原程序。
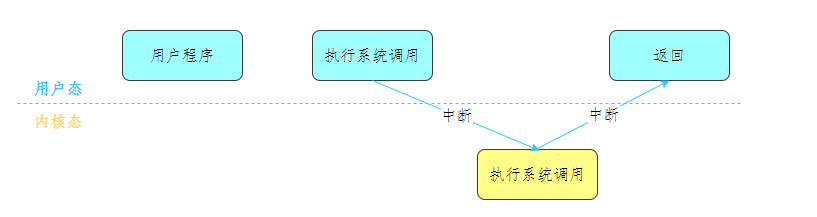
二、CPU调度
1、基本概念
1.1 并行与并发的区别
并发:一段时间内,多个任务都会被处理,但在某一刻,只有一个任务在执行。通过利用时间片的轮转实现。
并行:同一时刻,有多个任务在执行。需要多核处理器才能完成,不同程序放到不同的处理器上运行。
1.2 进程与线程的区别
进程:进程是操作系统资源分配的基本单位,是程序的一次执行实例,拥有独立的内存空间和系统资源(如CPU时间、内存、文件句柄),强调隔离性和安全性。在Java中,一个运行的JVM实例通常对应一个进程,如果在程序中启动外部程序,则会创建新的子进程,与当前JVM进程独立。进程间通信需要通过特定机制(如文件、套接字、共享内存等)实现。
线程:线程是CPU调度的基本单位,是进程内的一个执行单元,线程共享进程的资源,但拥有独立的栈和程序计数器,强调执行效率和资源共享。Java中通过Thread或线程池实现多线程。线程间可以直接共享内存,但需要处理同步问题。
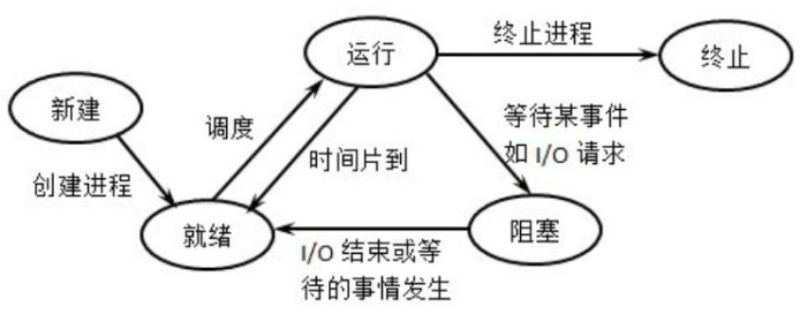
1.3 进程的状态
进程的五大基本状态:
| 状态 | 描述 |
|---|---|
| 创建 (New) | 进程正在被创建(分配资源、初始化PCB等)。 |
| 就绪 (Ready) | 进程已获得除CPU外的所有资源,等待被调度(初始化完成、时间片用完或被高优先级抢占、阻塞等待事件完成)。 |
| 运行 (Running) | 进程正在CPU上执行指令。 |
| 阻塞/等待 (Blocked/Waiting) | 进程因等待外部事件(I/O完成、信号量释放、锁等)而暂停执行,主动让出CPU。 |
| 终止 (Terminated) | 进程执行完毕或被强制终止(如崩溃、被父进程终止),资源等待回收。 |
进程的状态转换:
僵尸进程:指已完成且处于终止状态,但在进程表中任然存在的进程。一般发⽣有⽗⼦关系的进程中,⼀个⼦进程的进程描述符在⼦进程退出时不会释放,只有当⽗进程通过 wait() 或 waitpid() 获取了⼦进程信息后才会释放。如果⼦进程退出,⽽⽗进程并没有调⽤wait() 或 waitpid(),那么⼦进程的进程描述符仍然保存在系统中。
孤儿进程:⼀个⽗进程退出,⽽它的⼀个或多个⼦进程还在运⾏,那么这些⼦进程将成为孤⼉进程。孤⼉进程将被init 进程 (进程 ID 为 1 的进程) 所收养,并由 init 进程对它们完成状态收集⼯作。因为孤⼉进程会被 init 进程收养,所以孤⼉进程不会对系统造成危害。
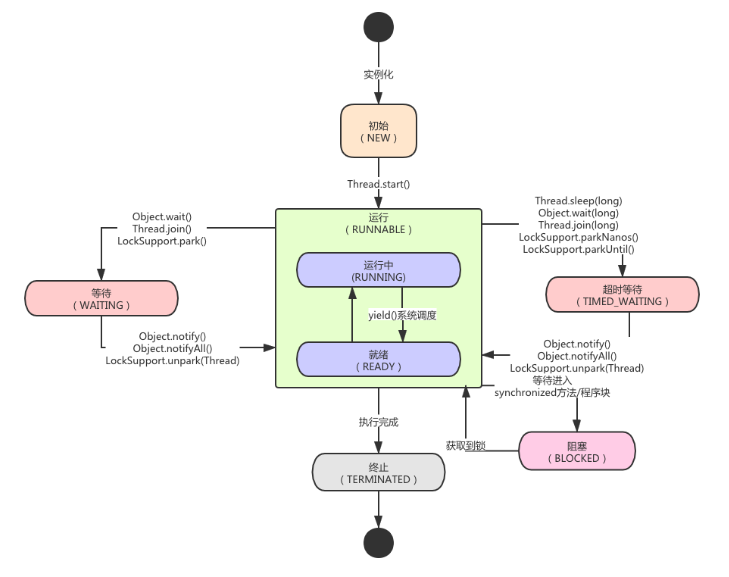
1.4 线程的状态
线程的六种状态:
| 状态 | 描述 |
|---|---|
| NEW(初始化) | 线程被创建但未启动(start()未被调用)。 |
| RUNNABLE(就绪、运行中) | 线程在JVM中可运行(可能正在执行或等待CPU时间片)。READY(就绪)、RUNNING(运行中) |
| BLOCKED(阻塞) | 线程因等待监视器锁(如synchronized)被阻塞。 |
| WAITING(等待) | 线程无限期等待其他线程触发条件(如Object.wait()或Thread.join())。 |
| TIMED_WAITING(等待超时) | 线程在有限时间内等待(如Thread.sleep(ms)或带超时的Object.wait())。 |
| TERMINATED(终止) | 线程执行完毕。 |
线程的状态转换:
1.5 进程间通信方式
管道:是内核中的一段缓存,从管道一段写入数据,另一端读取数据
# 匿名管道(Shell中使用`|`),仅用于父子进程或有亲缘关系的进程
ls | grep "txt"
# 命名管道(创建FIFO文件),通过文件系统路径标识,允许无亲缘关系的进程通信
mkfifo my_pipe消息队列:是保存在内核中的消息链表,进程通过发送/接收消息实现通信,消息附带类型标识。
操作接口如下:
msgget:创建或获取消息队列。
msgsnd:发送消息。
msgrcv:接收消息。
共享内存:多个进程映射同一块物理内存到各自的虚拟地址空间,直接读写内存实现高效通信。
操作步骤:
创建共享内存区域(
shmget)。映射到进程地址空间(
shmat)。同步访问(需结合信号量或锁)。
信号量:计数器+等待队列,用于控制多个进程对共享资源的访问(同步互斥)。保证同一时间仅一个进程使用,
操作接口:
semget:创建信号量。
semop:执行PV操作(增减信号量值)
套接字:基于网络协议(TCP/UDP)或本地域(Unix Domain Socket)实现进程间通信。
示例场景:
跨网络通信:客户端-服务器模型。
本地进程通信:Docker容器与宿主机通信。
| 方式 | 适用场景 | 优点 | 缺点 |
|---|---|---|---|
| 管道 | 父子进程简单通信 | 简单易用 | 单向、效率低(涉及内核态与用户态转换) |
| 消息队列 | 结构化数据异步传输 | 支持消息类型、解耦生产消费 | 消息大小受限 |
| 共享内存 | 高频数据交换(如音视频处理) | 速度极快(无需内核介入) | 需额外同步机制(如竞态条件) |
| 信号量 | 进程同步与互斥 | 灵活控制资源访问 | 不传递数据 |
| 套接字 | 跨网络或本地灵活通信 | 通用性强、跨平台 | 开销较大 |
| 信号 | 简单事件通知(如终止进程) | 轻量级 | 信息量小、不可靠可能丢失 |
| 文件映射 | 结合文件与内存的高效访问 | 数据持久化 | 需处理文件锁 |
| RPC | 分布式系统服务调用 | 透明调用远程函数 | 依赖网络、序列化开销 |
1.6 线程常见问题
1.6.1 死锁
死锁:在两个或者多个并发线程中,如果每个线程持有某种资源,⽽又等待其它线程释放它或它们现在保持着的资源,在未改变这种状态之前都不能向前推进,称这⼀组线程产⽣了死锁。
产生死锁的四个必要条件:
-
互斥(Mutual Exclusion):资源一次只能被一个进程独占使用(如打印机)。
-
占有并等待(Hold and Wait):进程持有至少一个资源,同时等待获取其他进程占有的资源。
-
不可抢占(No Preemption):资源只能由持有者主动释放,不能被强制剥夺。
-
循环等待(Circular Wait):存在进程间循环等待资源的链(如A等B,B等C,C等A)。
避免死锁的方法:破坏四个条件中的一个就可以
-
破坏互斥:允许资源共享(如只读文件),但多数资源无法共享(如写操作)。
-
破坏占有并等待:进程一次性申请所有所需资源(资源利用率低,易饥饿)。
-
破坏不可抢占:强制剥夺资源(需恢复现场,实现复杂)。比如:占⽤部分资源的线程进⼀步申请其他资源时,如果申请不到,可以主动释放它占有的资源
-
破坏循环等待:按顺序申请资源(如统一约定锁的获取顺序)。
1.6.2 饥饿锁
饥饿锁:线程因优先级低、调度策略不合理或锁竞争激烈,长期无法获取所需资源(如锁、CPU时间),导致任务无法推进。
饥饿锁常见原因:锁策略不公平(非公平锁、线程优先级差异);资源分配算法缺陷(CPU调度策略:短作业优先、多级反馈队列);锁嵌套与竞争(线程频繁竞争同一把锁,且持有时间长);未使用超时机制。
饥饿锁解决方案:使用公平锁、动态调整优先级(老化机制、Linux的完全公平调度器)、减小锁粒度、CAS无锁编程、超时与重试机制
1.6.3 活锁
活锁:线程不断重试失败的操作,实际未阻塞但无进展(如反复让路)
活锁常见原因:过度重试机制(重试策略未引入随机性);协作策略冲突(基于对方状态动态调整);缺乏全局协调。
活锁解决方案:引入随机性(退避算法、限制重试次数);全局协调器;优先级策略;状态共享与决策同步。
2、进程的经典调度算法
(1) 先来先服务(FCFS, First-Come-First-Served)
-
规则:按进程到达顺序分配CPU,非抢占式。
-
优点:简单,公平直观。
-
缺点:可能导致“护航效应”(短进程等待长进程),平均等待时间高。
-
适用场景:早期批处理系统。
(2) 短作业优先(SJF, Shortest Job First)
-
规则:优先执行预计运行时间最短的进程,可抢占(SJRF)或非抢占。
-
优点:最小化平均等待时间。
-
缺点:需预知作业时间,长进程可能“饥饿”。
-
应用:理论最优算法,实际需结合预测(如指数平均法)。
(3) 时间片轮转(RR, Round Robin)
-
规则:每个进程分配固定时间片(如10ms),超时后抢占并加入队列尾部。
-
优点:公平性高,响应时间可控。
-
缺点:时间片过长退化为FCFS,过短增加上下文切换开销。
-
适用场景:交互式系统(如桌面操作系统)。
(4) 优先级调度(Priority Scheduling)
-
规则:每个进程分配优先级,优先级高的优先执行,可抢占或非抢占。
-
问题:低优先级进程可能“饥饿”;优先级动态调整(如随等待时间提升)可缓解。
-
应用:实时系统(如航空控制系统)。
(5) 多级反馈队列(MLFQ, Multilevel Feedback Queue)
-
混合策略:
-
设置多个优先级队列,高优先级队列时间片短,低优先级队列时间长。
-
新进程进入最高优先级队列,若未在时间片内完成则降级。
-
定期将所有进程提升至高优先级队列,防止饥饿。
-
-
优点:兼顾响应时间和吞吐量,适应不同类型任务。
-
应用:通用操作系统(如Windows、Linux早期版本)。
(6) 完全公平调度器(Completely Fair Scheduler, CFS)
-
规则:虚拟时间(vruntime)记录进程已运行时间,选择vruntime最小的进程执行。
虚拟运行时间会根据进程的优先级(权重)进行加权调整,优先级高的进程(如实时任务)vruntime 增长更慢,从而更快被调度器选中。
调度器尝试在一个周期内让所有可运行进程至少运行一次。
所有可运行进程按 vruntime 从小到大排序,存储在一棵红黑树中,每次选择vruntime 最小的进程(即最左侧节点)执行,确保调度复杂度为O(log n)
-
应用:Linux操作系统。
3、调度性能指标
3.1 实时监控
CPU使用率:
-
用户态时间(us):CPU执行用户进程的时间占比,过高可能表示应用负载重。优化应用代码或增加CPU核心。
-
内核态时间(sy):CPU处理系统调用的时间,过高可能表明I/O或内核操作频繁。检查内核模块或I/O子系统(如磁盘/网络)。
-
等待I/O时间(wa):CPU等待磁盘I/O完成的时间,高值提示I/O瓶颈。优化磁盘I/O(如使用SSD、调整RAID)。
-
空闲时间(id):CPU未被使用的时间占比。
-
中断时间(hi/si):硬件中断(hi)和软中断(si)处理时间,高值可能由网络或外设问题引发。
平均负载(Load Average):
-
过去1、5、15分钟内的平均活跃任务数(包括运行中和不可中断的任务)。
-
理想值:不超过CPU逻辑核心数。例如,8核系统负载长期超过8需关注。
-
高平均负载但低CPU使用率:检查I/O等待(
wa)或不可中断进程(如磁盘密集型任务)
top # 综合查看CPU、内存、进程状态关键字段:
%Cpu(s):显示us/sy/ni/id/wa等时间占比。
Tasks:运行(running)、阻塞(blocked)的进程数。
Load average:平均负载。
mpstat -P ALL 1 # 显示所有CPU核心的实时数据,查看多核CPU的详细利用率运行队列长度:
- 等待CPU执行的进程/线程数量,若持续超过CPU核心数的2倍,可能表示CPU资源不足
上下文切换:
-
进程或线程切换时,CPU需要保存和恢复上下文环境,频繁切换会导致性能下降。减少线程竞争(如锁优化),调整进程优先级(
nice/renice)。 -
主动切换(cswch/s):进程主动让出CPU(如等待资源)。
-
被动切换(nvcswch/s):CPU时间片耗尽后被强制切换。
中断频率:
-
硬件中断(如网卡数据包到达)和软中断(如定时任务)的频率,高中断可能影响调度效率。
-
中断频繁:优化网卡配置(如多队列、中断绑定),检查硬件故障(如损坏的网线)
vmstat 1 # 每秒刷新一次,分析虚拟内存、CPU、进程队列及上下文切换关键字段:
r:运行队列长度。
cs:每秒上下文切换次数。
in:每秒中断次数。
pidstat -w -t -p <PID> 1 # 查看线程级上下文切换,监控特定进程的调度行为cat /proc/interrupts # 查看各CPU核心的中断分布调度延迟:
-
进程从就绪状态到实际获得CPU的时间,高延迟可能因CPU竞争激烈或调度策略不当。
perf sched record # 记录调度事件
perf sched latency # 分析调度延迟3.2 历史数据分析
sar -q # 查看历史运行队列和负载
sar -w # 查看历史上下文切换

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









