







什么是Flink的非barrier对齐,如何实现?
这题设计到flink的容错机制。
首先说一说一致性检查点:在某一个时间点,给source中发送一个检查点事件,这个检查点事件会随着事件处理后像下游发送,当每一个并行度处理到检查点事件的时候,就会将这个事件的的相应结果保存到状态后端。如图所示:
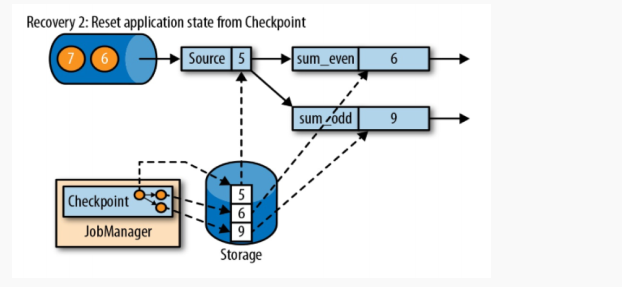
但是当多个并行度进行合并的时候,如上游两个并行度,这两个并行度要将数据进行keyby后分到不同的下游并行度中,这个时候上游的检查点会将数据发送到下游两个检查点中,而下游的每一个并行度会接收到上游的两个检查点。这就涉及到检查点延迟的问题,如图所示:
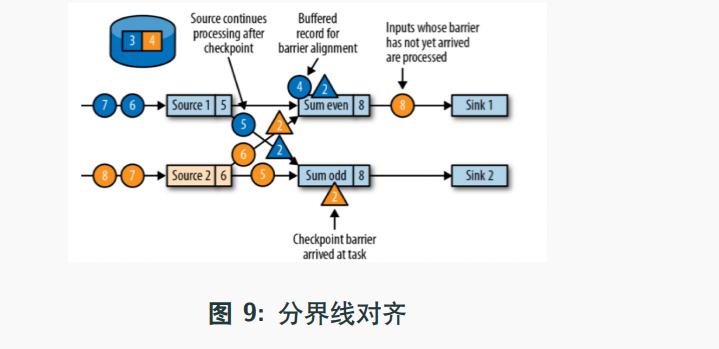
如图所示,蓝色的检查点事件到达后,黄色检查点没到,这就涉及到了检查点屏障,即Checkpoint Barrier ,需要在蓝色和黄色事件都到达后才可以将数据保存到状态后端中,这叫做检查点对齐
但是检查点对其有确定,就是必须要等到检查点全部到达,如果检查点为全部到达,那么 事件就无法继续处理,如上图中的圆形4就无法处理,需要等待检查点来。如果事件太久不能处理,就会导致消息积压,导致太多数据无法处理,最后空间不足报错。
为了规避风险,Flink 1.11版本中通过FLIP-76引入了非对齐检查点(unaligned checkpoint),结果如图所示:
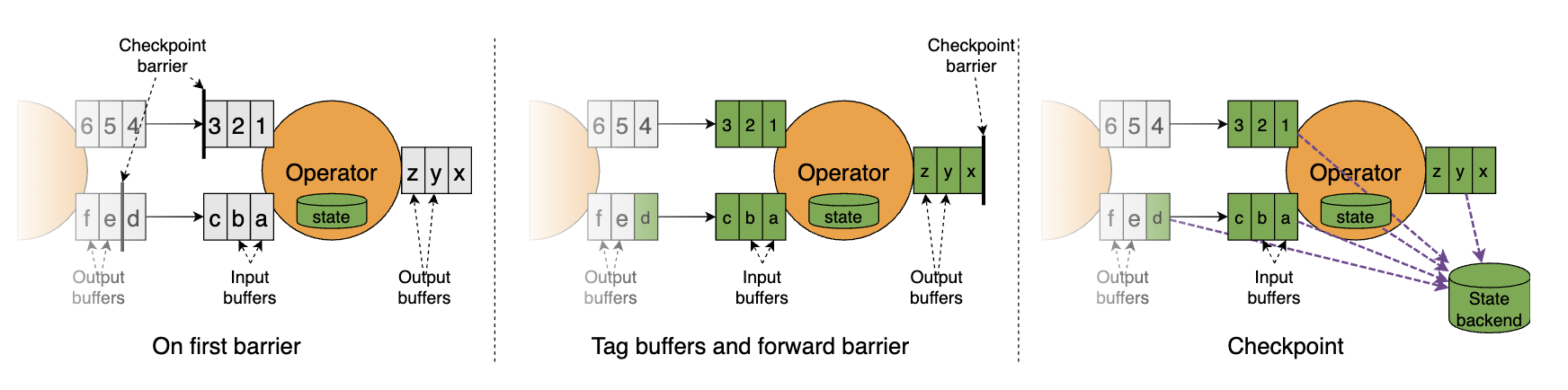
将数据连同算子的状态一起做异步快照。这样需要保存的数据也就变多了,而且当做数据恢复的时候,也会加载到更多的数据,导致恢复时间的增加。
参考文档:Flink新特性之非对齐检查点(unaligned checkpoint)简介
flink如何进行内存管理的
既然flink使用了自己的内存管理,那么就说明jvm内存上面有一定的问题,如:
- java对象存储密度底,任何一个对象,都需要存对象头站16字节。
- full GC影响性能,大数据情况下内存的清理会极具增大
- OOM影响稳定性,产生oom时,会导致jvm奔溃,使得分布式框架的健壮性和性能都会受到影响
为了解决jvm的问题,flink进行了如下的涉及
- 对象存储密度底:涉及flink的自己的内存块:
MemorySegment,默认是32kb,是flink中的最小分配单元 - 对于频繁GC:使用内存池的方式,让内存不用被回收
- 对于OOM:将内存中的数据写入到磁盘上,需要的时候在写入到内存
- 在读取速度方面:Flink 采用类似 DBMS 的 sort 和 join 算法,直接操作二进制数据,从而使序列化/反序列化带来的开销达到最小。
参考文件:
flink的序列化机制
首先思考为什么flink要自己定制一套序列化机制
- java的序列化他冗余,需要保存java的pojo类信息,而保存多余的信息需要额外从空间并且也会增加IO的时间
- 为了迎合底层的内存结构最小单元:
MemorySegment,保证内存的高利用率
如下图展示 一个内嵌型的Tuple3 对象的序列化过程。
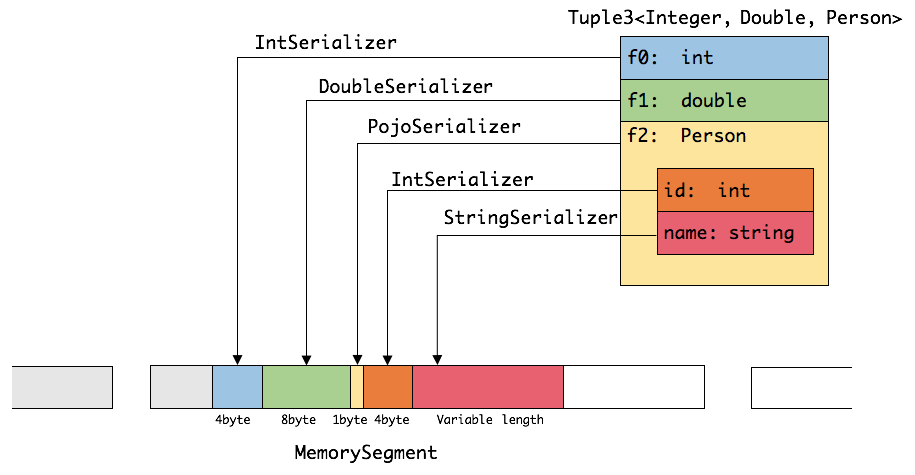
flink的底层定义了自己的数据类型,而每一种数据类型都对应了一种序列化器,在序列化的时候,会将对对应的类型转换使用对应的序列化器进行转换。
这些类型包容如下
java基本类型、java数组类型、hadoop writable实现类、Scala类型、flink元组类型、pojo类型、其他类型
参考:知乎:Flink 原理与实现:内存管理-2017年发布
## flink提交job的方式及参数设置
flink提交job有两种方式:
- 本地提交
- 远程模式
参考参数
bin/flink run \
-t yarn-per-job \
-d \
-p 5 \ 指定并行度
-Dyarn.application.queue=test \ 指定yarn队列
-Djobmanager.memory.process.size=2048mb \ JM2~4G足够
-Dtaskmanager.memory.process.size=4096mb \ 单个TM2~8G足够
-Dtaskmanager.numberOfTaskSlots=2 \ 与容器核数1core:1 slot或2 core:1 slot
-c com.atguigu.flink.tuning.UvDemo \ main方法的类
/opt/module/flink-1.13.1/myjar/flink-tuning-1.0-SNAPSHOT.jar
flink提交作业流程
- 将算子转换为一个有向图:StreamGraph
- 将StreamGraph生成JobGraph,(会将无shuffle的node合并)
- 将JobGraph提交到集群的JobManager,生成和调度 ExecutionGraph
- 将ExecutionGraph概念化得到一张运行图(物理执行图)
flink于yarn的交互
- 客户端上传jar包到hdfs上
- 客户端向Yarn ResourceManager提交任务并申请资源
- ResourceManager分配Container资源并启动ApplicationMaster,然后AppMaster加载Flink的Jar包和配置构建环境,启动JobManager
- ApplicationMaster向ResourceManager申请工作资源,NodeManager加载Flink的Jar包和配置构建环境并启动TaskManager
- TaskManager启动后向JobManager发送心跳包,并等待JobManager向其分配任务

flink的checkpoint机制以及精准一次性消费如何实现
checkpoint机制:参考前面的非barrier对齐
精准一次性消费:
- 在source端,需要source端需要有
可重置读取数据的特点,如kafka的偏移量,即使读取之后也可以从偏移量的位置重复读取 - flink内部:提供了checkpoint和状态后端来保持一致性
- 对应sink方面的比较复杂的
如果sink的输出具有幂等性,如求和,那么可以将数据保存到redis中,每次sink出的时候会替换之前求和的值。
如果是将数据传入到kafka,那么每一条数据都是一条 记录,kafka无法确保数据释放到达国,这个时候需要使用两阶段提交协议(2PC)来 实现精准一次消费
- sink先将任务写入到kafka,但是不提交
- 当所有算子任务的快照完成,也就是这次的 Checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 Checkpoint 完成,此时 Pre-commit 预提交阶段才算完成。即预提交完成
- 第二个阶段:commit 阶段。该阶段中 JobManager 会为应用中每个 Operator 发起 Checkpoint 已完成的回调逻辑。次数sink应该向kafka提交事务
- 如果在一定的时间内kafka没有收到提交的消息,就会将数据抛弃。而既然没有收到提交的消息,就是代表flink出现的问题,状态还没有保存
参考:
腾讯云开发者社区:硬核!八张图搞懂 Flink 端到端精准一次处理语义 Exactly-once(深入原理,建议收藏)
flink的状态有哪些
- 算子状态(Operator State):算子状态的作用范围限定为算
子任务 (不常用) - 键控状态(Keyed State):根据输入数据流中定义的键(key)
来维护和访问
键控状态分为:
- 值状态:每个key只存储一个值
- 列表状态:将状态表示为数据列表
- 字典状态:表示为key-value对
算子状态有有个广播状态(在动态分流的时候会使用到):
- 所有分区的所有数据都会访问到同一个状态,状态就像被“广播”到所有分区一样,这种特殊的算子状态,就叫作广播状态(BroadcastState)
csdn:flink 状态编程(有状态算子、 算子状态(Operator State)、按键分区状态(Keyed State)、状态持久化、状态后端)
什么是Watermark及主要作用
Watermark又称为水位线,他的主要作用就是除了乱序的数据。
flink的实时计算的分布式框架,那么在数据到来的过程中,有些数据可能会因为网络抖动的原理而迟来,而watermark就是为迟到的数据开了有个后门,允许在一定时间内迟到的数据进行处理,进一步的保证了结果的正确性。
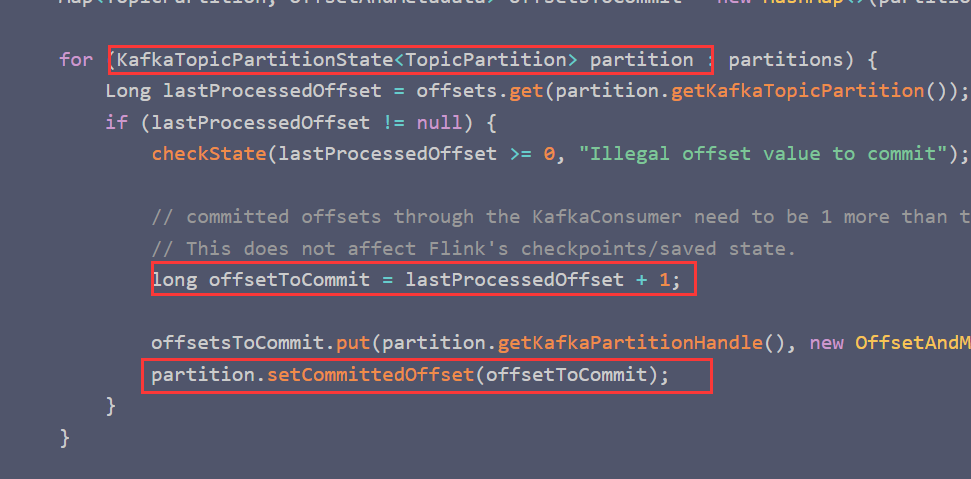
flink如何管理kafka的偏移量,使用什么类型的状态保存offset?
- Checkpointing disabled 完全依赖于kafka自身的API
- Checkpointing enabled 当checkpoint做完的时候,会将offset提交给kafka or zk
flink自定义了状态来管理,这个状态的类叫:KafkaTopicPartitionState
参考:















 4170
4170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









