









Credit漫谈
在看上一部分的代码时,有一个小细节不知道读者有没有注意到,我们的数据发送端的代码叫做PartittionRequesetQueue.java,而我们的接收端却起了一个完全不相干的名字:CreditBasedPartitionRequestClientHandler.java。为什么前面加了CreditBased的前缀呢?
1 背压问题
在流模型中,我们期待数据是像水流一样平滑的流过我们的引擎,但现实生活不会这么美好。数据的上游可能因为各种原因数据量暴增,远远超出了下游的瞬时处理能力(回忆一下98年大洪水),导致系统崩溃。
那么框架应该怎么应对呢?和人类处理自然灾害的方式类似,我们修建了三峡大坝,当洪水来临时把大量的水囤积在大坝里;对于Flink来说,就是在数据的接收端和发送端放置了缓存池,用以缓冲数据,并且设置闸门阻止数据向下流。
那么Flink又是如何处理背压的呢?答案也是靠这些缓冲池。

这张图说明了Flink在生产和消费数据时的大致情况。ResultPartition和InputGate在输出和输入数据时,都要向NetworkBufferPool申请一块MemorySegment作为缓存池。
接下来的情况和生产者消费者很类似。当数据发送太多,下游处理不过来了,那么首先InputChannel会被填满,然后是InputChannel能申请到的内存达到最大,于是下游停止读取数据,上游负责发送数据的nettyServer会得到响应,停止从ResultSubPartition读取缓存,那么ResultPartition很快也将存满数据不能被消费,从而生产数据的逻辑被阻塞在获取新buffer上,非常自然地形成背压的效果。
Flink自己做了个试验用以说明这个机制的效果:

我们首先设置生产者的发送速度为60%,然后下游的算子以同样的速度处理数据。然后我们将下游算子的处理速度降低到30%,可以看到上游的生产者的数据产生曲线几乎与消费者同步下滑。而后当我们解除限速,整个流的速度立刻提高到了100%。
2 使用Credit实现ATM网络流控
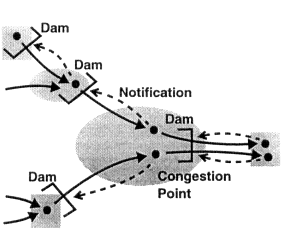
上文已经提到,对于流量控制,一个朴素的思路就是在长江上建三峡链路上建立一个拦截的dam,如下图所示:
基于Credit的流控就是这样一种建立在信用(消费数据的能力)上的,面向每个虚链路(而非端到端的)流模型,如下图所示:
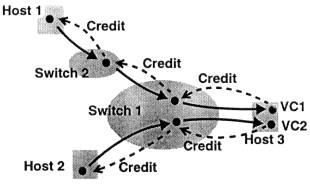
首先,下游会向上游发送一条credit message,用以通知其目前的信用(可联想信用卡的可用额度),然后上游会根据这个信用消息来决定向下游发送多少数据。当上游把数据发送给下游时,它就从下游的信用卡上划走相应的额度(credit balance):

下游总共获得的credit数目是Buf_Alloc,已经消费的数据是Fwd_Cnt,上游发送出来的数据是Tx_Cnt,那么剩下的那部分就是Crd_Bal:
Crd_Bal = Buf_Alloc - ( Tx_Cnt - Fwd_Cnt )
上面这个式子应该很好理解。
可以看到,Credit Based Flow Control的关键是buffer分配。这种分配可以在数据的发送端完成,也可以在接收端完成。对于下游可能有多个上游节点的情况(比如Flink),使用接收端的credit分配更加合理:
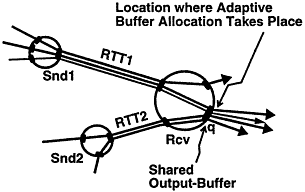
上图中,接收者可以观察到每个上游连接的带宽情况,而上游的节点Snd1却不可能轻易知道发往同一个下游节点的其他Snd2的带宽情况,从而如果在上游控制流量将会很困难,而在下游控制流量将会很方便。
因此,这就是为何Flink在接收端有一个基于Credit的Client,而不是在发送端有一个CreditServer的原因。
最后,再讲一下Credit的面向虚链路的流设计和端到端的流设计的区别:

如上图所示,a是面向连接的流设计,b是端到端的流设计。其中,a的设计使得当下游节点3因某些情况必须缓存数据暂缓处理时,每个上游节点(1和2)都可以利用其缓存保存数据;而端到端的设计b里,只有节点3的缓存才可以用于保存数据(读者可以从如何实现上想想为什么)。















 231
231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









