










 本文介绍了一个基于人脸识别的项目——AdaFace,并提供了详细的步骤指导如何准备大规模数据集MS1M-ArcFace,包括从下载到预处理的过程。文章还分享了转换记录文件、创建图像与标签对应文件的具体代码。
本文介绍了一个基于人脸识别的项目——AdaFace,并提供了详细的步骤指导如何准备大规模数据集MS1M-ArcFace,包括从下载到预处理的过程。文章还分享了转换记录文件、创建图像与标签对应文件的具体代码。
这章节我会讲解的是我在工作上的项目,人脸识别adaface,以下的讲解为个人的看法,若有地方说错的我会第一时间纠正,如果觉得博主讲解的还可以的话点个赞,就是对我最大的鼓励~
github代码下载链接:https://github.com/mk-minchul/AdaFace
论文地址:https://arxiv.org/abs/2204.00964
接下来,我们根据官方所述,下载MS1M-ArcFace (85K ids/5.8M images) [5,7]数据集:
https://github.com/deepinsight/insightface/tree/master/recognition/datasets
该数据集有85000个id,有580万+张图片,可以说数据集是相当之大的。
数据下载完之后我们存放到工程文件中,现在我们要对该数据集进行制作,因为下载下来不能直接训练,因此需要做以下处理:
第一:我们将train.rec文件的图片给读取出来,放置到一个文件夹当中,之后制作一个图片和标签对应的一个txt文件,该脚本已提供,我们按照他的脚本运行,时间有点长,需要大家耐心等待,出来的图片有580万+张,有8.5w个文件夹,制作数据集脚本、结果如下:
from pathlib import Path
import argparse
import mxnet as mx
from tqdm import tqdm
from PIL import Image
import bcolz
import pickle
import cv2
import numpy as np
from torchvision import transforms as trans
import os
import numbers
def save_rec_to_img_dir(rec_path, save_correct_channel_order=False, save_as_png=False):
save_path = rec_path/'imgs'
if not save_path.exists():
save_path.mkdir()
imgrec = mx.recordio.MXIndexedRecordIO(str(rec_path/'train.idx'), str(rec_path/'train.rec'), 'r')
img_info = imgrec.read_idx(0)
header,_ = mx.recordio.unpack(img_info)
max_idx = int(header.label[0])
for idx in tqdm(range(1,max_idx)):
img_info = imgrec.read_idx(idx)
header, img = mx.recordio.unpack_img(img_info)
if not isinstance(header.label, numbers.Number):
label = int(header.label[0])
else:
label = int(header.label)
if save_correct_channel_order:
# this option saves the image in the right color.
# but the training code uses PIL (RGB)
# and validation code uses Cv2 (BGR)
# so we want to turn this off to deliberately swap the color channel order.
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
img = Image.fromarray(img)
label_path = save_path/str(label)
if not label_path.exists():
label_path.mkdir()
if save_as_png:
img_save_path = label_path/'{}.png'.format(idx)
img.save(img_save_path)
else:
img_save_path = label_path/'{}.jpg'.format(idx)
img.save(img_save_path, quality=95)
def load_bin(path, rootdir, image_size=[112,112]):
test_transform = trans.Compose([
trans.ToTensor(),
trans.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
if not rootdir.exists():
rootdir.mkdir()
bins, issame_list = pickle.load(open(path, 'rb'), encoding='bytes')
data = bcolz.fill([len(bins), 3, image_size[0], image_size[1]], dtype=np.float32, rootdir=rootdir, mode='w')
for i in range(len(bins)):
_bin = bins[i]
img = mx.image.imdecode(_bin).asnumpy()
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
img = Image.fromarray(img.astype(np.uint8))
data[i, ...] = test_transform(img)
i += 1
if i % 1000 == 0:
print('loading bin', i)
print(data.shape)
np.save(str(rootdir)+'_list', np.array(issame_list))
return data, issame_list
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='for face verification')
parser.add_argument("-r", "--rec_path", help="mxnet record file path", default='./faces_emore', type=str)
args = parser.parse_args()
rec_path = Path(args.rec_path)
save_rec_to_img_dir(rec_path)
# bin_files = ['agedb_30', 'cfp_fp', 'lfw', 'calfw', 'cfp_ff', 'cplfw', 'vgg2_fp']
bin_files = list(filter(lambda x: os.path.splitext(x)[1] in ['.bin'], os.listdir(args.rec_path)))
bin_files = [i.split('.')[0] for i in bin_files]
for i in range(len(bin_files)):
load_bin(rec_path/(bin_files[i]+'.bin'), rec_path/bin_files[i])
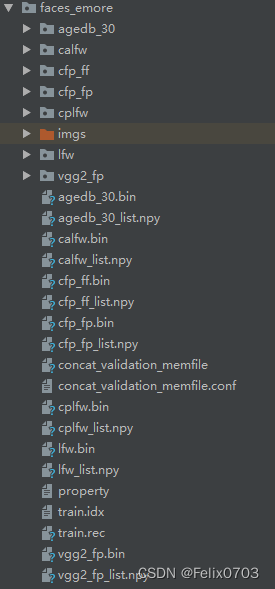
生成的npy文件为我们测试集用到的数据集,真正训练的就只有train.rec这个文件,其他的都是测试集。
有一点注意的是,我们需要将rec文件里面的图片转成bgr形式,因为里面读取出来的图片格式是rgb的,我们放进去训练的时候需要是bgr的所以要转换一下,
img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)

















 2371
2371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









