







PromQL

QL顾名思义,Query language即查询语言。Prometheus作为强大的开源监控系统,最大的依赖便是PromQL。是监控数据个性化查询、展示的基础。所以要掌握Prometheus,掌握PromQL是必备的前提。
瞬时向量:包含该时间序列中最新的⼀个样本值
区间向量:⼀段时间范围内的数据
第一部分:普罗米修斯容器化
1.安装prometheus
概念:普罗米修斯容器化就是在kubernetes中安装。
##去Github仓库拉取代码
[root@k8s-master-01 ~]# git clone -b release-0.5 --single-branch https://github.com/prometheus-operator/kube-prometheus.git
fatal: unable to access 'https://github.com/prometheus-operator/kube-prometheus.git/': Failed connect to github.com:443; Connection refused
##拉取失败,老是报错:没办法用下面的
[root@k8s-master-01 opt]# ll
-rw-r--r-- 1 root root 268354 4月 23 20:10 kube-prometheus-0.5.0.tar.gz
[root@k8s-master-01 opt]# tar -xf kube-prometheus-0.5.0.tar.gz
drwxrwxr-x 11 root root 4096 4月 17 2020 kube-prometheus-0.5.0
[root@k8s-master-01 opt]# cd kube-prometheus-0.5.0/
[root@k8s-master-01 kube-prometheus-0.5.0]# ll
总用量 124
drwxrwxr-x 3 root root 4096 4月 17 2020 manifests
##安装相关yaml文件
root@k8s-master-01 kube-prometheus-0.5.0]# cd manifests/
[root@k8s-master-01 manifests]# ll
。。。一堆yaml文件。。。
注意:这里不能立马用 kubectl apply -f ./ 否则k8s集群会宕机,我们先跳到setup/安装operator(它是管理prometheus的管理插件)。再跳出来安装
[root@k8s-master-01 manifests]# cd setup/
。。。一堆yaml文件。。。
[root@k8s-master-01 setup]# kubectl apply -f ./
[root@k8s-master-01 setup]# cd ..
[root@k8s-master-01 manifests]# kubectl apply -f ./
查看一下启动情况,出现下面便是成功
[root@k8s-master-01 manifests]# kubectl get pods -n monitoring
prometheus-operator-848d669f6d-z6ct2 2/2 Running 0 4m28s
##为grafana、prometheus设置ingress
[root@k8s-master-01 manifests]# vim prometheus_ingress.yaml
kind: Ingress
apiVersion: extensions/v1beta1
metadata:
name: grafana
namespace: monitoring
spec:
rules:
- host: "www.grafana.monitoring.cluster.local.com"
http:
paths:
- backend:
serviceName: grafana
servicePort: 3000
path: /
---
kind: Ingress
apiVersion: extensions/v1beta1
metadata:
name: prometheus-k8s
namespace: monitoring
spec:
rules:
- host: "www.prometheus-k8s.monitoring.cluster.local.com"
http:
paths:
- backend:
serviceName: prometheus-k8s
servicePort: 9090
path: /
[root@k8s-master-01 manifests]# kubectl apply -f prometheus_ingress.yaml
Warning: extensions/v1beta1 Ingress is deprecated in v1.14+, unavailable in v1.22+; use networking.k8s.io/v1 Ingress
ingress.extensions/grafana created
ingress.extensions/prometheus-k8s created
##成功设置ingress的SVC 向外面暴露的端口
[root@k8s-master-01 manifests]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.100.63.141 <none> 80:31230/TCP,443:32526/TCP 9d
ingress-nginx-controller-admission ClusterIP 10.110.79.171 <none> 443/TCP 9
2.在宿主机上配hosts
C:\Windows\System32\drivers\etc/hosts
192.168.15.31 www.grafana.monitoring.cluster.local.com www.prometheus-k8s.monitoring.cluster.local.com
对于要经常访问的网站,我们可以通过在Hosts中配置域名和IP的映射关系,提高域名解析速度。由于有了映射关系,当我们输入域名计算机就能很快解析出IP,而不用请求网络上的DNS服务器。
3.分别登陆域名和端口,登陆prometheus 和 grafana
http://www.prometheus-k8s.monitoring.cluster.local.com:31230
http://www.grafana.monitoring.cluster.local.com:31230
第二部分:登陆成功后做的后续动作
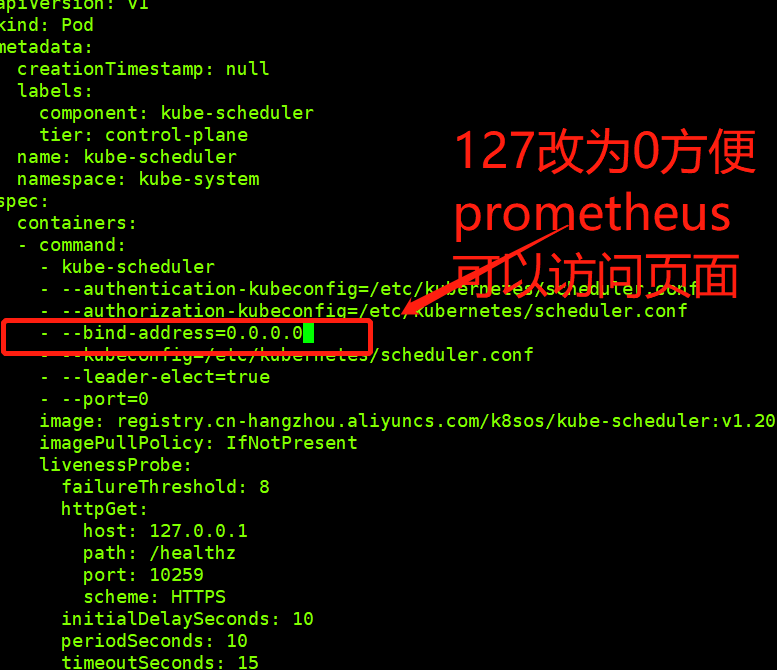
1.修改这里方便prometheus可以访问到k8s组件里scheduler里的信息
[root@k8s-master-01 manifests]# vi kube-scheduler.yaml
[root@k8s-master-01 manifests]# kubectl apply -f kube-scheduler.yaml
pod/kube-scheduler created
2.代表我们在设置ingress资源类型的时候在自定义空间monitoring里形成的ingress域名
[root@k8s-master-01 ~]# kubectl get ingress -n monitoring
NAME CLASS HOSTS ADDRESS PORTS AGE
grafana <none> www.grafana.monitoring.cluster.local.com 192.168.15.32 80 100m
prometheus-k8s <none> www.prometheus-k8s.monitoring.cluster.local.com 192.168.15.32 80 100m
3.代表我们在设置ingress时候,立刻生成的一个nginx里向外面暴露的端口,同时这个nginx也反向代理了后面的pod
[root@k8s-master-01 ~]# kubectl get svc -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller NodePort 10.100.63.141 <none> 80:31230/TCP,443:32526/TCP 9d
ingress-nginx-controller-admission ClusterIP 10.110.79.171 <none> 443/TCP 9d
第三部分:Grafana
1.测试
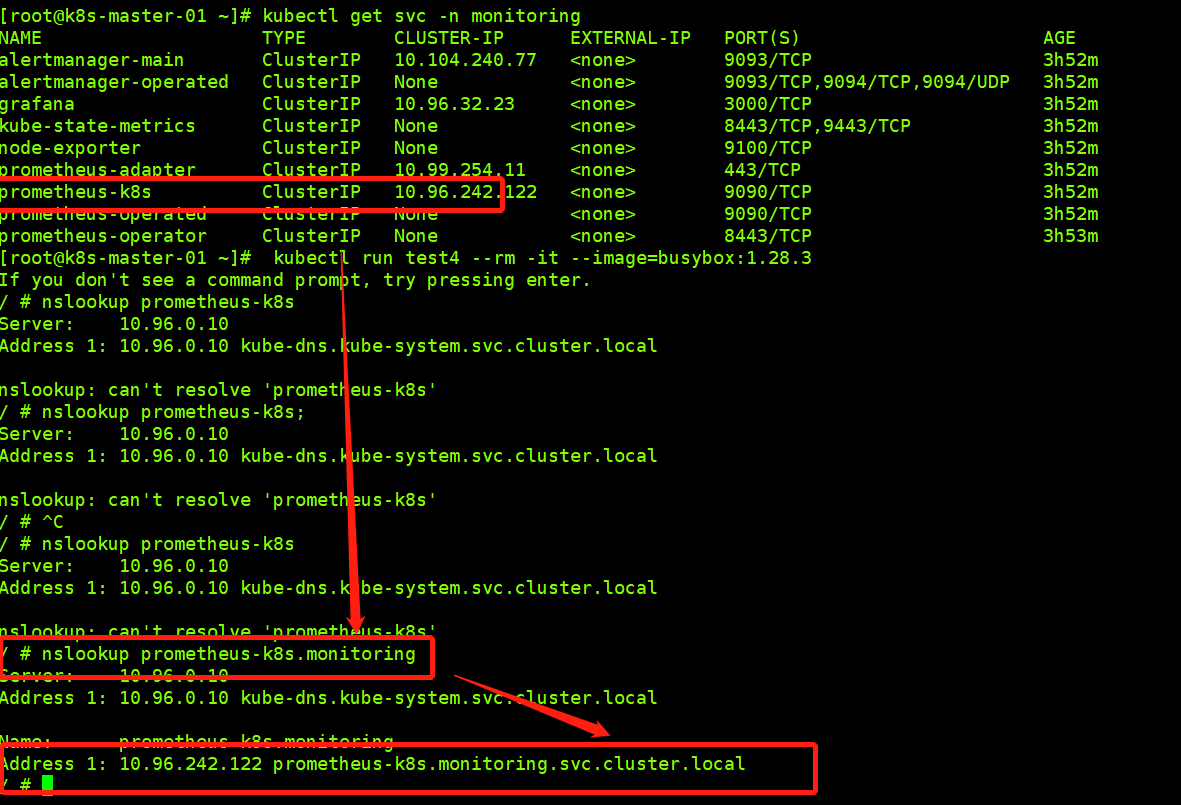
[root@k8s-master-01 ~]# kubectl run test4 --rm -it --image=busybox:1.28.3
/ # nslookup prometheus-k8s.monitoring
Server: 10.96.0.10
Address 1: 10.96.0.10 kube-dns.kube-system.svc.cluster.local
Name: prometheus-k8s.monitoring
Address 1: 10.96.242.122 prometheus-k8s.monitoring.svc.cluster.local
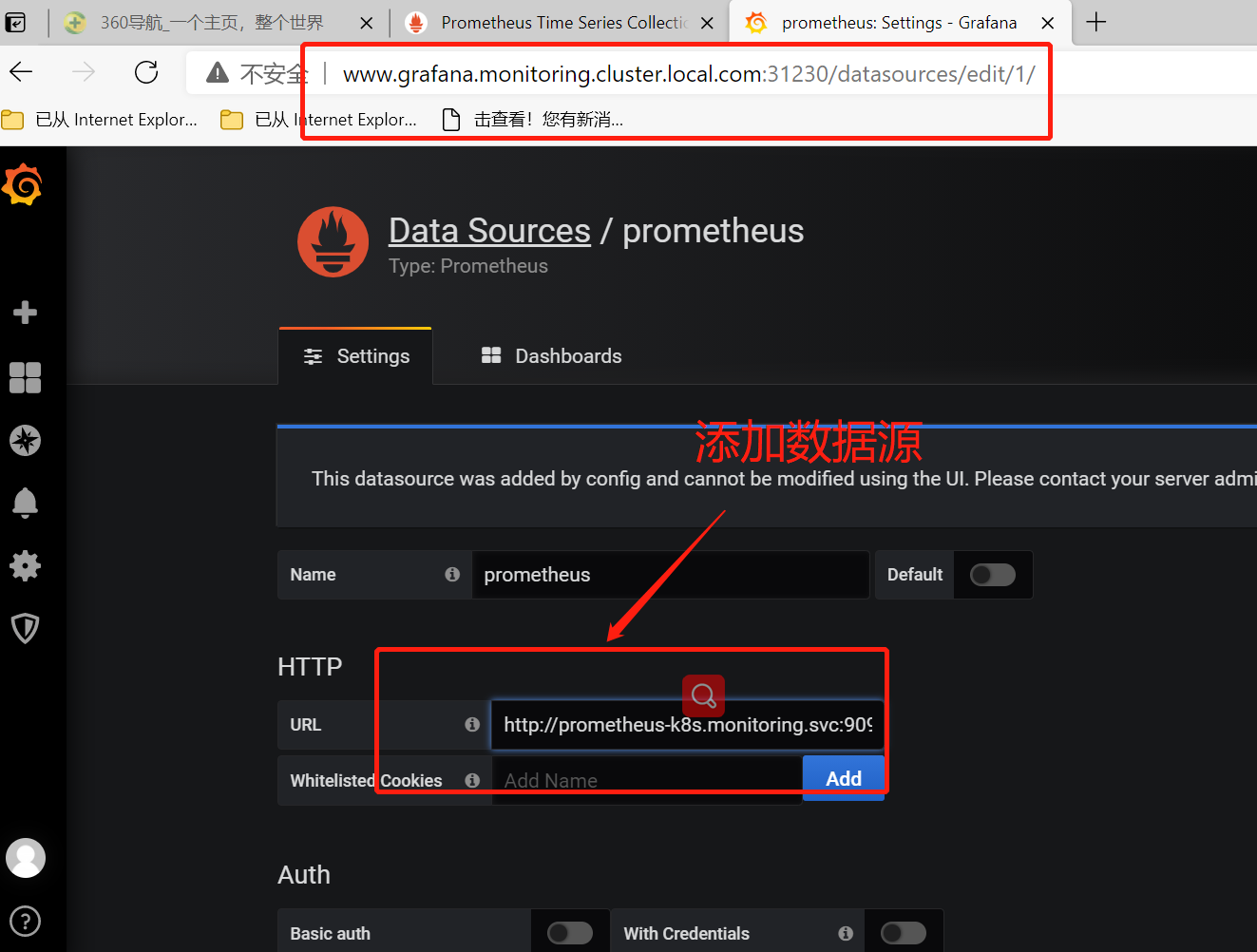
2.添加prometheus数据源
##添加prometheus数据源
http://prometheus-k8s.monitoring.svc.cluster.local:9090
第四部分:简单运算
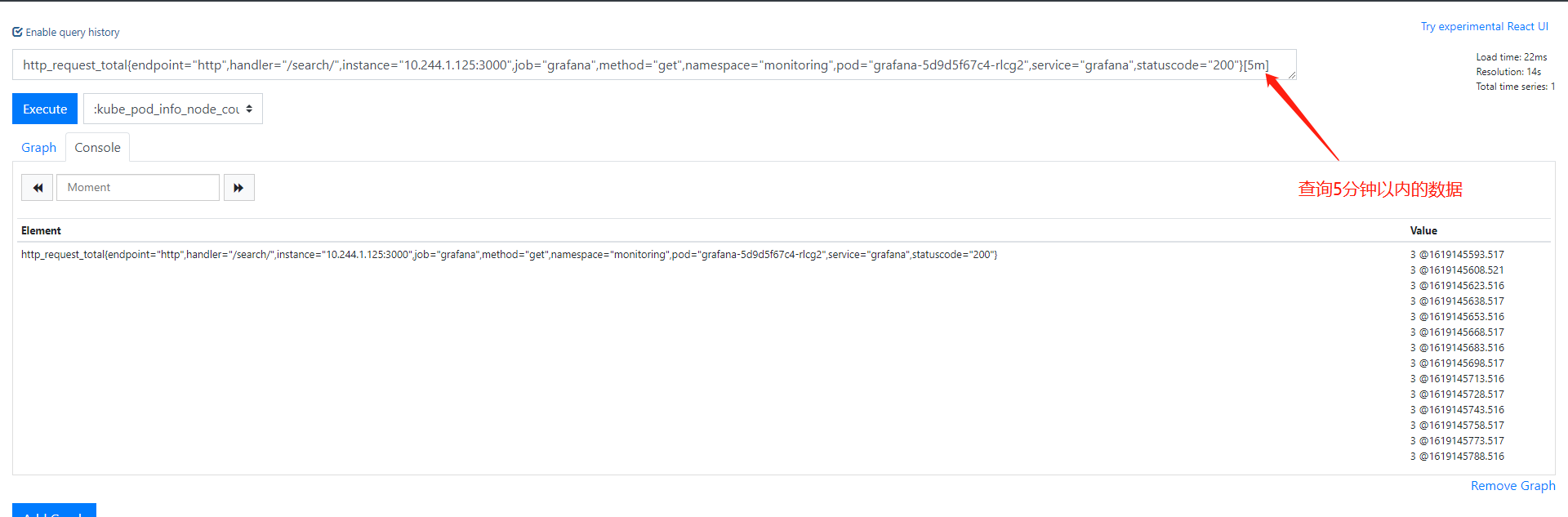
1.查询5分钟以内的数据
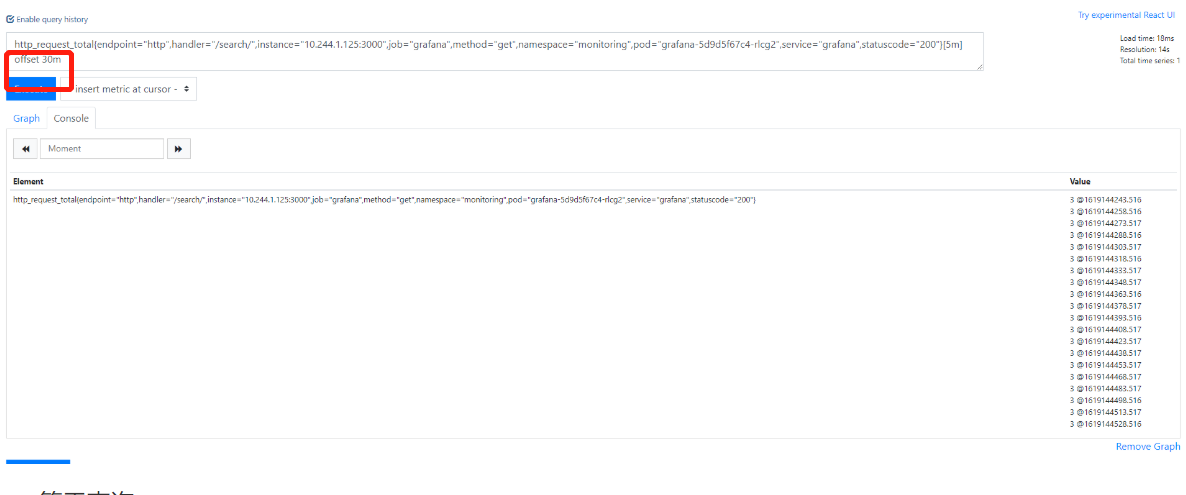
2.查询30分钟以前的数据
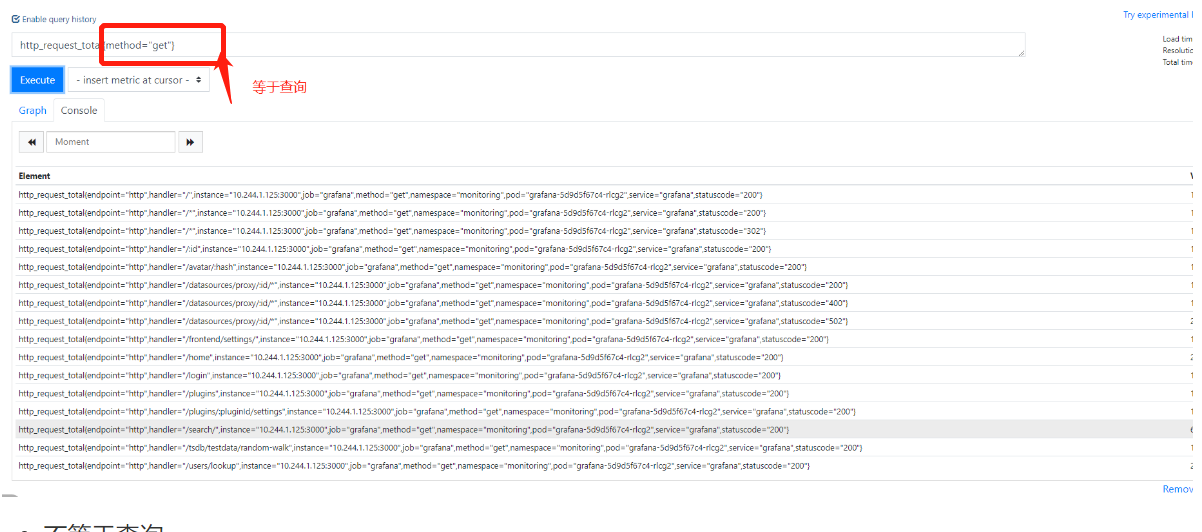
3.等于查询
4.不等于查询
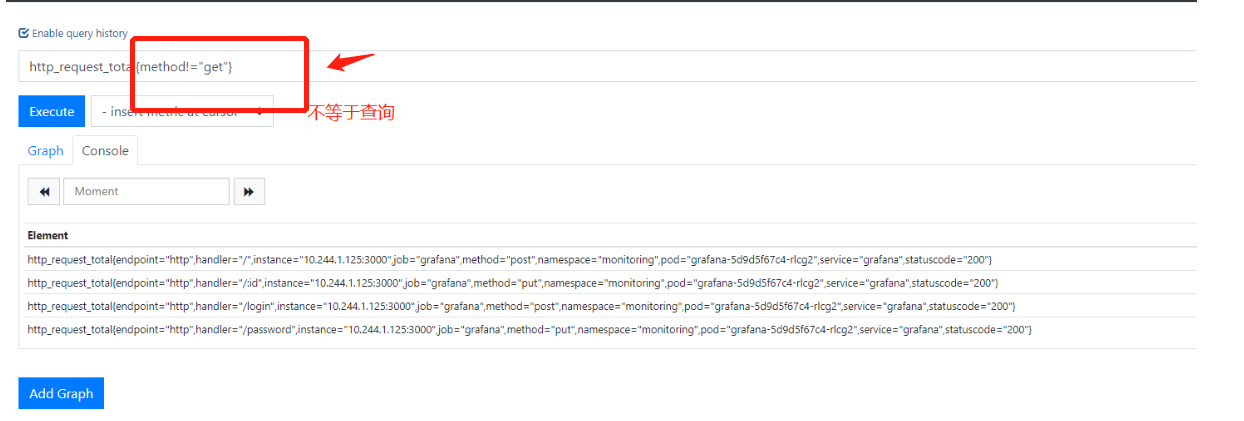
5.正则匹配: =~
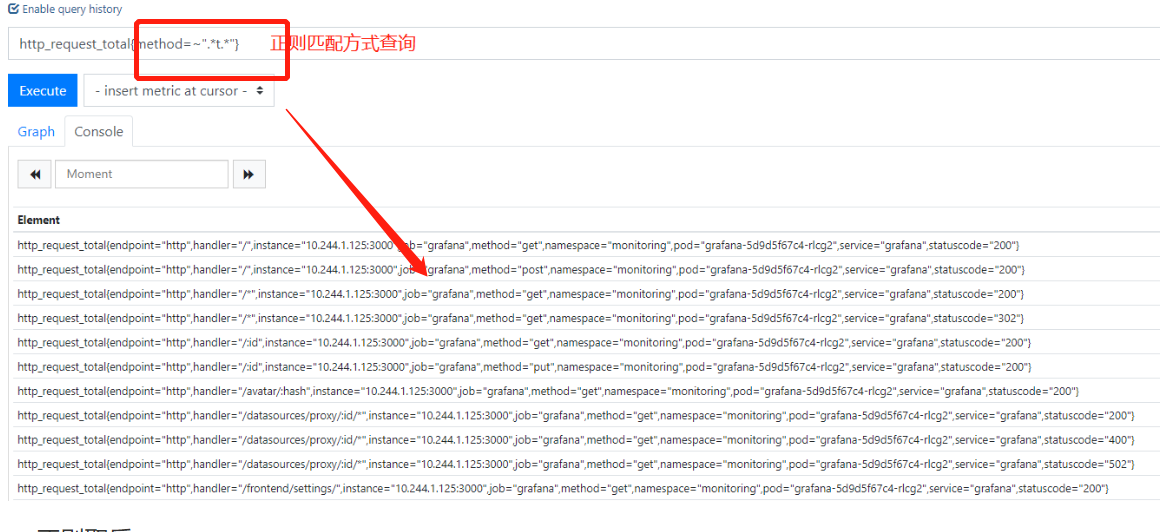
6.正则取反匹配: !~
=:匹配与标签相等的内容
!=:不匹配与标签相等的内容
=~: 根据正则表达式匹配与标签符合的内容
!~:根据正则表达式不匹配与标签符合的内容
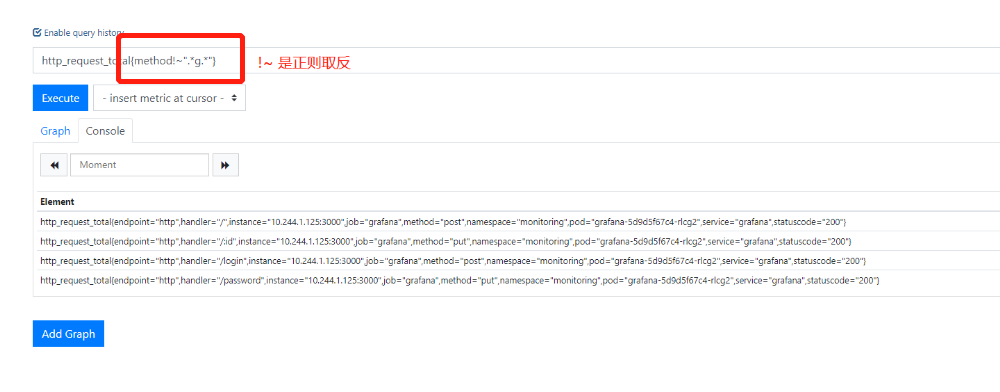
7.计算机内存空闲率
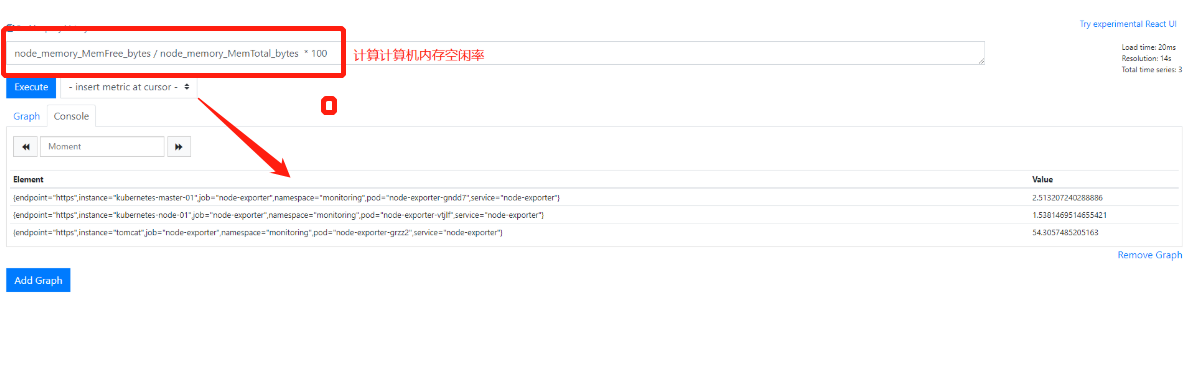
8.计算机空闲内存小于1G这个地方有争议(老师估计有坑)
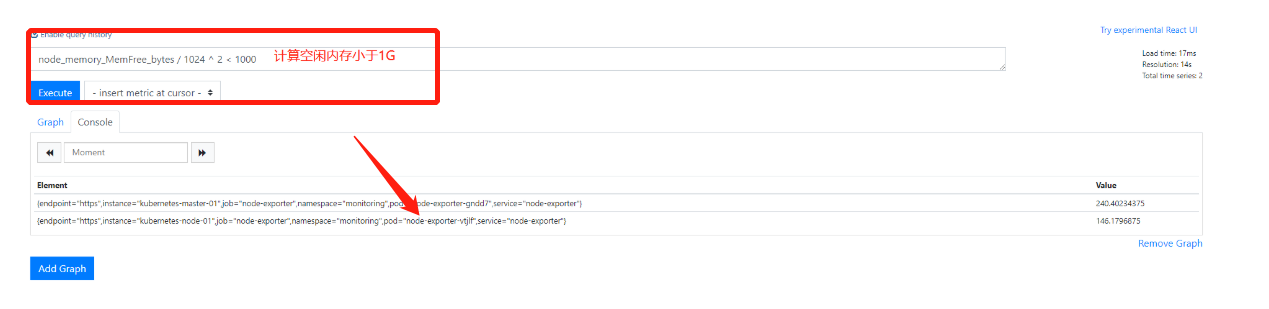
第五部分:聚合运算
逻辑运算
1.and 并且(交集)
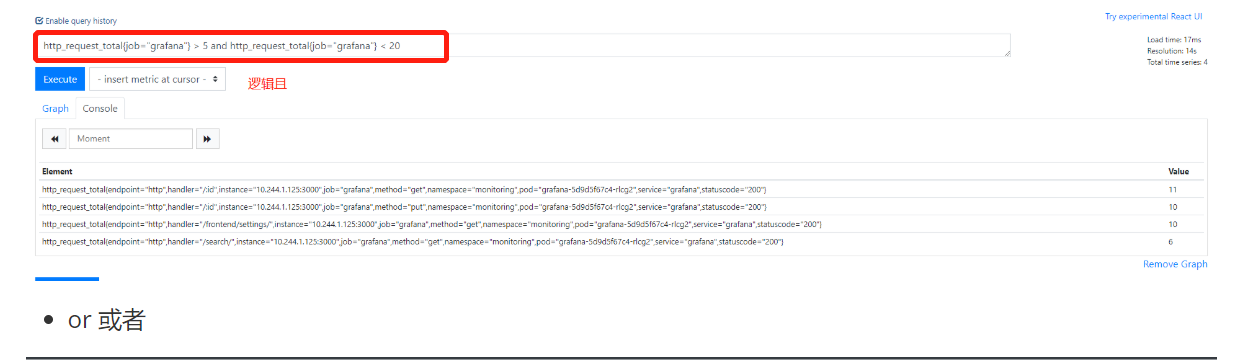
2.or 或者(并集)
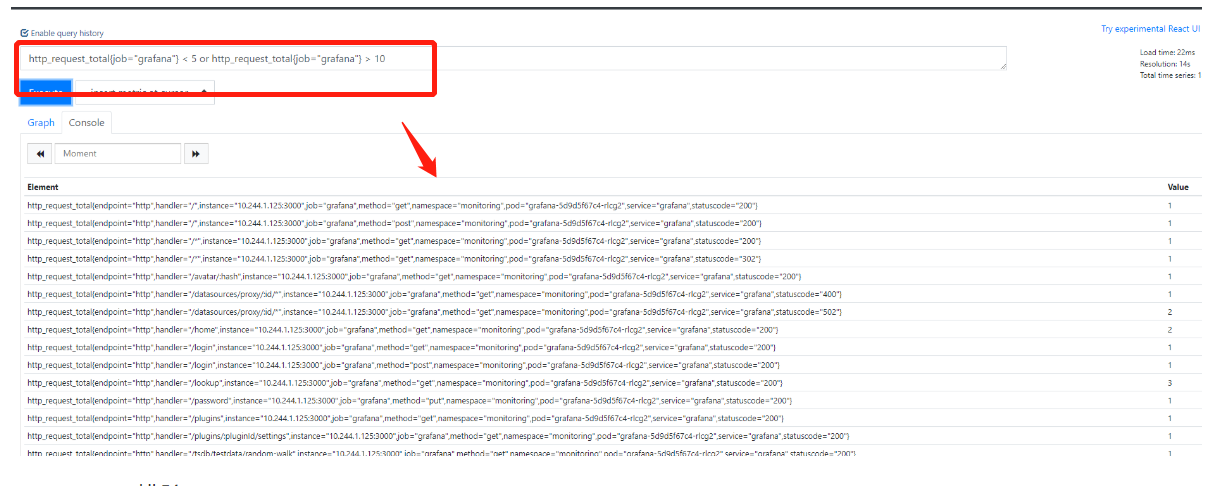
3.unless 排除(补集)
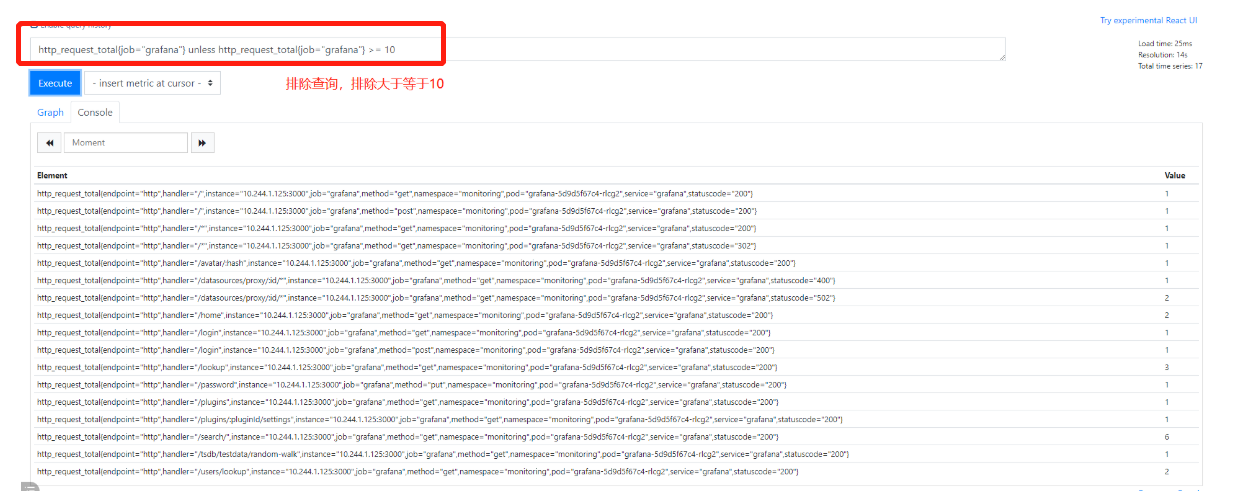
第六部分:聚合函数
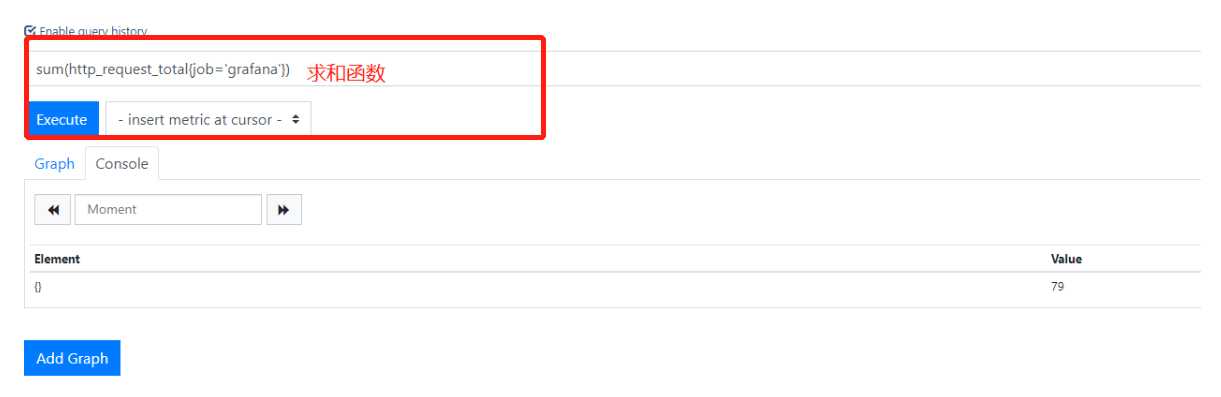
1.求和运算sum
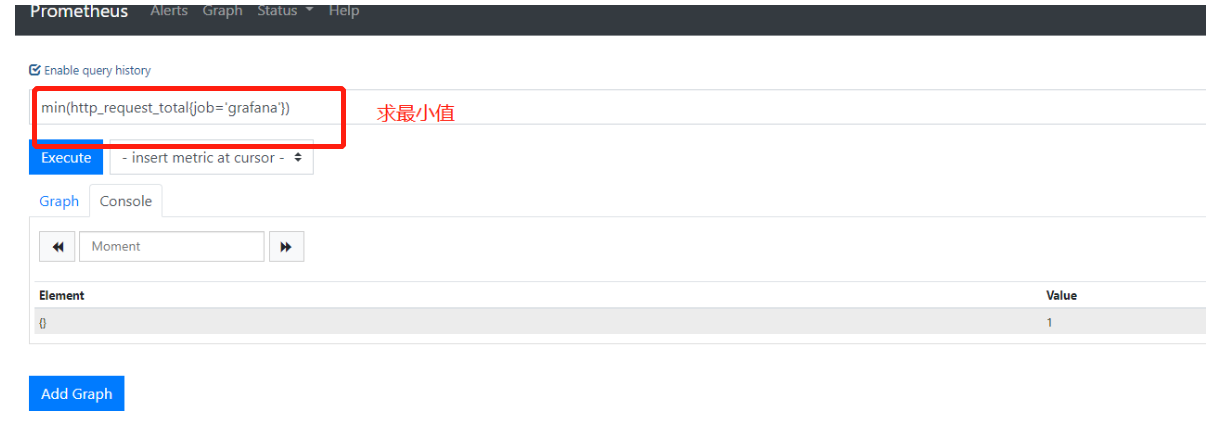
2.求最小值min
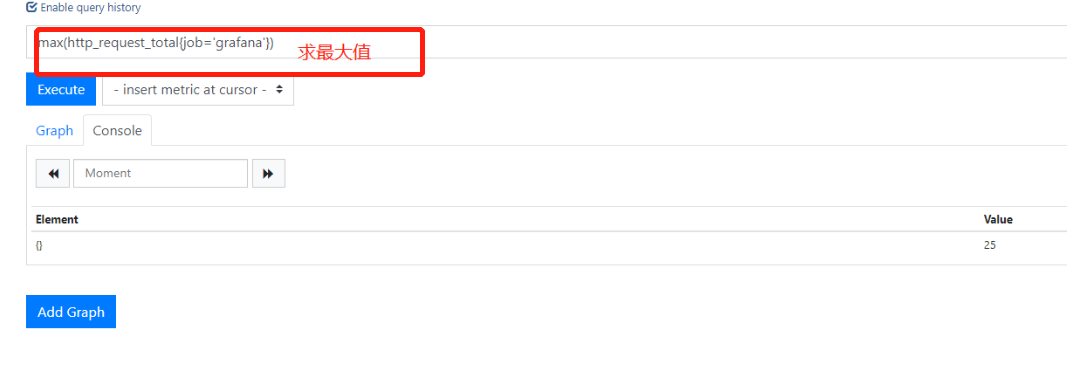
3.求最大值max
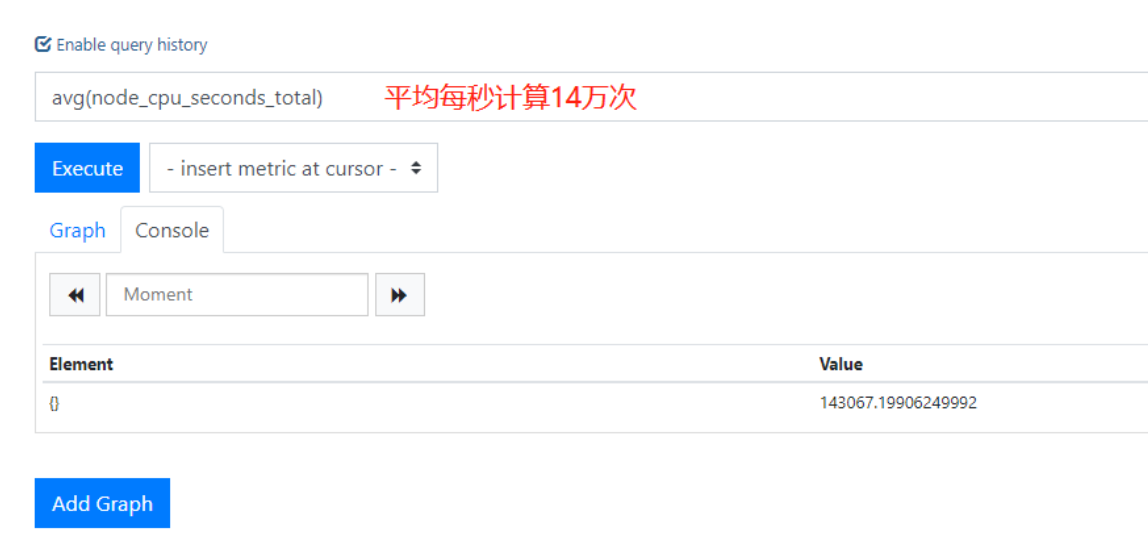
4.求平均数avg
5.计算标准差stddev
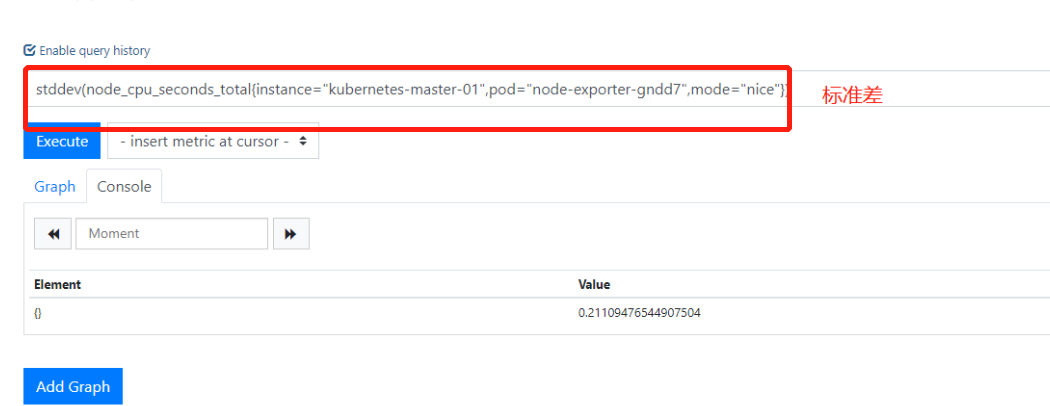
6.计算极方差stdvar

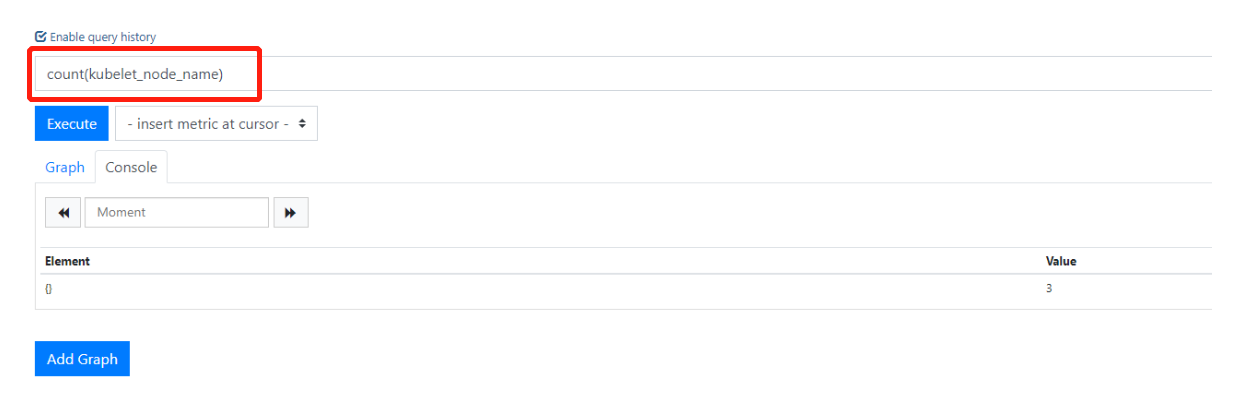
7.统计总个数count
8.分类计算个数:count_values

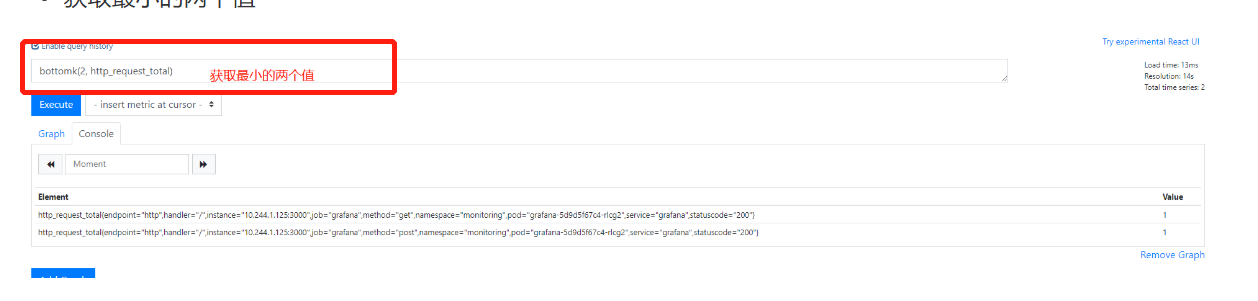
9.获取最小的两个值bottomk
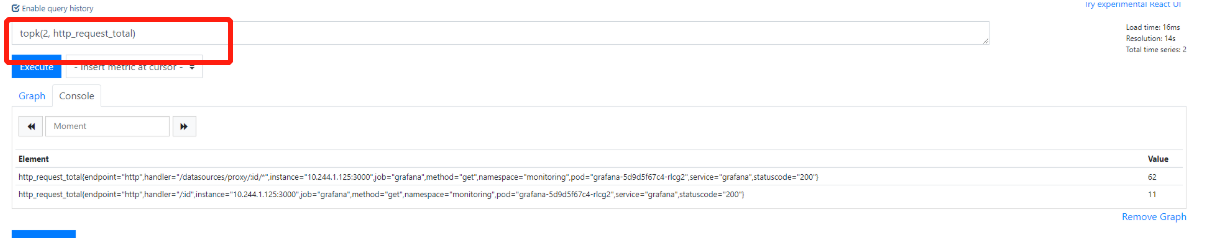
10.获取最大的两个值topk
11.获取某个位置上的数
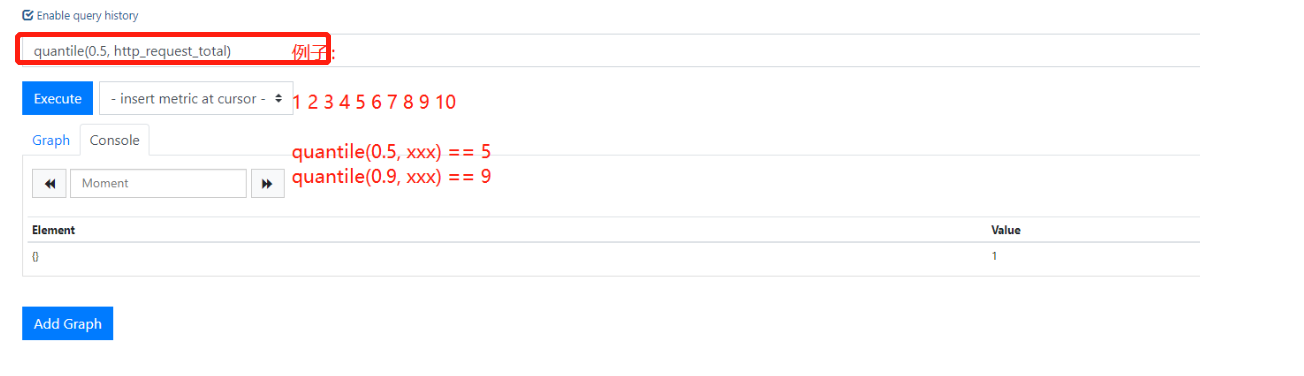
第七部分:二进制运算符优先级
^
*,/,%
+, -
==,!=,<=,<,>=,>
and, unless
or
第八部分:特殊查询
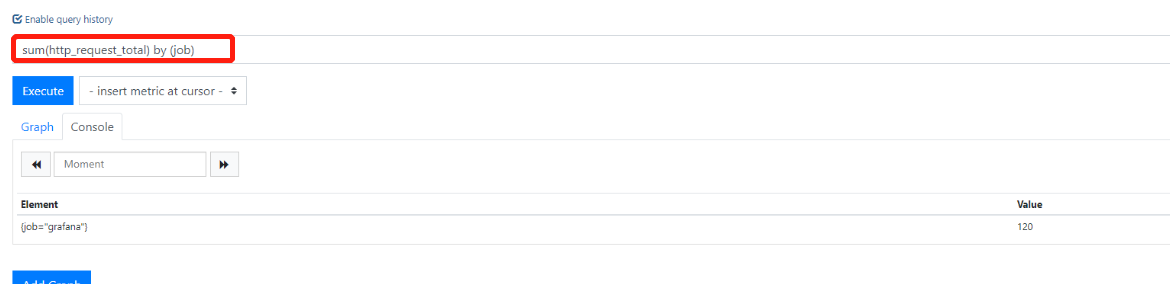
1.查询某个字段by{字段}
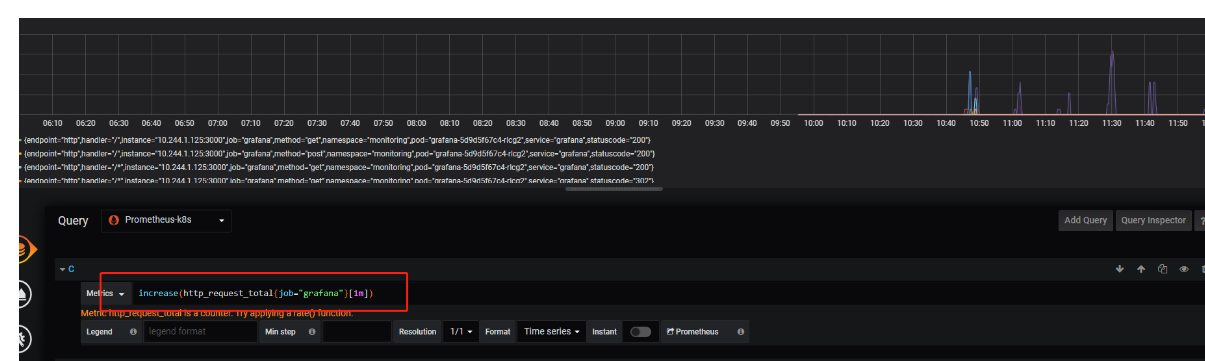
2.计算范围向量中时间序列的增加
increase(v range-vector) 函数获取区间向量中的第一个和最后一个样本并返回其增长量, 它会在单调性发生变化时(如由于采样目标重启引起的计数器复位)自动中断。由于这个值被外推到指定的整个时间范围,所以即使样本值都是整数,你仍然可能会得到一个非整数值。
例如,以下表达式返回区间向量中每个时间序列过去 5 分钟内 HTTP 请求数的增长数:
increase(http_requests_total{job="apiserver"}[5m])
increase 的返回值类型只能是计数器类型,主要作用是增加图表和数据的可读性。使用 rate 函数记录规则的使用率,以便持续跟踪数据样本值的变化。
3.计算范围向量中时间序列的每秒平均平均增长率
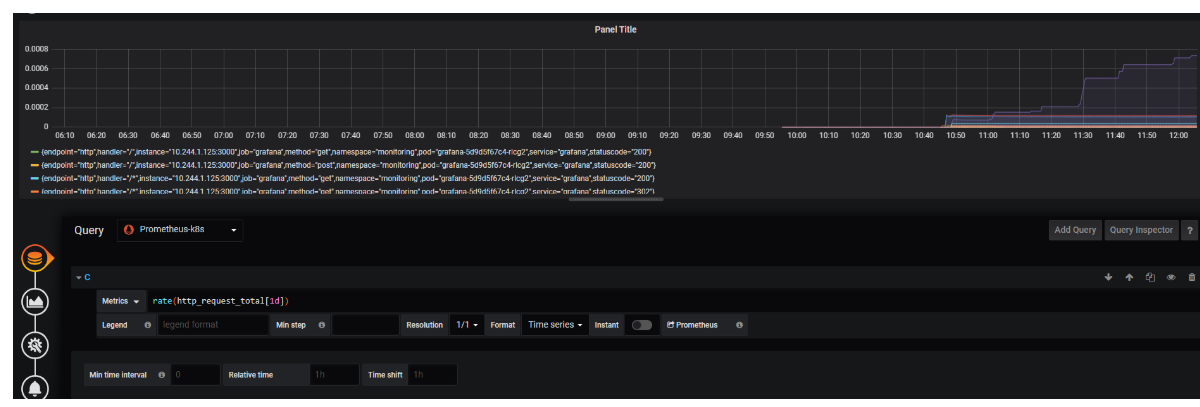
4.计算范围向量中时间序列的每秒平均平均增长率
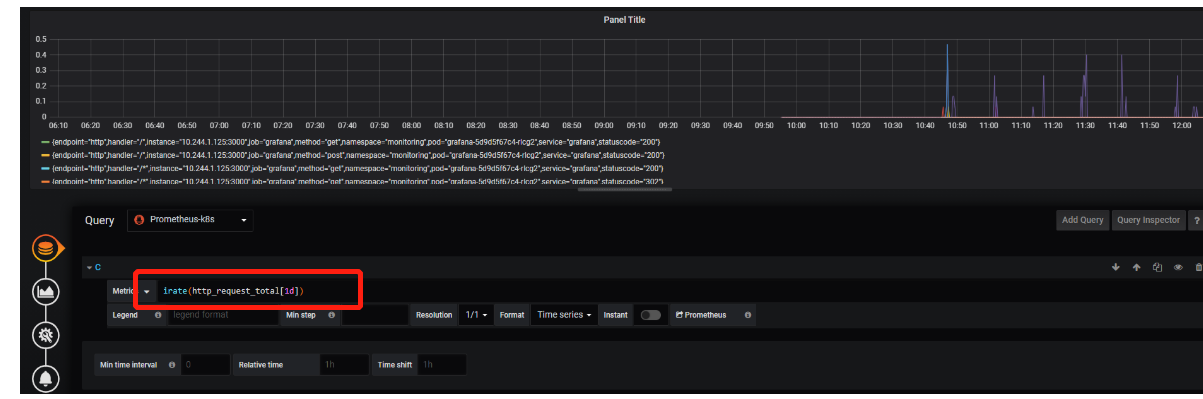
5.排序sort

6.倒序sort_desc
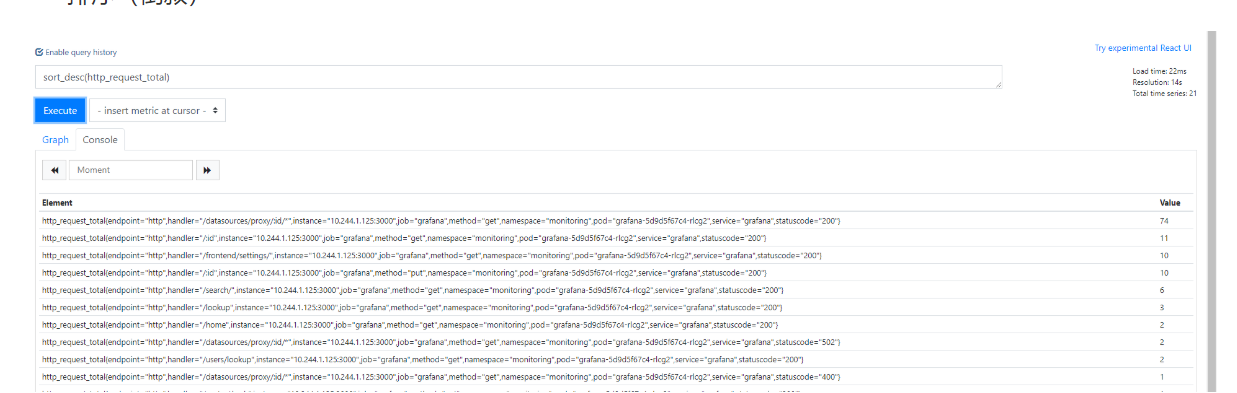
7.创建一个新字段label_join
#先简单查询一下http请求状态码为200,模式为get的总量
http_request_total{handler="/login",method="get",statuscode="200"}
#返回
http_request_total{handler="/login", instance="192.168.1.20:3000", job="grafana", method="get", statuscode="200"} 2
#我们想要在他的后面添加一个新的标签,标名他的完整路径
label_join(http_request_total{handler="/login",method="get",statuscode="200"},"url","","instance","handler")
#含义
label_join() #新增标签
http_request_total{handler="/login",method="get",statuscode="200"} #度量值
"url" #新标签的名称
"" #新标签的值以什么进行分割
instance","handler" #该标签的值由 这个指标下的instance、handler这两个标签提供
#由""进行分隔
#返回结果
url="192.168.1.20:3000/login"
另外一个理解:
label_join(v instant-vector, dst_label string, separator string, src_label_1 string, src_label_2 string, ...)
函数可以将时间序列 v 中多个标签 src_label 的值,通过 separator 作为连接符写入到一个新的标签 dst_label 中。可以有多个 src_label 标签。
例如,以下表达式返回的时间序列多了一个 foo 标签,标签值为 etcd,etcd-k8s:
up{endpoint="api",instance="192.168.123.248:2379",job="etcd",namespace="monitoring",service="etcd-k8s"}
=> up{endpoint="api",instance="192.168.123.248:2379",job="etcd",namespace="monitoring",service="etcd-k8s"} 1
label_join(up{endpoint="api",instance="192.168.123.248:2379",job="etcd",namespace="monitoring",service="etcd-k8s"}, "foo", ",", "job", "service")
=> up{endpoint="api",foo="etcd,etcd-k8s",instance="192.168.123.248:2379",job="etcd",namespace="monitoring",service="etcd-k8s"}
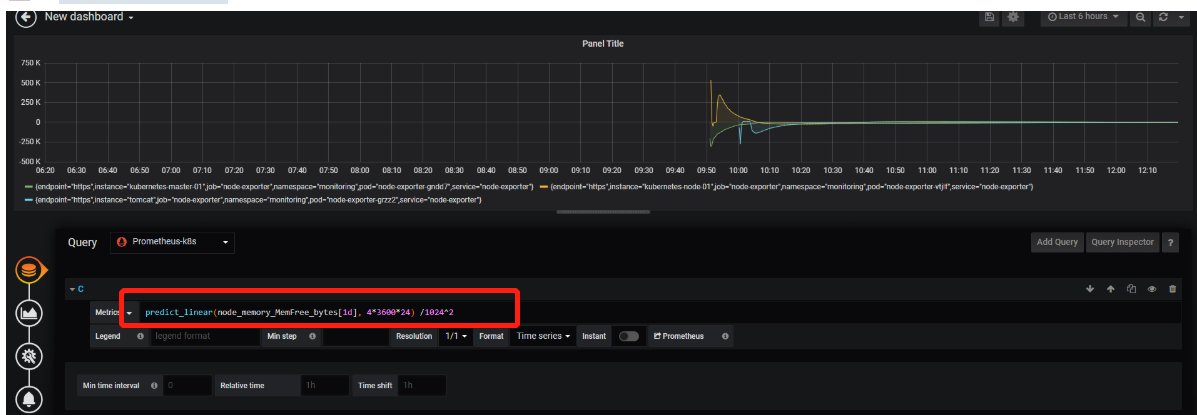
8.基于范围向量预测从现在开始到某个时间的资源消耗情况predict_linear
9.四舍五入(向上)ceil
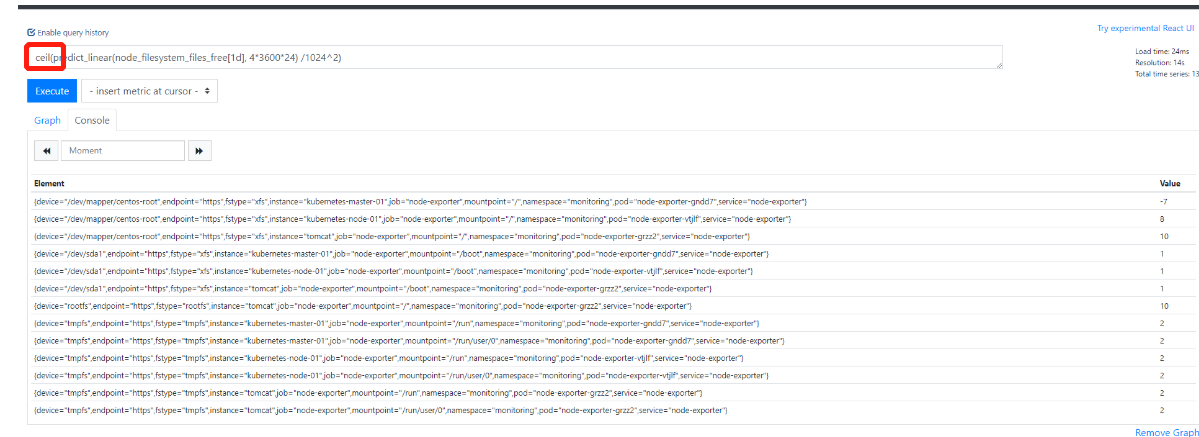
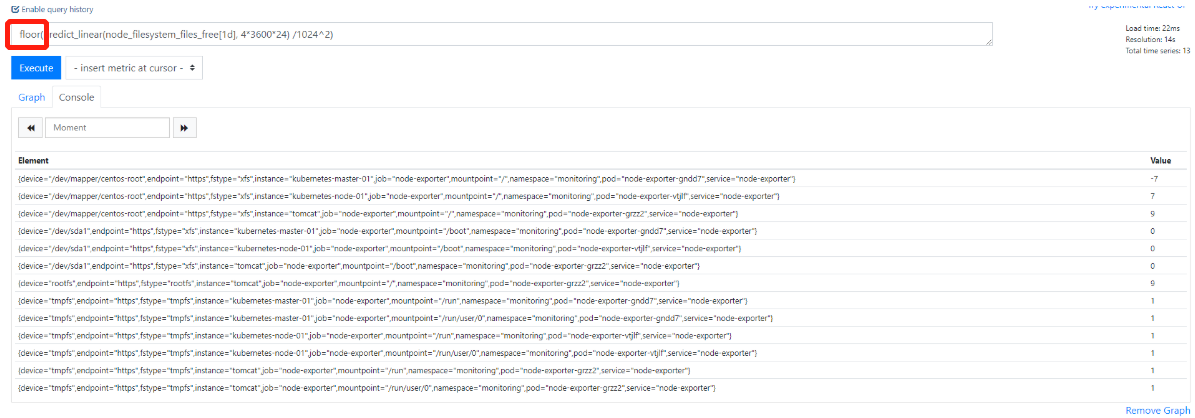
10.四舍五入(向下)floor















 269
269











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









