







目录
一、主从模式
MySQL的主从复制(Master-Slave Replication)是一种数据同步机制,通过将主库(Master)的数据变更复制到从库(Slave),实现读写分离、负载均衡、数据备份和高可用性。
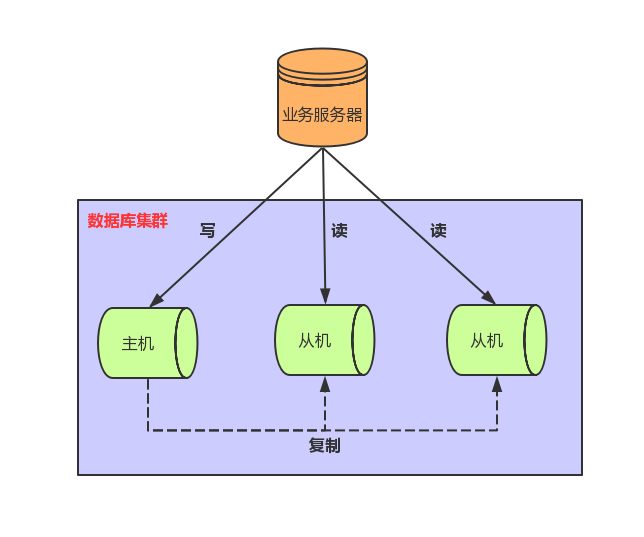
1、作用
- 高可用:实时灾备,用于故障切换
- 读扩展:读写分离,提供查询服务
- 高可用:数据备份,避免影响业务
2、主从复制流程
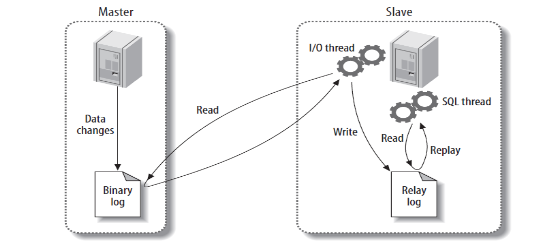
1> 主库写入事务:
-
事务提交时,主库将变更写入Binlog(需配置
log_bin=ON)。 -
Binlog根据格式(STATEMENT/ROW/MIXED)记录SQL或数据变更。
2> Binlog推送:
-
主库的
Binlog Dump线程监听到从库连接请求后,将Binlog事件推送给从库。
3> 从库接收日志:
-
从库的
I/O线程接收Binlog事件,写入本地中继日志(Relay Log)。
4> 从库重放日志:
-
从库的
SQL线程解析Relay Log,按顺序执行其中的SQL或数据变更,更新从库数据,实现数据同步。
3、关键技术
3.1 二进制日志(Binlog)
主从复制中的作用:主库将所有数据变更(如INSERT/UPDATE/DELETE)记录到二进制日志binlog中,主库通过Binlog Dump线程将Binlog内容发送给从库。
配置参数:
-
log_bin:启用Binlog(默认关闭),需重启生效。需要修改 my.cnf 或 my.ini 配置文件,在 [mysqld] 下面增加 log_bin=mysql_bin_log ,重启MySQL 服务
#log-bin=ON
#log-bin-basename=mysqlbinlog
binlog-format=ROW
log-bin=mysqlbinlog-
sync_binlog:控制Binlog刷盘策略:-
0:依赖系统刷盘,性能高但可能丢失事务。
-
1(默认):每次事务提交同步刷盘,数据最安全。
-
N:每N次事务提交刷盘,平衡性能与安全。
-
-
expire_logs_days:自动清理过期Binlog,避免磁盘占满。
binlog的三种格式区别:
| 格式 | 记录内容 | 优点 | 缺点 |
|---|---|---|---|
| STATEMENT | SQL语句原文 | 日志量小,节省空间 | 依赖上下文(如NOW()),主从不一致 |
| ROW | 每行数据的变更细节(默认格式) | 数据绝对一致,安全可靠 | 日志量大(如批量更新) |
| MIXED | 混合模式,自动选择STATEMENT/ROW | 平衡日志量和一致性 | 逻辑复杂,需谨慎配置 |
-
高频写入场景:使用ROW格式,设置
sync_binlog=1保障数据安全。 -
空间敏感场景:定期清理Binlog,或使用MIXED格式减少日志量。
常用命令:
-- Binlog状态查看
show variables like 'log_bin';
-- 查看当前Binlog文件及位置
SHOW MASTER STATUS;
-- 查看所有Binlog文件列表
SHOW BINARY LOGS;
-- 查看复制状态
SHOW SLAVE STATUS\G
-- 关键字段:
-- Slave_IO_Running: IO线程状态
-- Slave_SQL_Running: SQL线程状态
-- Seconds_Behind_Master: 复制延迟(秒)
-- 删除指定Binlog文件(谨慎操作!)
PURGE BINARY LOGS TO 'binlog.000005';
-- 删除指定时间之前的文件
purge binary logs before '2020-04-28 00:00:00';
-- 清除所有文件
reset master;
-- 查看binlog事件
show binlog events;
show binlog events in 'mysqlbinlog.000001';
其他应用:
1> 全量备份+增量恢复:通过mysqldump定期全量备份,mysqlbinlog可以做增量备份和恢复操作
# 按指定时间恢复
mysqlbinlog --start-datetime="2020-04-25 18:00:00" --stopdatetime="2020-04-26 00:00:00" mysqlbinlog.000002 | mysql -uroot -p1234
# 按事件位置号恢复
mysqlbinlog --start-position=154 --stop-position=957 mysqlbinlog.000002
| mysql -uroot -p1234转sql文件
mysqlbinlog "文件名"
mysqlbinlog "文件名" > "test.sql"2> 崩溃恢复:两阶段提交(2PC),保证binlog和redolog的一致性
Prepare阶段:InnoDB将事务的Redo Log写入日志文件,并标记为Prepare状态。
Commit阶段:
将事务的Binlog写入磁盘。
InnoDB将Redo Log标记为Commit,完成事务提交。
崩溃恢复:若MySQL崩溃,重启后会检查Binlog和Redo Log:
若Binlog存在完整事务记录,则重做Redo Log提交事务。
若Binlog无记录,则回滚事务,确保主从数据一致。
Redo Log 和 BinLog的区别:
- Redo Log是属于InnoDB引擎功能,Binlog是属于MySQL Server自带功能,并且是以二进制文件记录。
- Redo Log属于物理日志,记录该数据页更新状态内容,Binlog是逻辑日志,记录更新过程。
- Redo Log日志是循环写,日志空间大小是固定,Binlog是追加写入,写完一个写下一个,不会覆盖使用。
- Redo Log作为服务器异常宕机后事务数据自动恢复使用,Binlog可以作为主从复制和数据恢复使用。Binlog没有自动crash-safe能力。
3.2 主从复制的三种模式
| 模式 | 同步机制 | 优点 | 缺点 |
|---|---|---|---|
| 异步复制 | 主库提交事务后立即返回,不等待从库确认(默认模式)。 | 高性能,主库低延迟 | 主库宕机导致从库未同步,数据可能丢失;复制可能延迟 |
| 半同步复制 | 主库提交事务后,需等待至少一个从库确认接收Binlog事件(通过插件rpl_semi_sync_master)。 | 数据安全 | 增加事务提交延迟,网络波动可能阻塞主库。 |
| 全同步复制 | 主库提交事务后,需等待所有从库确认完成数据重放(通过组复制如MySQL Group Replication)。 | 数据强一致,高可用 | 高延迟,复杂配置,性能瓶颈明显。 |
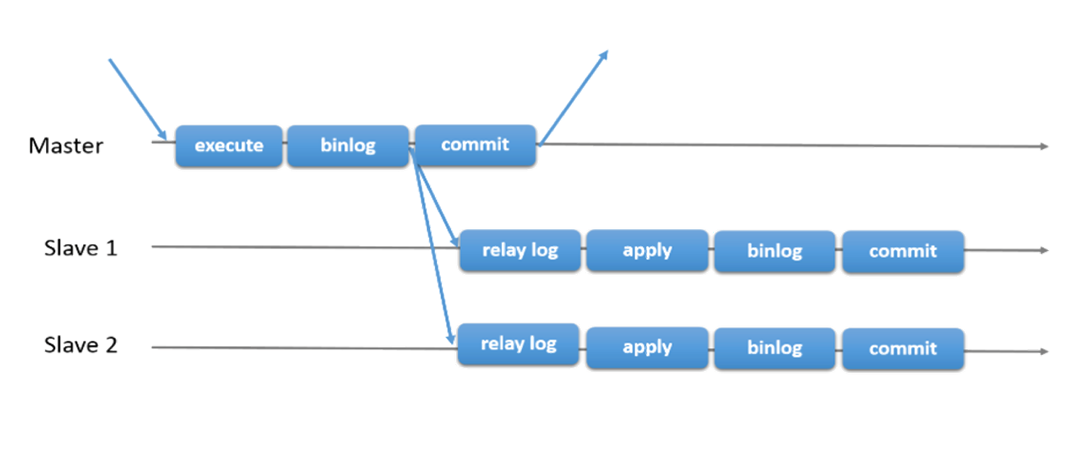
异步复制:
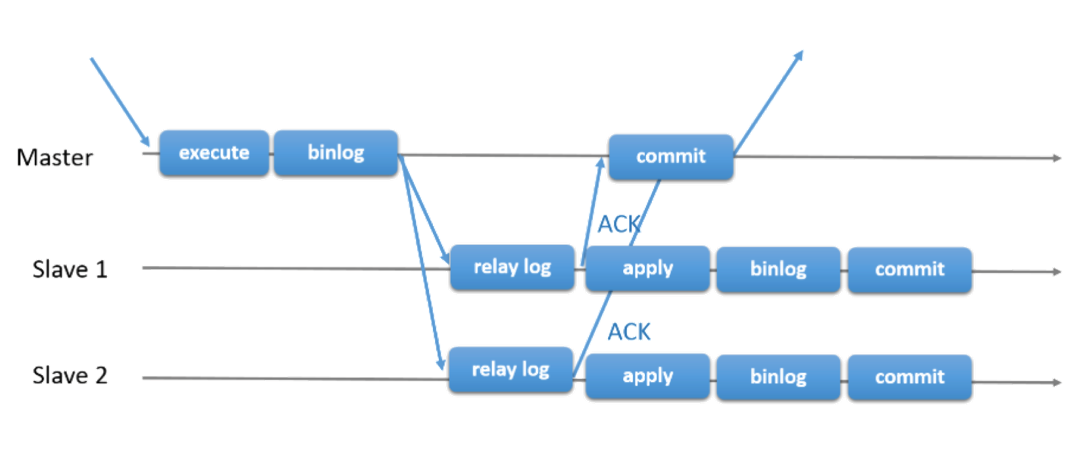
半同步复制:解决数据丢失问题
3.3 数据一致性保障
1> GTID(全局事务标识符):
-
每个事务分配唯一ID(格式:
server_uuid:事务序号),如3E11FA47-71CA-11E1-9E33-C80AA9429562:23。 -
从库通过GTID记录已执行的事务,避免重复执行或遗漏,简化故障切换。
2> 定期校验数据
-
检测工具:
-
pt-table-checksum:校验主从数据一致性。 -
pt-table-sync:修复不一致数据。
-
-
预防措施:
-
避免从库直接写入数据。
-
使用ROW格式Binlog减少不确定性函数影响。
-
3.4 主从同步延迟问题
- 从库的
SQL线程拆分为多个工作线程(slave_parallel_workers),按库或事务并行重放,减少复制延迟。
- 写后立即读
在写入数据库后,某个时间段内就去主库,之后读操作访问从库。
- 二次查询
- 根据业务特殊处理
3.5 故障恢复:主库宕机切换
-
选择一个从库提升为新主库(
STOP SLAVE; RESET SLAVE ALL;)。 -
其他从库重新指向新主库:
CHANGE MASTER TO MASTER_HOST='new_master_ip';4、典型应用场景
-
读写分离:从库处理查询,主库处理写入。
-
数据备份:从库可停机备份,不影响主库。
-
故障转移:主库宕机后,手动/自动切换从库为新主库。
二、双主模式
MySQL的双主模式(Dual-Master Replication)是一种高可用架构,允许多个主节点同时接收写操作,并通过相互复制保持数据一致性。它适用于需要高写入可用性和容灾的场景,但需特别注意数据冲突和复杂性管理。
1、作用
- 高可用:实时灾备,用于故障切换
- 负载均衡:双节点同时处理读写请求,提升整体吞吐量。可扩展为双主多从架构,进一步通过从节点分担读请求
- 数据安全:数据在两个主节点实时同步,降低数据丢失风险
- 灾备能力:支持跨机房部署,增量复制降低跨数据中心延迟
2、关键技术
2.1 双向复制机制
-
两个MySQL节点(MasterA和MasterB)互为主从,均开启二进制日志(Binlog),通过GTID(全局事务标识符)唯一标识事务。
-
每个节点既是主库(生成Binlog),又是从库(拉取对方Binlog并写入Relay Log,通过SQL线程重放)。
-
通过
server_id避免循环复制:当SQL线程发现事件的server_id与当前节点相同时,丢弃该事件,防止重复执行。
2.2 数据一致性保障
-
使用ROW格式的Binlog记录行级变更细节,减少因不确定性函数(如
NOW())导致的主从不一致问题。 -
半同步复制(需插件支持):主库提交事务后需等待至少一个从库确认接收Binlog,平衡性能与数据安全。
-
监控与维护:定期使用
pt-table-checksum校验数据一致性,pt-table-sync修复差异;监控复制延迟(SHOW SLAVE STATUS中的Seconds_Behind_Master)
2.3 数据冲突
1> 主键冲突:两节点同时插入相同主键
- 通过配置
auto_increment_increment(步长)和auto_increment_offset(起始偏移),例如设置MasterA生成奇数ID,MasterB生成偶数ID,避免主键冲突。 -
使用全局唯一ID生成器(如Snowflake、UUID)。
2> 同一行更新:两节点并发更新同一行数据
- 按业务逻辑分片写入(如用户ID哈希),或通过分布式锁限制同一数据的并发写操作。
- 不同业务模块访问不同主节点的特定库或表(如APP1写MasterA的DB1,APP2写MasterB的DB2),避免跨节点数据冲突。
3> 唯一键冲突:违反唯一性约束
参照 2>
2.4 高可用与故障转移
-
VIP漂移:通过Keepalived或HAProxy实现IP自动切换。
-
脑裂处理:
-
使用仲裁机制(如中间件或第三方服务)判断节点存活状态。
-
配置防火墙规则或STONITH(Shoot The Other Node In The Head)避免双主同时写入。
-
-
故障恢复:
-
宕机节点恢复后,需重新同步缺失数据(通过备份或增量日志)。
-
2.5 主备切换
1> 可靠性优先
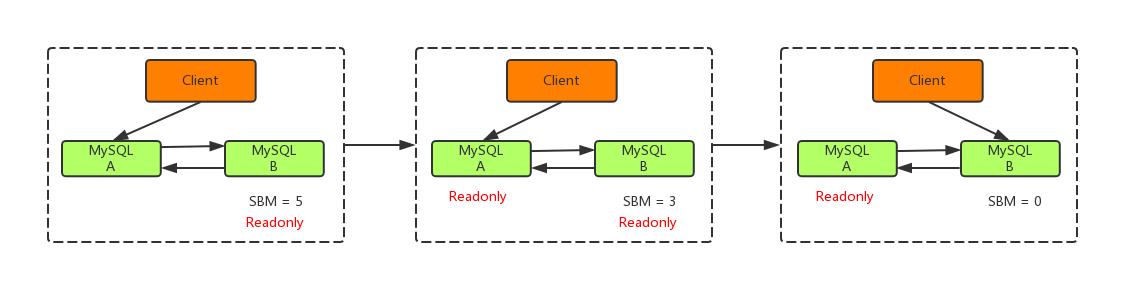
主库由 A 切换到 B ,切换的具体流程如下:
- 判断从库B的Seconds_Behind_Master值,当小于某个值才继续下一步
- 把主库A改为只读状态(readonly=true)
- 等待从库B的Seconds_Behind_Master值降为 0
- 把从库B改为可读写状态(readonly=false)
- 把业务请求切换至从库B
2> 可用性优先
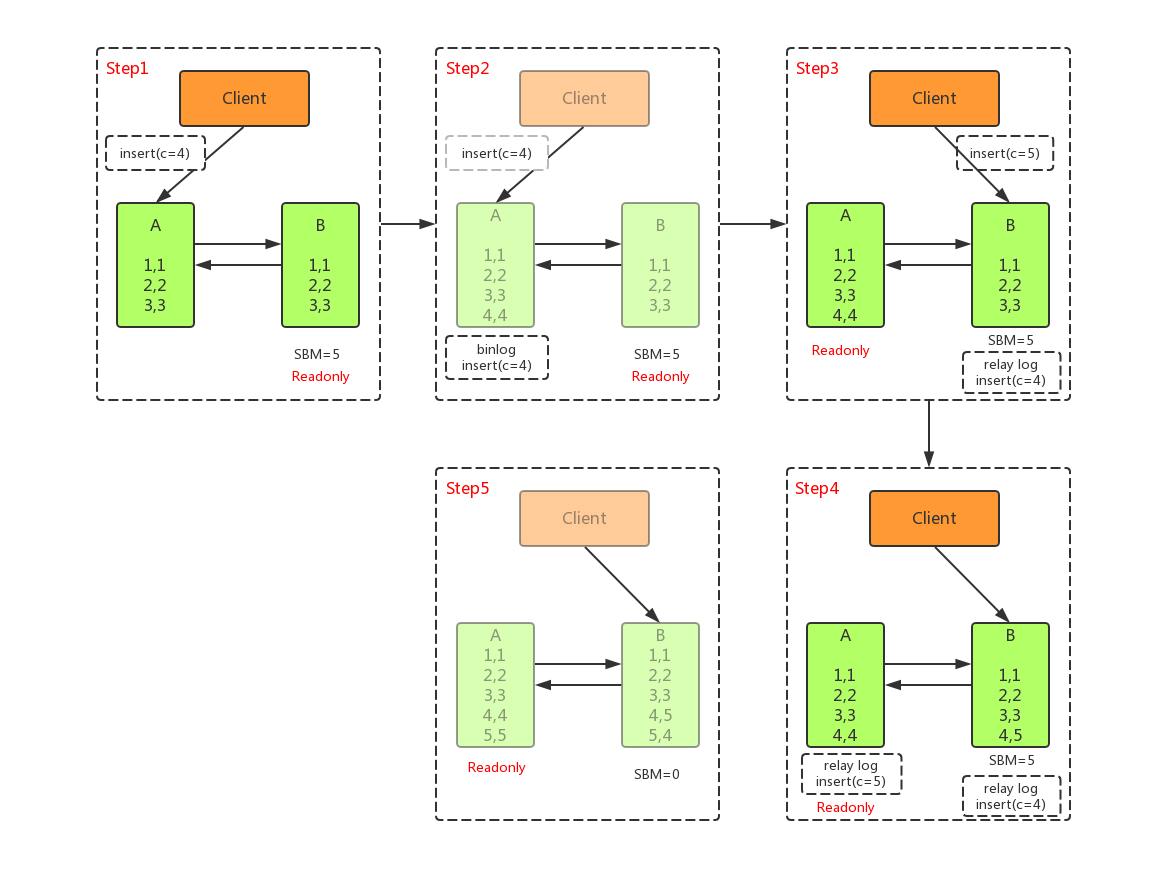
如上图所示,在 A 切换到 B 过程中,执行两个 INSERT 操作,过程如下:
- 主库A执行完 INSERT c=4 ,得到 (4,4) ,然后开始执行 主从切换
- 主从之间有5S的同步延迟,从库B会先执行 INSERT c=5 ,得到 (4,5)
- 从库B执行主库A传过来的binlog日志 INSERT c=4 ,得到 (5,4)
- 主库A执行从库B传过来的binlog日志 INSERT c=5 ,得到 (5,5)
- 此时主库A和从库B会有 两行 不一致的数据
3、两种架构
3.1 MMM架构
MMM基于MySQL的双主复制架构,通过虚拟IP(VIP)管理实现高可用性。其主要特点包括:
-
双主模式:两个主节点(Master1和Master2)互为主备,但同一时间只有一个节点对外提供写服务,另一个节点作为热备或读节点。(不支持GTID复制,基于日志点复制)
-
虚拟IP切换:通过VIP实现读写请求的自动迁移。当主节点故障时,VIP漂移至备选主节点,从节点通过
CHANGE MASTER命令指向新主节点。 -
监控与代理:由
mmm_mon(监控进程)和mmm_agent(代理进程)组成,监控节点状态并执行故障切换。- monitor:监控集群内数据库的状态,在出现异常时发布切换命令,一般和数据库分开部 署。
- agent:运行在每个 MySQL 服务器上的代理进程,monitor 命令的执行者,完成监控的探针工作和具体服务设置,例如设置 VIP(虚拟IP)、指向新同步节点。
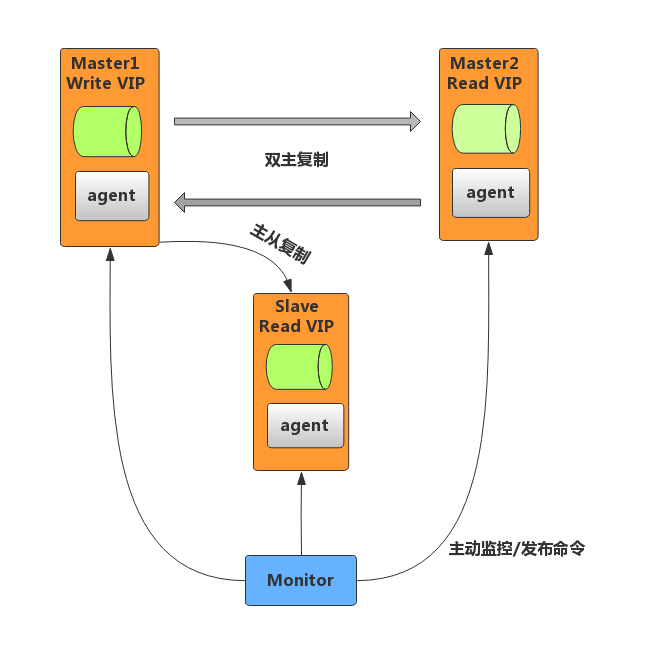
适用场景:
-
对读写高可用性要求较高的传统业务。
-
基于日志点复制(非GTID)的架构
3.2 MHA架构
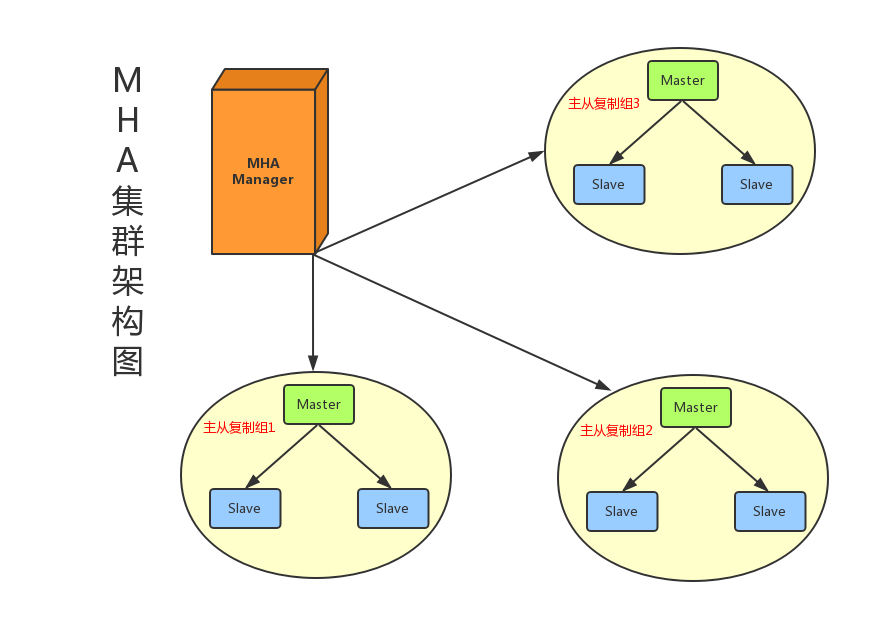
MHA通过自动故障转移和日志恢复机制保障高可用性:
-
主从选举:主节点故障时,从Slave中选举数据最新的节点为新主,并同步差异日志到其他Slave。
-
日志恢复:尝试从宕机主节点保存未同步的二进制日志(Binlog),最大程度减少数据丢失。
-
组件分工:
-
Manager节点:负责监控主节点状态,协调故障切换。
-
Node节点:运行在每台MySQL服务器上,执行日志保存和同步任务。
-
适用场景:
-
对数据一致性要求较高,需减少数据丢失的场景。
-
基于GTID复制的环境,支持一主多从架构
| 维度 | MMM | MHA |
|---|---|---|
| 架构模式 | 双主互备,同一时间单点写 | 一主多从,从Slave中选新主 |
| 数据一致性 | 依赖半同步复制,易丢事务 | 支持GTID和日志恢复,数据更安全 |
| 维护成本 | 工具包完善但社区停止维护 | 需开发VIP脚本,但社区较活跃 |
| 资源需求 | 需双主节点和多个VIP | 仅需一主多从,资源利用率高 |
| 适用场景 | 传统读写分离,日志点复制 | 高数据安全要求,GTID复制环境 |
4、典型应用场景
-
高并发系统:如电商、社交平台,需同时处理大量读写请求。
-
金融级容灾:要求数据强一致性和秒级故障切换的场景。
-
混合云环境:实现公有云与私有云间的实时数据同步。
三、分库分表
1、概念
概念:
-
分库:将数据按业务或规则分散到多个数据库中。
-
分表:将单个表的数据拆分到多个物理表中。
目的:
-
解决性能瓶颈:单库单表在数据量过大(如亿级数据)或高并发场景下,可能出现查询慢、锁争用等问题。
-
提升扩展性:通过水平扩展,支持业务快速增长。
-
提高可用性:故障时仅影响部分分片,而非整个数据库。
评估是否需要分库分表:
-
单表数据量超过5000万行,或QPS超过5000时考虑分片。
-
优先优化SQL、索引、缓存(如Redis)或读写分离。
渐进式拆分:
-
先垂直拆分,再水平拆分,逐步推进。
2、拆分方式
2.1 垂直拆分
垂直拆分:解决表过多或者是表字段过多问题。
垂直分库:
-
按业务模块拆分数据库(如用户库、订单库、商品库)。
-
优点:业务解耦,降低单库压力。
-
缺点:跨库事务复杂(需分布式事务如Seata)。
垂直分表:
-
将大表按列拆分(如将常用字段与不常用字段分开)。
-
优点:减少单表宽度,提升查询效率。
-
缺点:需多表关联查询,可能增加复杂度。
2.2 水平拆分
水平拆分:解决表中记录过多问题。
水平分库:
-
将同一业务的数据按规则分散到多个库(如按用户ID取模分3个库)。
水平分表:
-
将单表数据按规则分散到多个物理表(如
order_0、order_1)。 -
优点:数据分布均匀,支持海量数据。
-
缺点:跨分片查询复杂,需中间件支持。
3、关键技术
3.1 数据分片
分片键选择:
-
选择高频查询字段作为分片键(如用户ID、订单时间)。
-
需保证数据分布均匀,避免热点问题。
常见分片算法:
| 策略 | 实现方式 | 适用场景 | 缺点 |
|---|---|---|---|
| 哈希取模 | 分片号 = user_id % 分片数 | 数据均匀分布 | 扩容需重新哈希,迁移成本高 |
| 范围分片 | 按字段范围划分(如时间区间) | 支持范围查询(如按时间查订单) | 可能导致数据倾斜 |
| 一致性哈希 | 哈希环分配节点,扩容仅影响相邻分片 | 动态扩容场景 | 实现复杂 |
| 地理位置分片 | 按地区划分(如华北、华南库) | 本地化读写,降低延迟 | 跨区域查询效率低 |
分片键设计原则:
-
高频查询字段,数据分布均匀,避免频繁修改。
3.2 全局唯一ID
问题:分片后需避免主键冲突。
解决方案:
-
Snowflake算法:生成包含时间戳、机器ID、序列号的ID。
-
数据库号段:预分配ID范围(如美团的Leaf方案,通过数据库批量预分配ID段(如1~1000),内存分配ID,当前号段使用到10%时,异步触发下一个号段获取)。
3.3 跨库事务
问题:分布式事务难以保证ACID。
解决方案:
-
最终一致性:通过消息队列(如RocketMQ)异步补偿。
-
Seata框架:提供AT、TCC等分布式事务模式。
3.4 跨分片查询
问题:如SELECT * FROM order WHERE user_id IN (1001, 2005)需查多个分片。
解决方案:
-
中间件聚合:由ShardingSphere等工具合并结果。
-
异步批处理:分多次查询后汇总。
3.5 数据迁移与扩容
问题:增加分片时需迁移历史数据。
解决方案:
-
双写方案:新旧分片同时写入,逐步迁移(如阿里云DTS工具)。
-
一致性哈希:仅需迁移少量数据。
以hash取模方式分片 的平滑成倍扩容例子:
1> 新增2个数据库
2> 配置双主进行数据同步(先测试,后上线)
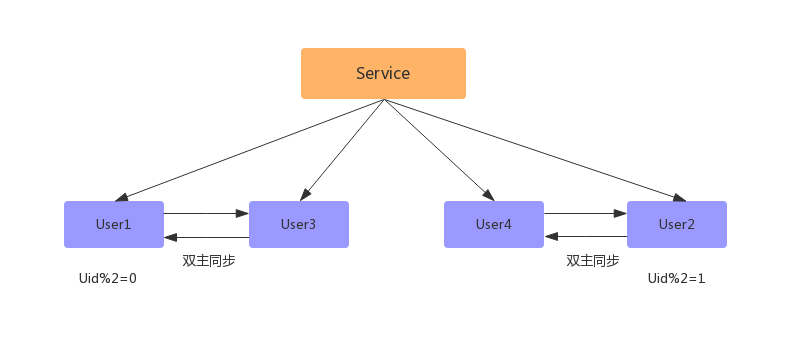
3> 数据同步完成之后,配置双主双写(同步因为有延迟,如果时时刻刻都有写和更新操作,会存在不准确问题)
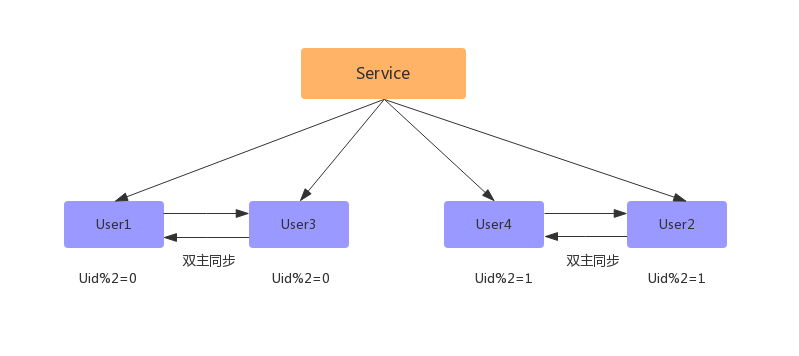
4> 数据同步完成后,删除双主同步,修改数据库配置,并重启
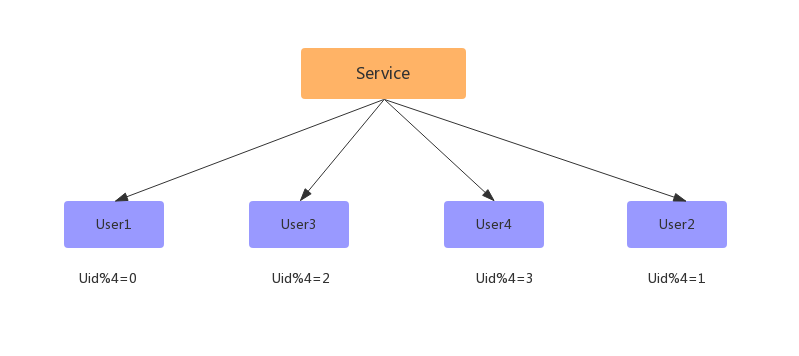
5> 此时已经扩容完成,但此时的数据并没有减少,新增的数据库跟旧的数据库一样多的数据,此时还需要写一个程序,清空数据库中多余的数据,如:
User1 去除 uid % 4 = 2 的数据;User3 去除 uid % 4 = 0 的数据;User2 去除 uid % 4 = 3 的数据;User4 去除 uid % 4 = 1 的数据;
4、常用工具与中间件
| 工具 | 特点 |
|---|---|
| ShardingSphere | Apache顶级项目,支持JDBC透明化分片,灵活配置(推荐)。 |
| MyCat | 基于Proxy的中间件,功能丰富但需独立部署。 |
| Vitess | YouTube开源的集群方案,适合Kubernetes环境,兼容MySQL协议。 |
| TiDB | 分布式NewSQL数据库,天然支持水平扩展,无需手动分片(替代传统方案)。 |
5、典型应用场景
-
电商订单表:按用户ID哈希分片,分散写入压力。
-
日志存储:按时间范围分片,便于冷热数据分离。
-
社交网络:按用户地域分片,降低跨区域查询延迟。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









