







 本文记录了一个使用Python开发的大文本筛选过滤工具的制作过程,主要使用PyQT框架确保用户体验。工具能自动检测文件编码,预览并筛选大文件的前100行,提供多种过滤操作,包括文本和数值筛选。采用多线程处理数据,实时更新界面进度,以提高用户体验。同时,还记录了工具的维护和优化策略。
本文记录了一个使用Python开发的大文本筛选过滤工具的制作过程,主要使用PyQT框架确保用户体验。工具能自动检测文件编码,预览并筛选大文件的前100行,提供多种过滤操作,包括文本和数值筛选。采用多线程处理数据,实时更新界面进度,以提高用户体验。同时,还记录了工具的维护和优化策略。
批量大文本筛选过滤工具开发记录
本周花了两三天的时间做了一个大文本数据筛选工具,主要是针对excel打开很慢或者无法打开的几百兆乃至几G的csv、txt文件,提供常规的数据筛选、统计和输出功能。这个大文本筛序需求对生产中的数据挑选和数据分析来说是比较常见的。本文就开发的过程简单记录如下:
- 使用什么开发语言?
- 怎样保证用户体验?
- 如何维护优化?
使用什么开发语言?
这问得有点像是废话。我很熟悉Python,它的开发速度足够的快,又足够灵活,特别是它强大的eval函数可以直接执行字符串代码,字符串代码中可以包含变量和函数,这也就意味着我可以在字符串中设定特定的变量来代替文件的每一行数据,然后执行对应的方法来判断这一行该不该输出,这对自定义筛选规则来说相当的适合。至于处理速度,凭经验python处理几百万行的数据也就几分钟事情,都在容忍范围内,因而python成了首选。
怎样保证用户体验?
这个工具的用户主要还是生产人员和分析人员,对他们来说,效率速度都是其次,简答好用、节省大部分时间就行。因而我将用户体验分解为操作简单、界面友好两部分。用户平时大部分是用excel来查看筛选数据的,因而最好是能提供类似的excel的数据查看界面和筛序手段。这就涉及到使用什么框架去开发界面的问题了。界面框架选择我还是秉着熟悉优先的原则,那理所当然是Qt,它的信号和槽机制用起来真叫一个爽。虽然之前用Qt都是在C++下的,不过Qt的Python版本-PYQT的接口都差不多,有不懂的直接看下文档就行。
操作简单原则
参考excel的数据导入功能,搞了一上午,设计的界面如下:
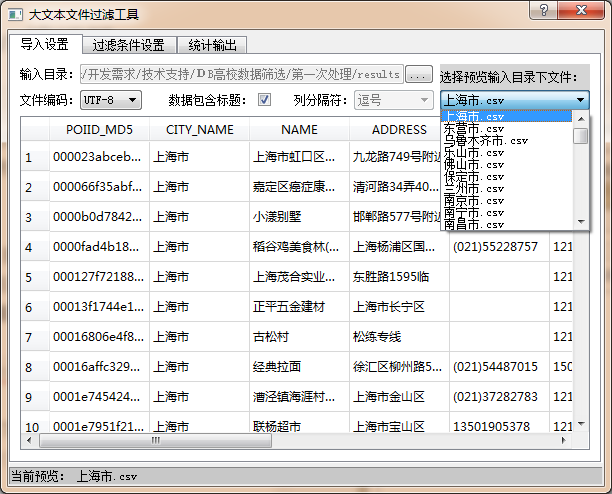
数据的编码格式一般是GBK、GB18030、UTF-8等几种,但好些用户很多时候是根本不知道也不关注数据的编码格式的(所以当他们打开一个csv看到一堆乱码的时候可能会说,怎么是乱码啊?),所以在导入数据时我使用了chardet模块来预测数据的编码格式,免去了用户的选择,代码如下:
with open(filepath, 'rb') as rf:
#这里读取2kb内容是为了提高识别的准确度
charset = chardet.detect(rf.read(2048))['encoding']
if charset == 'GB2312':charset = 'GBK'对于大文本来说,用户不大可能去查看所有内容,他们一般来说知道数据的格式就足够了,所以我设定了每个文件只显示前100行数据。同时,为了便于用户查看同一目录下不同文件,我设置了一个预览文件列表选择框,选择改变时即时更换预览表格里面的内容。当用户改变文件编码格式、是否包含文件头以及列分隔符时,也会即时更
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4674
4674

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









