







 HDFS在添加新节点或数据不均时可能导致负载不平衡。Hadoop提供了一个工具进行数据分布分析和平衡,通过数据均衡算法迭代实现。该算法涉及DataNode的磁盘使用情况分析,按Over、Above、Below、Under四组归类,并迁移数据块以达到集群的均衡状态。启动数据平衡服务可使用start-balancer.sh脚本,并可通过调整配置来优化平衡速度。
HDFS在添加新节点或数据不均时可能导致负载不平衡。Hadoop提供了一个工具进行数据分布分析和平衡,通过数据均衡算法迭代实现。该算法涉及DataNode的磁盘使用情况分析,按Over、Above、Below、Under四组归类,并迁移数据块以达到集群的均衡状态。启动数据平衡服务可使用start-balancer.sh脚本,并可通过调整配置来优化平衡速度。
HDFS负载平衡
HDFS的数据可能并不总是被均匀的置于所有的DataNode中,最常见的原因是向一个已经存在的集群添加一个新的节点。
当放置新的块时(块:一个文件的数据会被存储为一系列的块)。NameNode 在选择DataNode节点存储这些块之前会考虑多方面参数。一些注意事项如下:
策略保证一个块的其中之一个副本在同一个节点(这个节点是块写的节点)
需要将一个块的副本分配到不同的机架上 ,这样可以确保集群丢失整个机架也没有影响
众多副本中的其中之一通常放在文件写入节点的同一个机架上,这样可以减少跨机架的网络I/O
HDFS的数据均匀的分步到一个集群的所有节点中由于多个相互竞争的考虑,整个datanode数据可能不是均匀放置。HDFS为管理员提供了一个工具,分析整个DataNode的块 位置和平衡数据。
Hadoop HDFS数据负载均衡原理
数据均衡过程的核心是一个数据均衡算法,该数据均衡算法将不断迭代数据均衡逻辑,直至集群内数据均衡为止。该数据均衡算法每次迭代的逻辑如下:
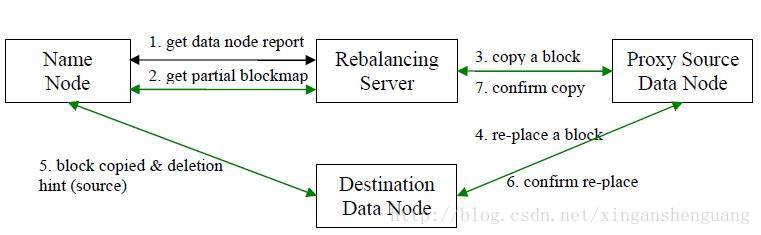
步骤分析如下:
数据均衡服务(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1050
1050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









