







前言:
近日,需要用Metis或ParMetis对大图数据进行分区,而分区的要求是输入的无向图要按照顶点ID排序,于是想到用Hadoop中的TeraSort算法对无向图进行排序。
说明:
本文要解决的问题是:谁调用了TeraSort子类TotalOrderPartitioner的configure(JobConf job)方法及如何调用的?
其属于细节问题,说好听叫“刨根问底”,负面讲则叫“钻牛角尖”。但我认为,我们应该在能力、时间允许内,弄清楚每个细节,踏踏实实做学问。
本人QQ:530422429,欢迎大家指正、讨论。
正文:
研读TeraSort源码后,对其思想和算法基本掌握。TotalOrderPartitioner类实现了Partitioner和JobConfigurable接口,并覆写了getPartition()和configure()方法。其中configure()方法如下:
public void configure(JobConf job) {
try {
FileSystem fs = FileSystem.getLocal(job);
Path partFile = new Path(TeraInputFormat.PARTITION_FILENAME);
splitPoints = readPartitions(fs, partFile, job);
trie = buildTrie(splitPoints, 0, splitPoints.length, new Text(), 2);
} catch (IOException ie)
throw new IllegalArgumentException("can't read paritions file", ie);
}
}可以发现,每个MapTask从分布式缓存中读取分割点,调用buildTrie()方法构造2-trie树。然后MapTask从split中依次读入数据,通过trie树查找每条数据所对应的reduce task编号。因此,构造2-trie树应在调用map()方法之前完成。可问题是:谁调用configure(JobConf job)方法及如何调用的?
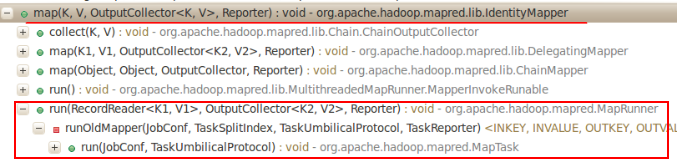
1. 打开configure(JobConf job)方法的 Call Hierarchy查看调用关系,结果如下图。竟然无调用关系,那么MapTask究竟是怎么构建2-Trie树的呢?疑惑中继续探索。

2. map完成后,写入数据时会进行partition,显然会调用TotalOrderPartitioner对象的getPartition()方法。 因此查看何时构造TotalOrderPartitioner对象的。猜想的情况是,构造完TotalOrderPartitioner对象后,再直接调用其configure(JobConf job)方法。由于TeraSort作业中没有设置mapper,因此使用了Hadoop默认的IdentityMapper,其对输入不作任何处理,直接将key-value对输出。IdentityMapper类内容如下:
/** Implements the identity function, mapping inputs directly to outputs.
*/
public class IdentityMapper<K, V>
extends MapReduceBase implements Mapper<K, V, K, V> {
/** The identify function. Input key/value pair is written directly to output.*/
public void map(K key, V val,
OutputCollector<K, V> output, Reporter reporter)
throws IOException {
output.collect(key, val);
}
}
查看MapTask的runOldMapper(…)方法,核心片段如下:
try {
runner.run(in,new OldOutputCollector(collector, conf), reporter);
collector.flush();
} @SuppressWarnings("unchecked")
OldOutputCollector(MapOutputCollector<K,V> collector, JobConf conf) {
numPartitions = conf.getNumReduceTasks();
if (numPartitions > 0) {
partitioner = (Partitioner<K,V>)
ReflectionUtils.newInstance(conf.getPartitionerClass(), conf);
} else {
partitioner = new Partitioner<K,V>() {
@Override
public void configure(JobConf job) { }
@Override
public int getPartition(K key, V value, int numPartitions) {
return -1;
}
};
}
this.collector = collector;
}3. 无奈+疑惑之下,进入ReflectionUtils类的newInstance(…)方法。如下:
@SuppressWarnings("unchecked")
public static <T> T newInstance(Class<T> theClass, Configuration conf) {
T result;
try {
Constructor<T> meth = (Constructor<T>) CONSTRUCTOR_CACHE.get(theClass);
if (meth == null) {
meth = theClass.getDeclaredConstructor(EMPTY_ARRAY);
meth.setAccessible(true);
CONSTRUCTOR_CACHE.put(theClass, meth);
}
result = meth.newInstance();
} catch (Exception e) {
throw new RuntimeException(e);
}
setConf(result, conf);
return result;
} public static void setConf(Object theObject, Configuration conf) {
if (conf != null) {
if (theObject instanceof Configurable) {
((Configurable) theObject).setConf(conf);
}
setJobConf(theObject, conf);
}
}4. 再查看setJobConf(theObject, conf)方法的代码。原来是根据JobConfigurable接口的Class对象获取Method对象,然后再根据实例对象theObject和参数conf动态调用configure(…)方法。到此,才走出雾霾,得以解惑。
private static void setJobConf(Object theObject, Configuration conf) {
//If JobConf and JobConfigurable are in classpath, AND
//theObject is of type JobConfigurable AND
//conf is of type JobConf then
//invoke configure on theObject
try {
Class<?> jobConfClass =
conf.getClassByName("org.apache.hadoop.mapred.JobConf");
Class<?> jobConfigurableClass =
conf.getClassByName("org.apache.hadoop.mapred.JobConfigurable");
if (jobConfClass.isAssignableFrom(conf.getClass()) &&
jobConfigurableClass.isAssignableFrom(theObject.getClass())) {
Method configureMethod =
jobConfigurableClass.getMethod("configure", jobConfClass);
configureMethod.invoke(theObject, conf);
}
} catch (ClassNotFoundException e) {
//JobConf/JobConfigurable not in classpath. no need to configure
} catch (Exception e) {
throw new RuntimeException("Error in configuring object", e);
}
}5. 以上根据代码调用关系和逐步推理得到了真相,总结一句:来之不易。
经验总结:日后若查不到方法的调用关系时,应该想到可能使用了Java反射机制来调用此方法。
下面再说一种简单获得configure(…)方法调用关系的方法。通过在其方法内打印调用堆栈来查看。如下:
public void configure(JobConf job) {
try {
FileSystem fs = FileSystem.getLocal(job);
Path partFile = new Path(TeraInputFormat.PARTITION_FILENAME);
splitPoints = readPartitions(fs, partFile, job);
trie = buildTrie(splitPoints, 0, splitPoints.length, new Text(), 2);
Exception e=new Exception("this is a log");
e.printStackTrace();
} catch (IOException ie) {
throw new IllegalArgumentException("can't read paritions file", ie);
}
}
正文结束。

附文:Java反射机制-Method的问题。
以前使用Java反射机制根据方法名执行方法时,都是根据类A来创建其Method对象,然后再根据类A的实例对象和Method调用方法。但仔细分析setJobConf(theObject, conf)方法,其获取的是接口JobConfigurable的Class对象的Method对象,下面的测试代码证明此方法的正确性。
JobConfigurable接口定义:
package com.test;
/**
*
* @author baisong
*
*/
public interface JobConfigurable {
//for test,the parameter type is String
void configure(String name);
}
package com.test;
/**
*
* @author baisong
*
*/
public class JobConfigurableImpl implements JobConfigurable{
@Override
public void configure(String name) {
System.out.println("Your name is "+name);
}
}
package com.test;
import java.lang.reflect.Constructor;
import java.lang.reflect.Method;
/**
* we only know the name of JobConfigurable.class and JobConfigurableImpl.class
*
* Note:we can't make the JobConfigurable and JobConfigurableImpl object directly.
*
* @author baisong
*
*/
public class MapTaskTest {
public static void main(String[] args) throws Exception {
// make the JobConfigurableImpl object
Constructor<?> meth=JobConfigurableImpl.class.getDeclaredConstructor();
Object obj=meth.newInstance();
Class<?> JobConfigurableClass=Class.forName("com.test.JobConfigurable");
Method configureMethod=JobConfigurableClass.getMethod("configure", String.class);
// invoke configure on the obj
configureMethod.invoke(obj, "BaiSong");
}
}
结果输入为:
Your name is BaiSong
总结:可通过接口创建Method对象。















 5408
5408

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









