









导航
InputStreamReader&OutputStreamWriter
上一篇文章中,我们学习了字节流(建议先阅读上一篇文章:Java基础(八) IO流 —— 字节流)。
在文章末尾留下了这样一个问题:使用字节流读取含有中文的文件中的数据后,在控制台上打印这些数据会出现乱码问题。那么应该怎么解决这个问题呢?下面就带着问题来开始字符流的学习吧。
字符流
和字节流相同,字符流也有两个顶层抽象类——Reader和Writer。不过和字节流不同的是,字符流的文件输入输出流——FileReader和FileWriter并不是Reader和Writer的直接子类而是间接子类。本篇文章依然讲解文件输入输出流。
字符流与字节流的关系
在开始文件输入输出流的讲解之前,我们先要明白字符流和字节流之间是一种怎样的关系。
上一篇文章中给字符流下了这样的定义:
字符流 = 字节流 + 编码表
从上面的等式中,我们可以发现字符流的本质还是字节流,是对字节流深层次的加工。
字符流就是依照对应的编码表将需要的字节(个数不确定,可能是一个、两个、三个、四个)翻译成字符,或者将指定的字符依照对应的编码表转换成字节。
FileReader
FileReader类中只有三个构造方法,该类的其他方法继承自父类InputStreamReader:
public class FileReader extends InputStreamReader { ... }
所以InputStreamReader才是Reader的直接子类,至于设计成这样原因,在后文将会详细解释。
FileReader的基本操作和FileInputStream类似,不同的是底层实现,这里着重讲解二者不同的地方。见下面一个例子:
public class FileReader1 {
public static void main(String[] args) throws FileNotFoundException, IOException {
FileReader fr = new FileReader("testReader1.txt"); // FileNotFoundException
int a = fr.read(); // IOException
System.out.println(a); // 97
int b = fr.read();
System.out.println(b); // 25105
int c = fr.read();
System.out.println(c); // 67
int d = fr.read();
System.out.println(d); // -1
fr.close();
}
}异常与close()
这部分知识和上一篇文章重合,不再赘述。
read()
下面是文件testReader1.txt中的数据:
a我C
read()方法是一个重载方法,这里介绍无参的read()方法。每次调用read()方法会读取字符流中的一个字符并返回一个int类型的值,再次调用该方法时会读取字符流中的下一个字符。若字符流中已经不存在下一个字符,则返回-1。
既然read()方法读取的是一个字符,为什么返回值不是char类型呢?char类型取值范围是0~65535,也就是说将char类型作为返回值是无法返回-1的,因此这里将读取到的字符类型提升为int类型作为返回值。如果想要得到char类型值,只需要对返回值进行强转即可。
改进
下面对例子加以改进:
public class FileReader2 {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("testReader1.txt");
int ch;
while((ch = fr.read()) != -1) {
System.out.print((char)ch);
}
fr.close();
}
}FileWriter
和FileReader相同,FileWriter类中也只存在构造方法。见下面一个例子:
public class FileWriter1 {
public static void main(String[] args) throws FileNotFoundException, IOException {
FileWriter fw = new FileWriter("testWriter1.txt"); // FileNotFoundException
fw.write(97); // IOException
fw.write("bc");
fw.close();
}
}异常和追加写入
这部分知识和上一篇文章重合,不再赘述。
write()
相较于FileOutputStream,FileReader的write()方法不仅可以向输出流中写出字节,还可以直接写出字符串。打印结果如下所示:

其实FileOutputStream也可以直接向输出流中写出字符串,只不过写出的过程中还需要多进行一步操作——将字符串转换成字节数组。如下所示:
FileOutputStream fos = new FileOutputStream("xxx.txt");
fos.write("abc".getBytes());
缓冲区
将上面例子中的fw.close()注释掉,再次运行程序,刷新并查看testWriter1.txt文件,你看到了什么呢?一片空白。这个结果并没有错,那么出现这种情况就只有一种可能了——存在缓冲区。
这个缓冲区并没有定义在FileWriter中,而是定义在顶层抽象类Writer中,缓冲区的大小是一个字节:
public abstract class Writer implements Appendable, Closeable, Flushable {
private char[] writeBuffer;
private static final int WRITE_BUFFER_SIZE = 1024;
...
}
这个缓冲区很小,一般情况下我们会自定义一个更大的缓冲区。
自定义缓冲区
缓冲区这一块在上一篇文章讲的很详细,这里就不在赘述了。
用字符流读取非纯文本文件
字符流只能操作纯文本文件,假如我们非要用字符流来操作非纯文本文件呢?比如图片。口说无凭,实际操作才能知道结果是怎么样。见下面一个例子:
public class FileReader3 {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("picture.jpg");
int ch;
while((ch = fr.read()) != -1) {
System.out.print((char) ch);
}
fr.close();
}
}打印结果的一部分:
4�U�N��@nYt
$�k�M4�c<�QM��1�5�Vn�L�:+�X�����"A�3*
�s2o{��3BT
打印结果看上去全是乱码,但其实这些乱码也是有迹可循的。不难发现,乱码是由正常的字符和�组成。
使用字符流读取文件时,会将读取到的字节依照编码表转化成字符。然而对于图片文件而言,读取到的字节能否成功转换成字符是一个未知数。对于碰巧能够成功转换的字节,返回编码表中对应的字符;反之转换失败的字节,则返回�。这就是我们所认为的乱码的来源。
所以只有在操作纯文本文件的时候才可以使用字符流,操作其他类型的文件时应该使用字节流。
文件拷贝
学会了文件输入输出流,就可以进行文件拷贝。但是文件拷贝的工作并不推荐使用字符流来做,因为使用字符流读取和写入文件时,会有一个转换的过程。如下图所示:
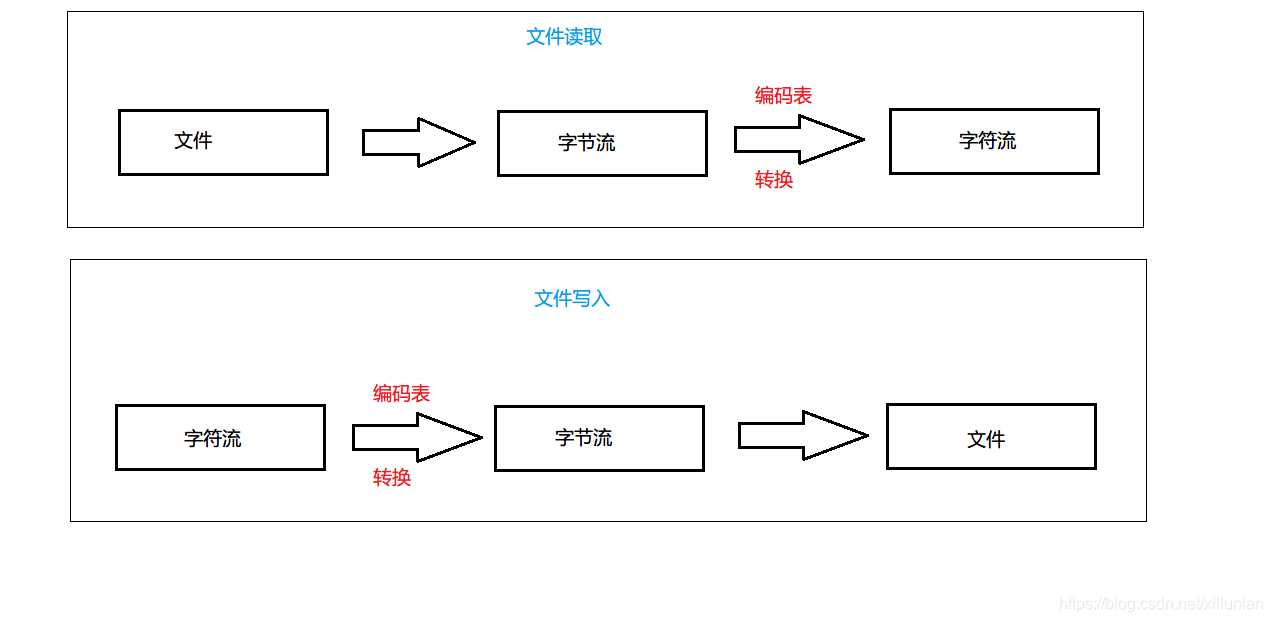
而拷贝这件事情所需要的就是字节->字节就可以了,所以仅仅是为了拷贝文件的话不要使用字符流。
除此之外,如果使用字符流来拷贝非纯文本文件的话还会出错。例如运行下面的程序就会出现错误:
public class FileCopy {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("picture.jpg");
FileWriter fw = new FileWriter("copy3.jpg");
char[] arr = new char[8192];
int len;
while((len = fr.read(arr)) != -1) {
fw.write(arr, 0, len);
}
fr.close();
fw.close();
}
}拷贝完成后,你就会发现copy3.jpg文件根本无法打开,究其原因正是字符流所做的转换而导致的。如果这里原因你不是很清楚,请仔细阅读上面的用字符流读取非纯文本文件。
LineNumberReader
使用LineNumberReader可以设置读取文本文件的每行数据的行号,其构造函数接收一个Reader作为参数。见下面一个例子:
public class LineNumberReader1 {
public static void main(String[] args) throws IOException{
LineNumberReader lnr = new LineNumberReader(new FileReader("chinese.txt"));
String line;
while((line = lnr.readLine()) != null) {
System.out.println(lnr.getLineNumber() + ":" + line);
}
lnr.close();
}
}打印结果如下:
1:你好你好
readLine()
每次调用readLine()方法可以读取字符流中的一行数据,若字符流中已经不存在下一行数据,则返回null。
可能你会觉得奇怪——之前调用read()方法时,若流中(字节流、字符流)不存在可读取的数据都是返回-1,怎么到readLine()方法返回值就变成了null呢?
这是因为readLine()方法的返回值是String类型,无法返回-1这种数值类型。所以readLine()对返回值进行了一次转换,将-1转换成null返回来作为文件的结束标志。
lineNumber
LineNumberReader中存在成员变量:lineNumber,通过getLineNumber()和setLineNumber()方法可以读取和设置该成员变量,若不调用setLineNumber()方法设置lineNumber,则lineNumber默认为0。
public class LineNumberReader extends BufferedReader {
private int lineNumber = 0;
...
}
而打印结果的行号为1,是因为调用readLine()方法时会让lineNumber自增。
public String readLine() throws IOException {
...
lineNumber++;
...
}
装饰设计模式
其实我们不难发现LineNumberReader的功能就仅仅是为读取文本文件的每行数据设置行号,除此之外就没有其他作用了。我们将LineNumberReader称之为装饰类,LineNumberReader使用的设计模式就是装饰设计模式。
装饰类是对既有类(FileReader)的一种扩展,让既有类变的更加强大。
可能你会说为什么不将LineNumberReader设计成FileReader的子类呢?当然这也是可以的。但是如果将LineNumberReader设计为FileReader的子类,二者之间的的耦合性会很高,随着扩展功能的增加,继承体系会变得越来越臃肿,扩展性变差。
而既有类衍生出的装饰类和既有类之间的耦合性很低,如果需要追加新的扩展功能,只需要增加装饰类即可;反之若不再需要某个扩展功能,只要删除装饰类就行了。
InputStreamReader&OutputStreamWriter
截止目前,我们workspace使用的编码是utf-8,而我们读取文本文件的编码也都是utf-8编码:

那么如果workspace使用的编码和文本文件的编码不一致,使用字符流读取文件会怎么样呢?见下面一个例子:
public class FileReader4 {
public static void main(String[] args) throws IOException {
FileReader fr = new FileReader("utf-16.txt");
int ch;
while((ch = fr.read()) != -1) {
System.out.print((char) ch);
}
fr.close();
}
}文件utf-16.txt编码和内容如下:


控制台打印结果:
��`O}Y`O}Y
很明显,当workspace使用的编码和文本文件的编码不一致时,使用字符流读取数据就会出现问题。因此出现这种情况,就不能再使用FileReader读取文件,而应该使用FileReader的父类——InputStreamReader。
指定编码操作文件
InputStreamReader的构造函数接收两个参数——InputStream对象和指定的编码,编码的大小写不用在意。见下面一个例子:
public class InputStreamReader1 {
public static void main(String[] args) throws IOException{
InputStreamReader isr = new InputStreamReader(new FileInputStream("utf-16.txt"), "uTf-16");
int ch;
while((ch = isr.read()) != -1) {
System.out.print((char) ch);
}
isr.close();
}
}控制台打印结果如下:
你好你好
需要注意的是InputStreamReader接收的对象是InputStream类型而不是Reader类型。这里可以佐证之前给出的等式:
字符流 = 字节流 + 编码表
而OuputStreamWriter则可以指定编码写出到文件中,如下所示:
public class InputStreamReader2 {
public static void main(String[] args) throws IOException{
InputStreamReader isr = new InputStreamReader(new FileInputStream("utf-16.txt"), "utf-16");
OutputStreamWriter osr = new OutputStreamWriter(new FileOutputStream("utf-8.txt"), "utf-8");
int ch;
while((ch = isr.read()) != -1) {
osr.write(ch);
}
isr.close();
osr.close();
}
}
char与汉字
char类型的取值范围是0~65535,也就是说我们最多可以在控制台上打印65536种字符,这其中包括了符号、中文、英文、日文、韩文等各种字符。下面是Unicode码表部分码截图(这里用到了一个小工具:UniToy):

然而光中文汉字有10万多个,很明显在Java程序中无法显示所有的汉字,只能显示常见的汉字(3500个左右)。那么码值超出char取值范围的汉字在Java程序中会怎么显示呢?
首先在Unicode码表中选取一个码值超出char取值范围的汉字,这里选取的汉字码值为0x020068,见下图:

接着打印一些相关的信息:
public class CharAndChinese {
public static void main(String[] args) {
System.out.println(0x020068);
System.out.println((char) 131176);
System.out.println((int) 'h');
System.out.println(131176 % 65536);
}
}打印结果如下:
131176
h
104
104
0x020068对应的十进制是131176,很明显这个值已经超出了char的取值范围,将131176强转为char类型,其结果是‘h’。然而打印‘h’所对应的十进制,其结果却是104。将131176模65536,其结果也是104。
通过这个例子可以看出来,对于超出char取值范围的汉字,Java采用的策略是取模——取这个汉字的码值模65535之后的结果。
POI
至此文件输入输出流的部分就算全部讲完了,然而你可能已经发现——目前为止我们用字符流操作的文本文件全都是TXT格式的,也就是我们一直所说的纯文本文件,或者称之为无格式文本文件。
假如你尝试着用字符流去操作Word或Excel这类带格式的文本文件(非纯文本文件),就会发现在控制台上打印出来的是一片乱码。操作这两类文件,我们就需要引入新的jar包——apache.poi包,当然这已经不在本文的讨论范围之内。
文件的类型肯定远远不止我提到的这些,而学习脚步也不应该止于此。下次再会啦。
参考:
https://my.oschina.net/u/914655/blog/318664
https://www.zhihu.com/question/52346583















 232
232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









