






离线数仓搭建
😀首先本文章只负责怎么去搭建,而不负责怎么讲解详细的内容需要详细内容请前往:
离线数仓6.0
请先把Hadoop全家桶搭建完毕:
阿里云安装Hadoop基础
1.开始文件准备和准备工作

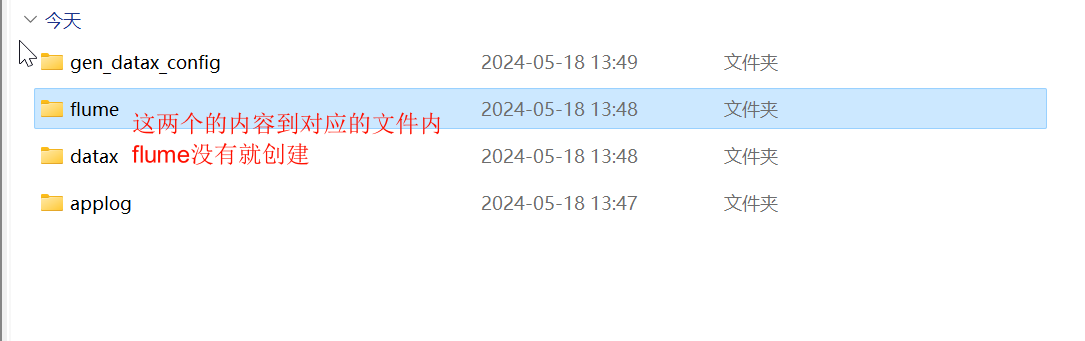
命令脚本记得给权限,参考脚本
#!/bin/bash
# 获取当前目录下所有以 .sh 结尾的脚本文件
scripts=$(ls *.sh)
# 给每个脚本赋予执行权限
for script in $scripts; do
chmod 777 "$script"
echo "已给予 $script 执行权限"
done
echo "所有脚本已批量赋予执行权限"
记得给权限
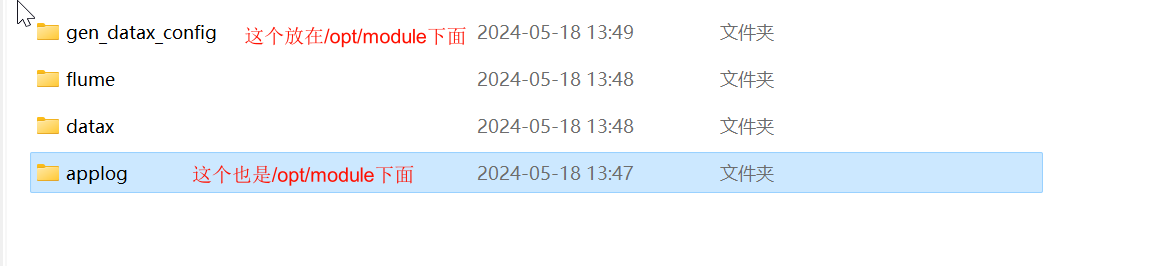
这三个不用管,所以开始前我们需要确定有这些文件和配置
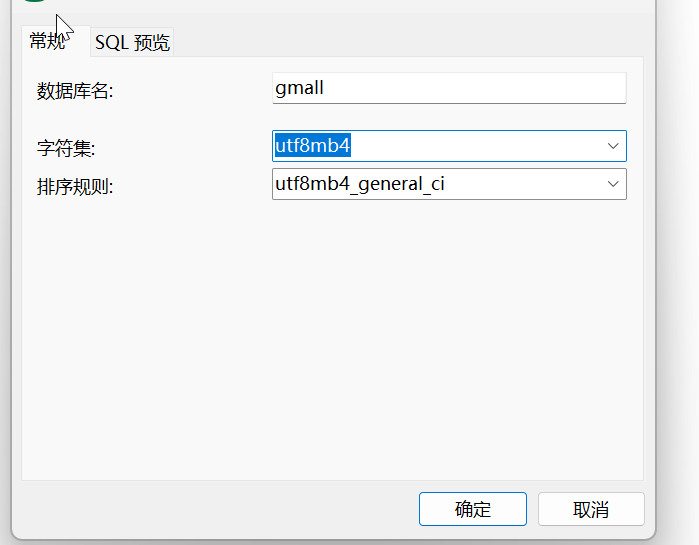
2.MySQL建表
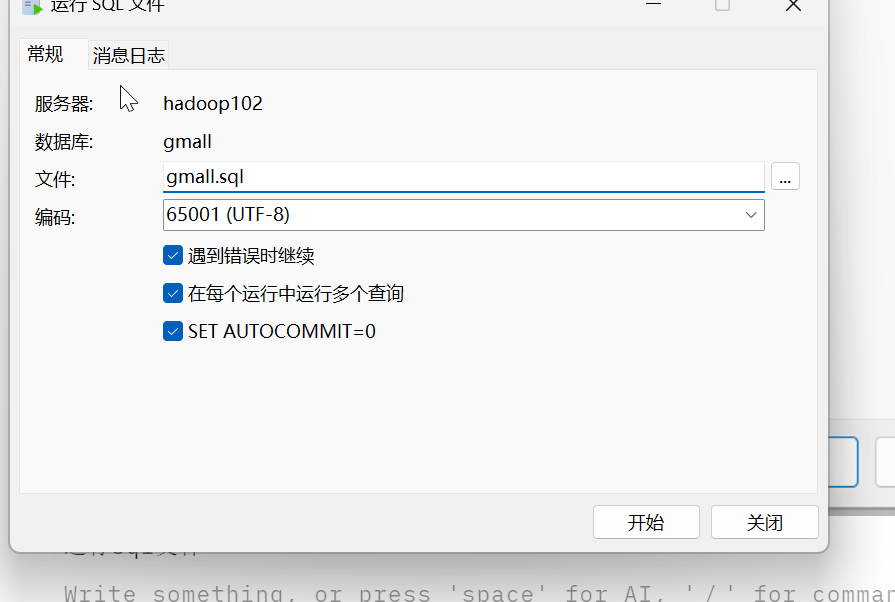
创建一个数据库gmall
运行sql文件

为Maxwell进行MySQL的配置
sudo vim /etc/my.cnf
#数据库id
server-id = 1
#启动binlog,该参数的值会作为binlog的文件名
log-bin=mysql-bin
#binlog类型,maxwell要求为row类型
binlog_format=row
#启用binlog的数据库,需根据实际情况作出修改
binlog-do-db=gmall
创建数据库
CREATE DATABASE maxwell;
CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';
修改Maxwell配置文件
cd /opt/module/maxwell
cp config.properties.example config.properties
vim config.properties
#Maxwell数据发送目的地,可选配置有stdout|file|kafka|kinesis|pubsub|sqs|rabbitmq|redis
producer=kafka
# 目标Kafka集群地址
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#目标Kafka topic,可静态配置,例如:maxwell,也可动态配置,例如:%{database}_%{table}
kafka_topic=topic_db
# MySQL相关配置
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
# 过滤gmall中的z_log表数据,该表是日志数据的备份,无须采集
filter=exclude:gmall.z_log
# 指定数据按照主键分组进入Kafka不同分区,避免数据倾斜
producer_partition_by=primary_key
3.数据同步
3.1 Datax设置
cd /opt/module/gen_datax_config
vim configuration.properties
mysql.username=root
mysql.password=000000
mysql.host=hadoop102
mysql.port=3306
mysql.database.import=gmall
mysql.tables.import=activity_info,activity_rule,base_trademark,cart_info,base_category1,base_category2,base_category3,coupon_info,sku_attr_value,sku_sale_attr_value,base_dic,sku_info,base_province,spu_info,base_region,promotion_pos,promotion_refer
is.seperated.tables=0
hdfs.uri=hdfs://hadoop102:8020
import_out_dir=/opt/module/datax/job/import
执行
java -jar datax-config-generator-1.0-SNAPSHOT-jar-with-dependencies.jar
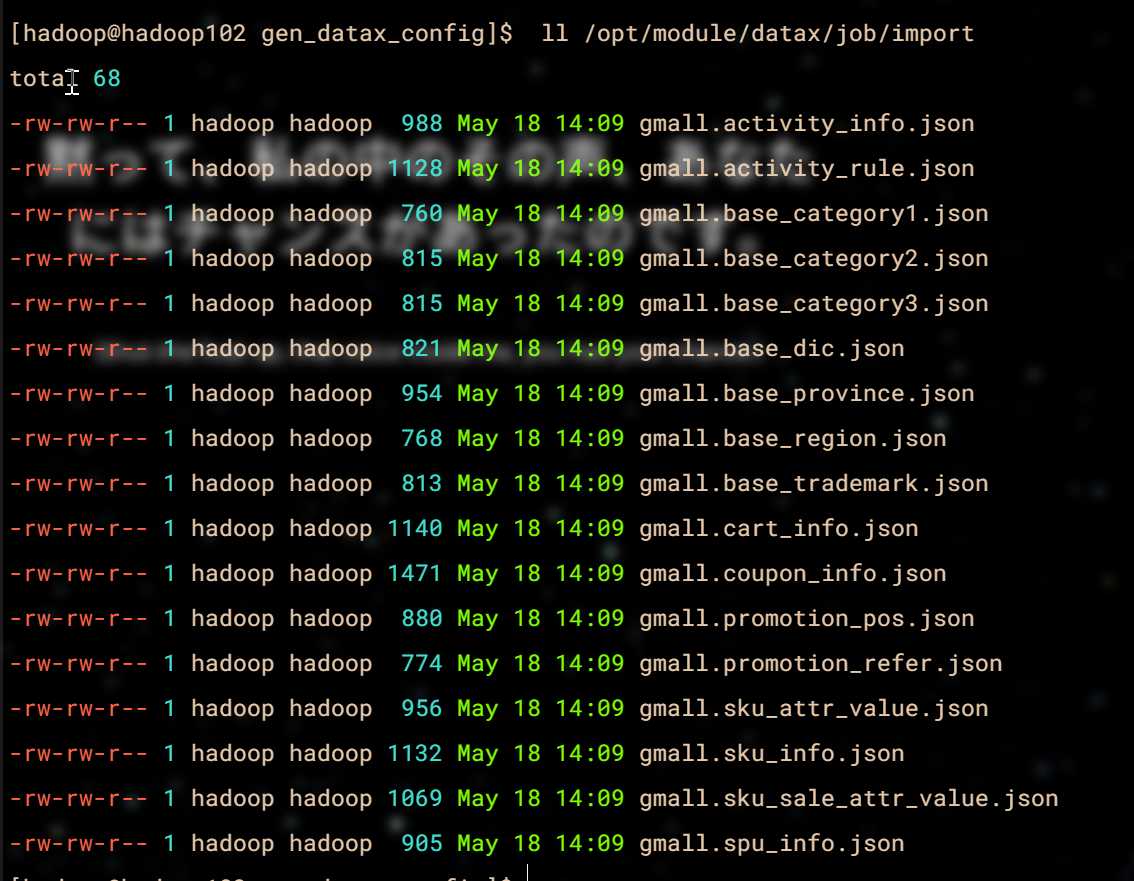
ll /opt/module/datax/job/import
3.2 全量表同步
mysql_to_hdfs_full.sh all 2022-06-08
等一会时间,让数据跑一会
我们会发现多出来17张表
3.3增量表同步
vim /opt/module/maxwell/config.properties
mock_date=2022-06-08
mxw.sh start
mysql_to_kafka_inc_init.sh all
观察发现
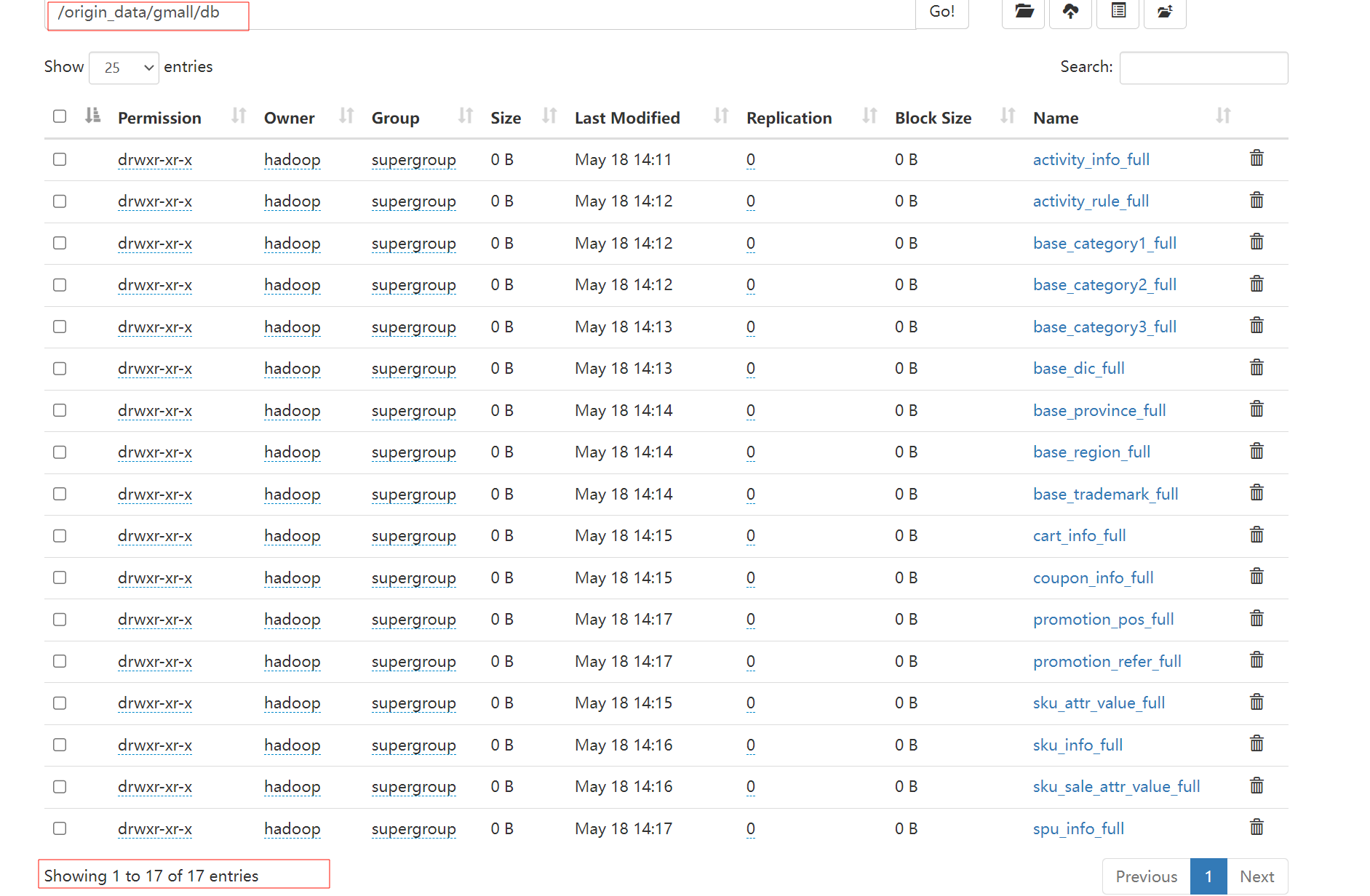
多出来13张表,也就是说,现在有30张表
4 数据模拟准备
4.1.先将HDFS上/origin_data路径下之前的数据删除
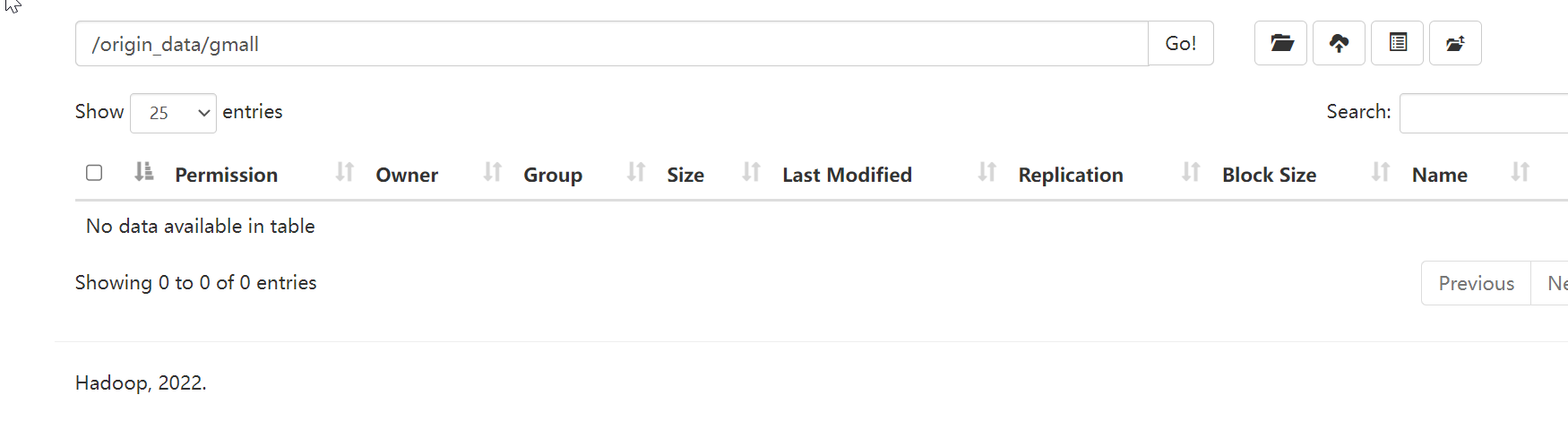
4.2.数据准备
vim application.yml
cluster.sh
mxw.sh stop
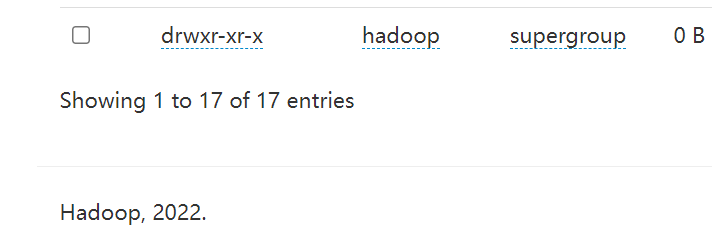
运行lg.sh模拟数据
接下来将修改为
#业务日期
mock.date: "2022-06-05"
#是否重置业务数据
mock.clear.busi: 0
#是否重置用户数据
mock.clear.user: 0
# 批量生成新用户
mock.new.user: 0
再次运行lg.sh
到后面将时间修改为06,07分别运行lg.sh
4.3.删除/origin_data/gmall/log目录
将时间修改为08并执行lg.sh

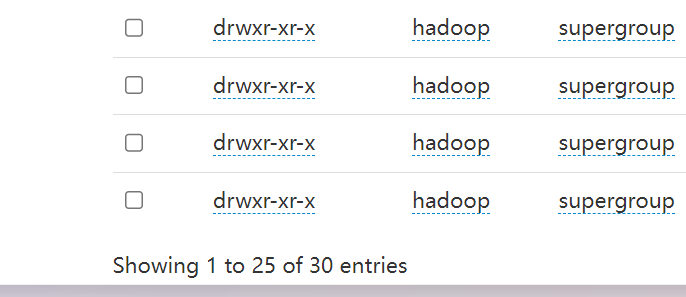
4.4.全量表同步
mysql_to_hdfs_full.sh all 2022-06-08

4.5.清空MySQL中的maxwell数据库的表
use maxwell;
drop table maxwell.bootstrap;
drop table maxwell.columns;
drop table maxwell.databases;
drop table maxwell.heartbeats;
drop table maxwell.positions;
drop table maxwell.schemas;
drop table maxwell.tables;
vim /opt/module/maxwell/config.properties
启动Maxwell
mysql_to_kafka_inc_init.sh all
4.6.DataGrip 中注释乱码问题
use metastore;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
5.Hive表的创建
5.1 ODS
执行ods.sql的内容
然后执行下面命令
hdfs_to_ods_log.sh 2022-06-08
5.2 DIM
执行DIM.sql
1.先执行到这两个线条上面,然后上传date_info.txt到/warehouse/gmall/tmp/tmp_dim_date_info
hadoop fs -put date_info.txt /warehouse/gmall/tmp/tmp_dim_date_info
其余的直接执行
5.3 DWD
执行dwd.sql
5.4 DWS
执行dws.sql
5.5 ADS
执行ads.sql
5.6 MySQL创建表
执行MySQL建库建表.sql
5.7 报表导出
5.7.1 编写DataX
vim /opt/module/gen_datax_config/configuration.properties
mysql.username=root
mysql.password=000000
mysql.host=hadoop102
mysql.port=3306
mysql.database.import=gmall
# 从HDFS导出进入的 MySQL 数据库名称
mysql.database.export=gmall_report
mysql.tables.import=activity_info,activity_rule,base_trademark,cart_info,base_category1,base_category2,base_category3,coupon_info,sku_attr_value,sku_sale_attr_value,base_dic,sku_info,base_province,spu_info,base_region,promotion_pos,promotion_refer
# MySQL 库中需要导出的表,空串表示导出库的所有表
mysql.tables.export=
is.seperated.tables=0
hdfs.uri=hdfs://hadoop102:8020
import_out_dir=/opt/module/datax/job/import
# DataX 导出配置文件存放路径
export_out_dir=/opt/module/datax/job/export
cd **/opt/module/gen_datax_config**
java -jar datax-config-generator-1.0-SNAPSHOT-jar-with-dependencies.jar
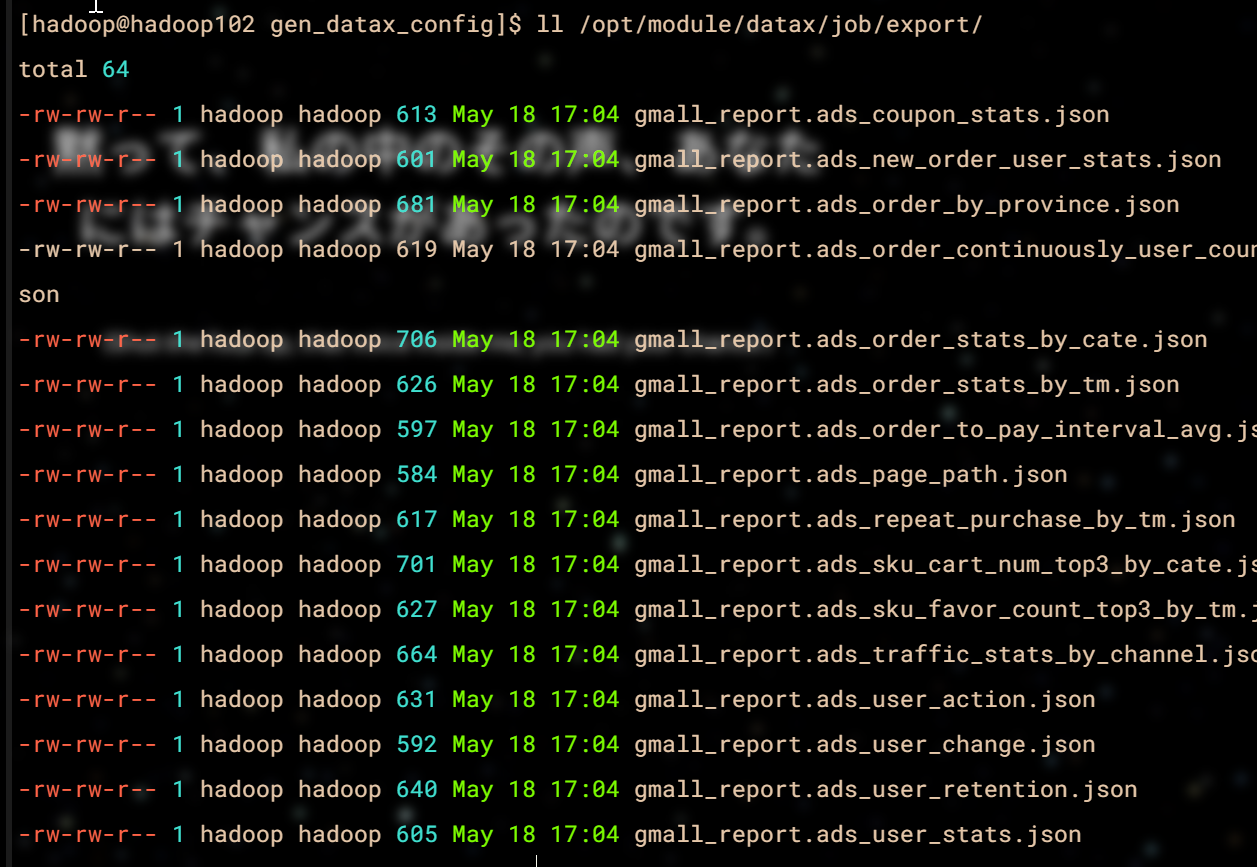
ll /opt/module/datax/job/export/
6.最终数据的开始
注意:对自己机器有信心的话,直接执行脚本,没信心的话,执行一个,重启或者等待几分钟执行下一个
6.1 修改时间
vim /opt/module/applog/application.yml
6.2 启动全部进程
cd /home/hadoop/bin/
cluster.sh start
hi.sh start
查看进程:

6.3 开始
lg.sh
./yxhHDFS.sh 2022-06-09
等吧,每个半个小时起步或者一个小时,是搞不定的
7.可视化报表
7.1安装Miniconda
下载
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
执行
bash Miniconda3-latest-Linux-x86_64.sh
指定安装路径 /opt/module/miniconda3
添加环境变量和刷新一遍,然后在关闭窗口重新开一遍
取消激活base环境
conda config --set auto_activate_base false
创建环境
conda create --name superset python=3.8.16
conda activate superset
python -V
7.2下载依赖
sudo yum install -y gcc gcc-c++ libffi-devel python-devel python-pip python-wheel python-setuptools openssl-devel cyrus-sasl-devel openldap-devel
更新pip
pip install --upgrade pip -i https://pypi.douban.com/simple/
上传base.txt到任意目录下,且cd到该目录
安装superset
pip install apache-superset==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple -r base.txt
7.3配置Superset元数据库
CREATE DATABASE superset DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
create user superset@'%' identified WITH mysql_native_password BY 'superset';
grant all privileges on *.* to superset@'%' with grant option;
修改superset配置文件
更具自己的地址来修改
vim /home/hadoop/.conda/envs/superset/lib/python3.8/site-packages/superset/config.py
vim中查找方法
?SQLALCHEMY_DATABASE_URI
执行两次就到我们需要的位置
# SQLALCHEMY_DATABASE_URI = "sqlite:///" + os.path.join(DATA_DIR, "superset.db")
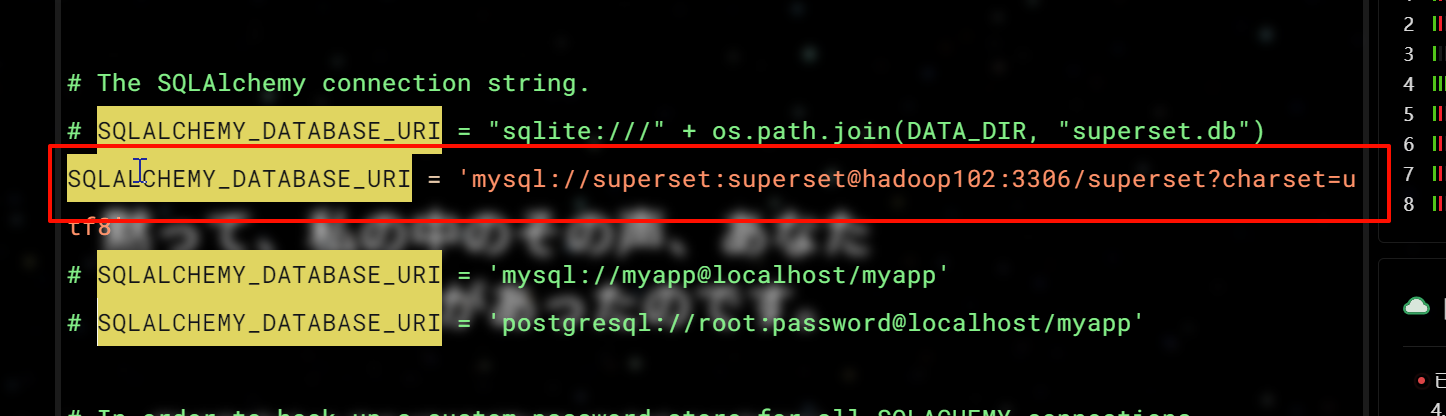
SQLALCHEMY_DATABASE_URI = 'mysql://superset:superset@hadoop102:3306/superset?charset=utf8'
7.4安装python msyql驱动
conda install mysqlclient
export FLASK_APP=superset
superset db upgrade
SupersetSet初始化
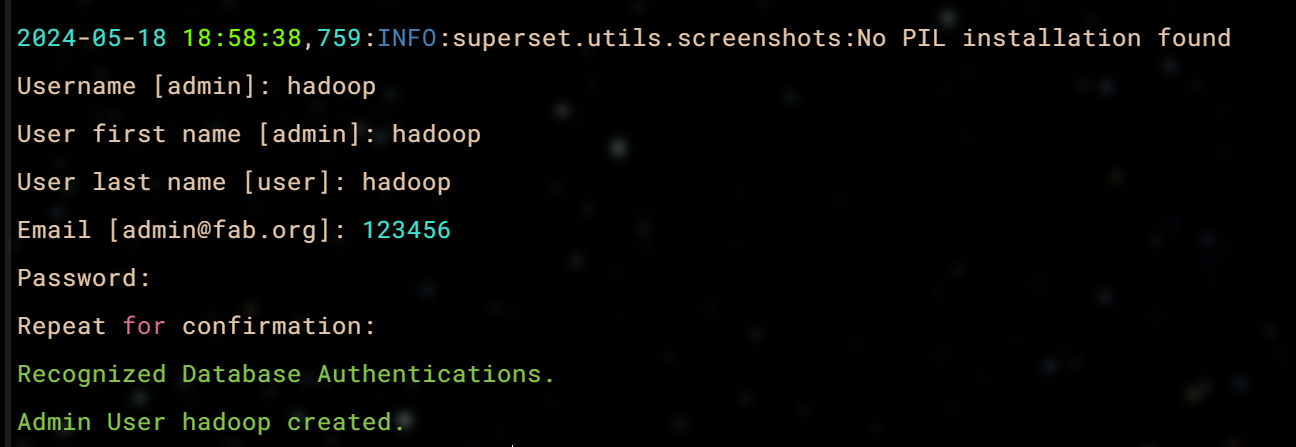
superset fab create-admin
superset init
pip install gunicorn -i https://pypi.douban.com/simple/
随便输入记得住就行
启动
superset.sh start
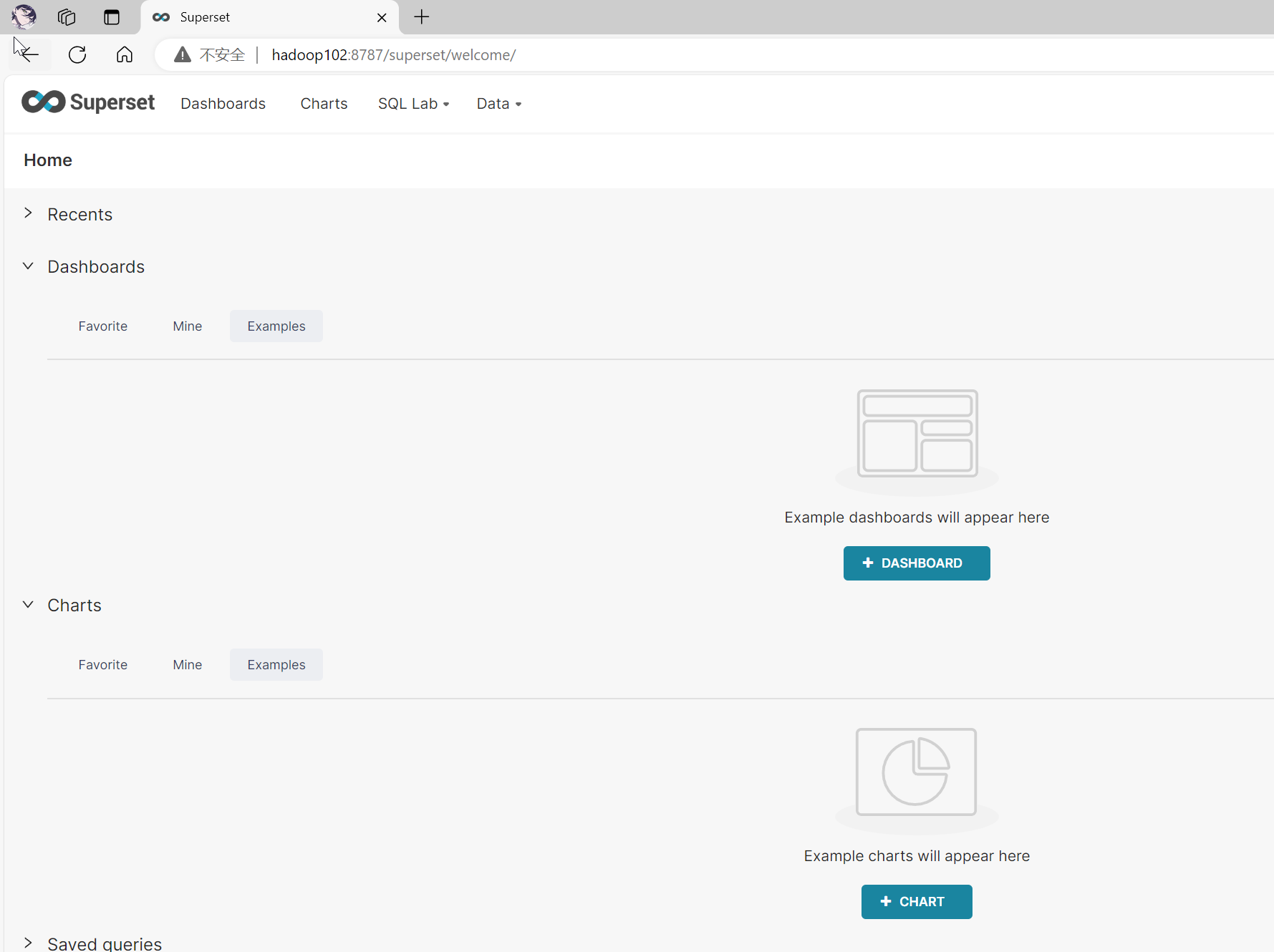
当当进来了
8. 开始绘图
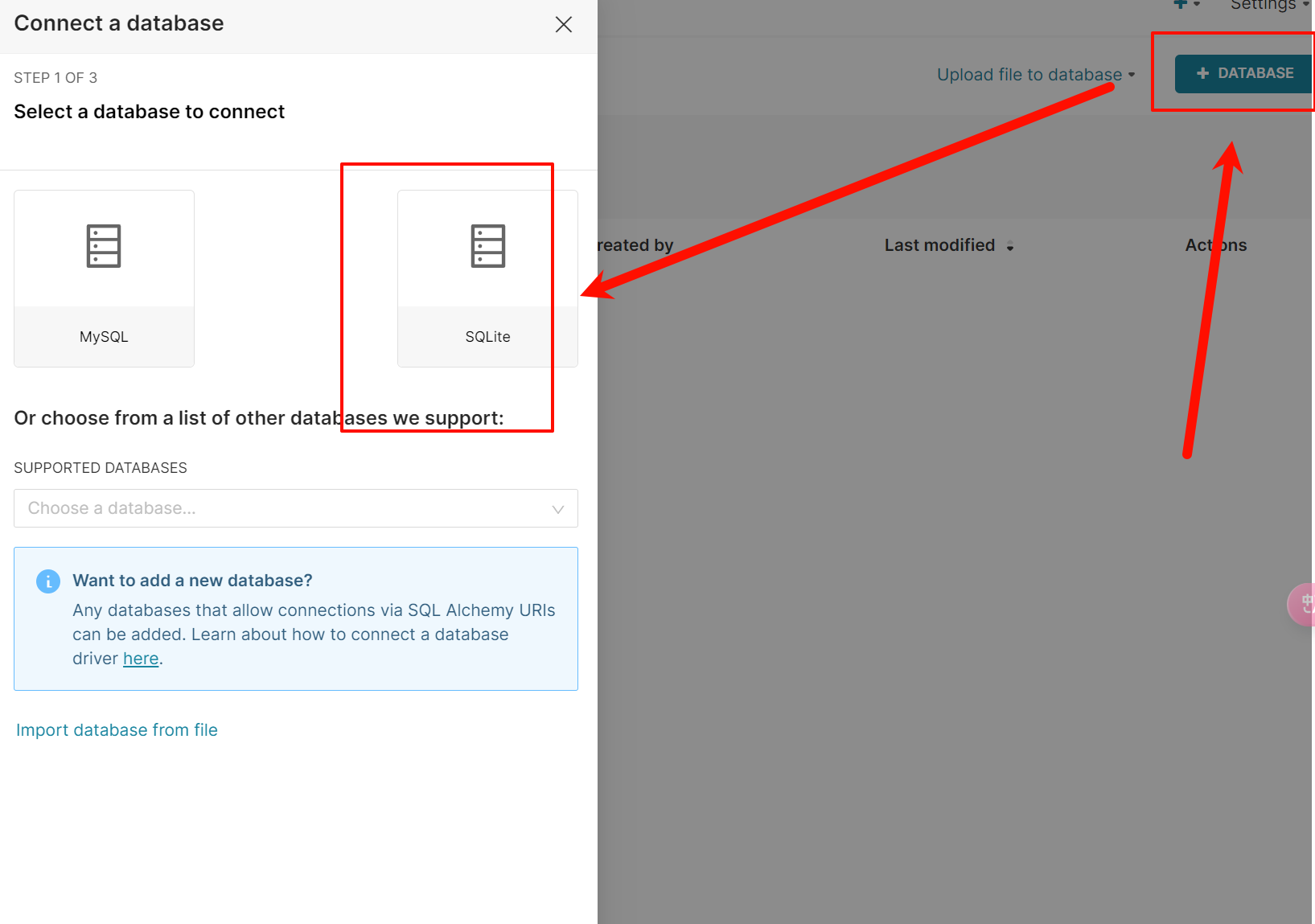
8.1 配置数据源
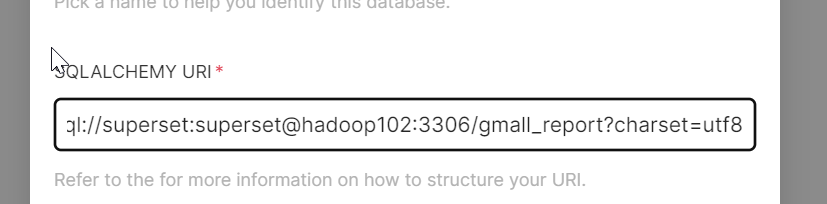
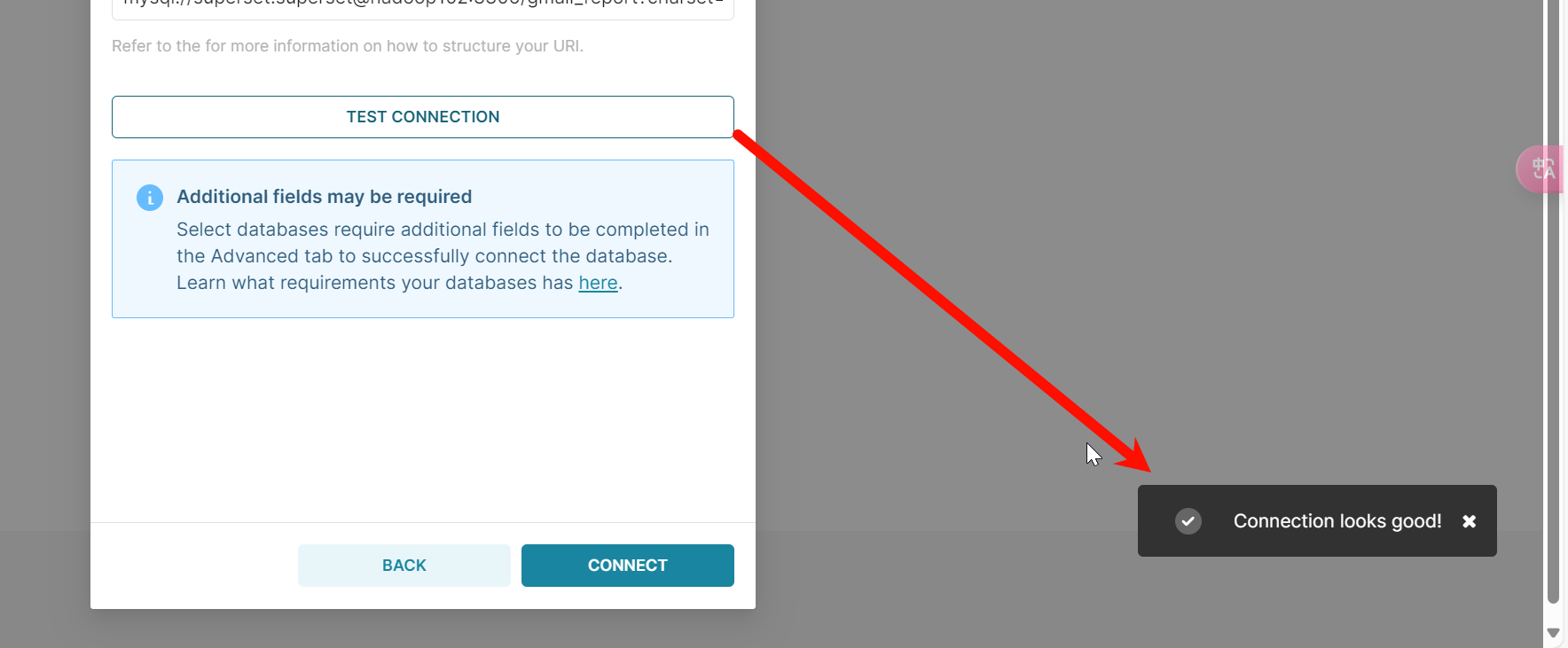
mysql://superset:superset@hadoop102:3306/gmall_report?charset=utf8
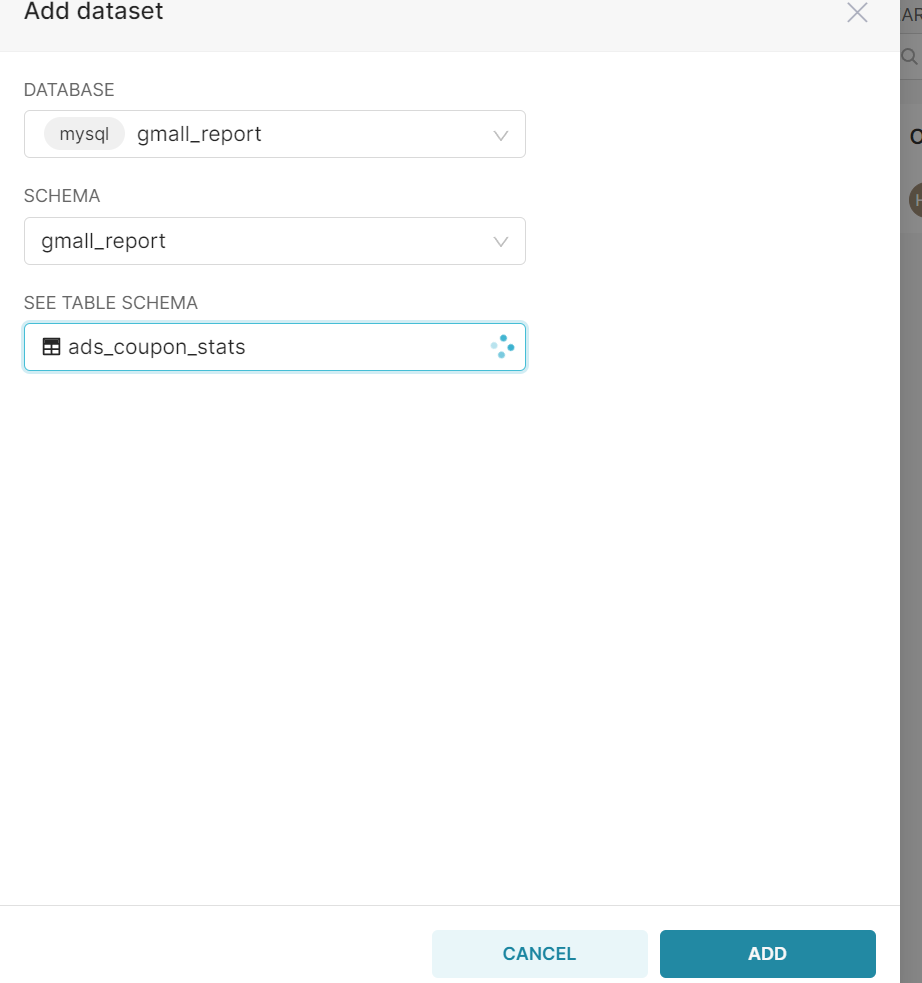
**Table配置**
按需求添加自己需要的

开始绘图
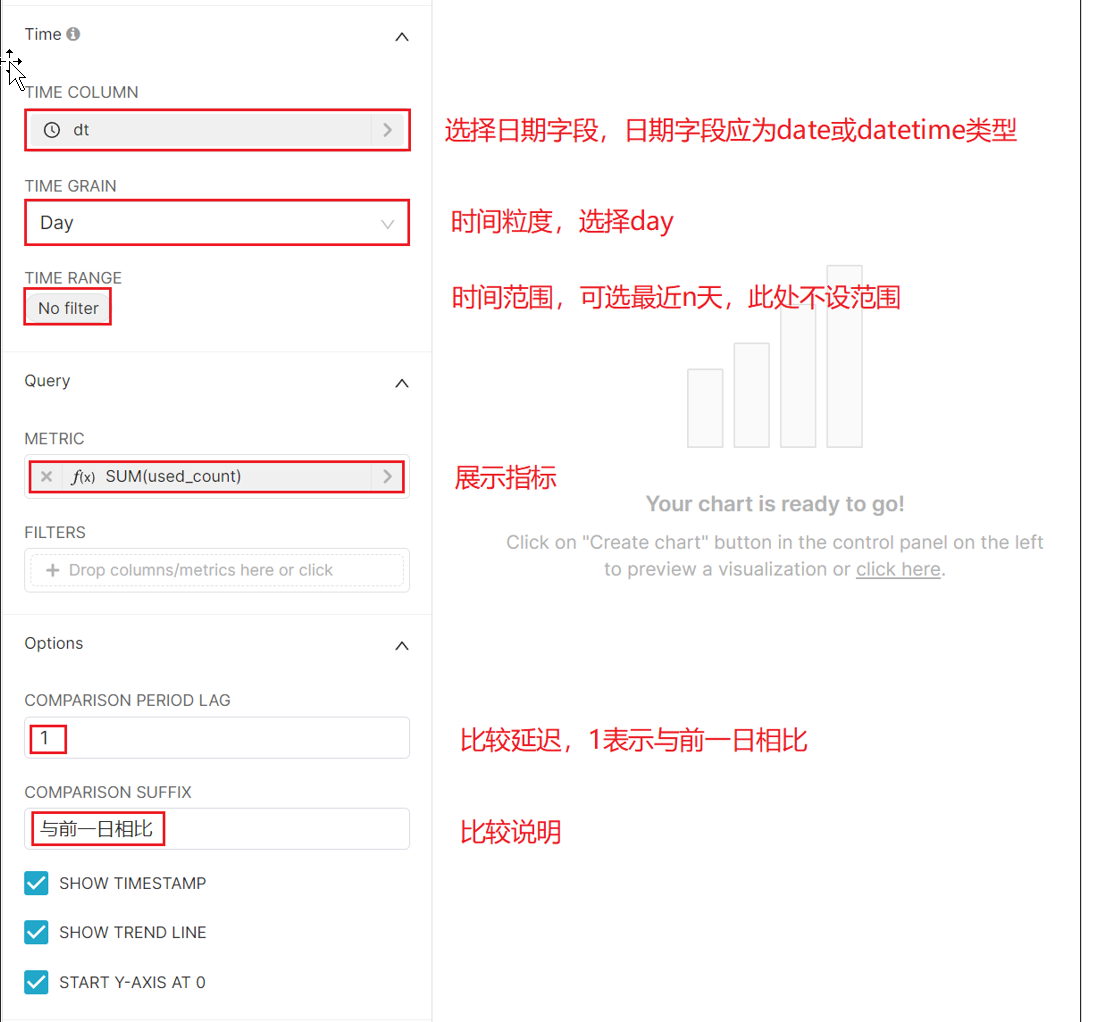
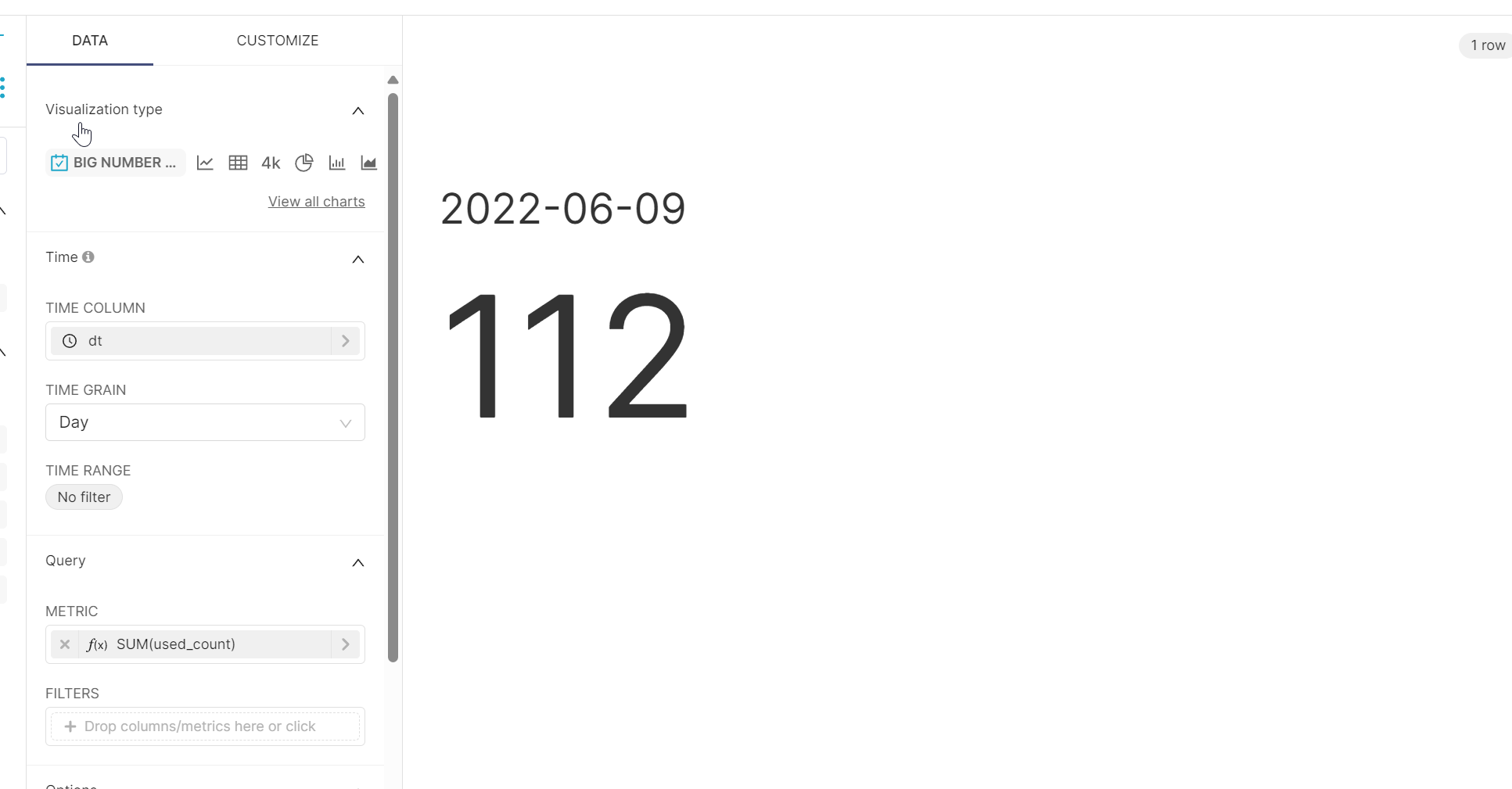
我没跑数据,所以就这一点
剩下的图
全国图:

品牌下单统计图:
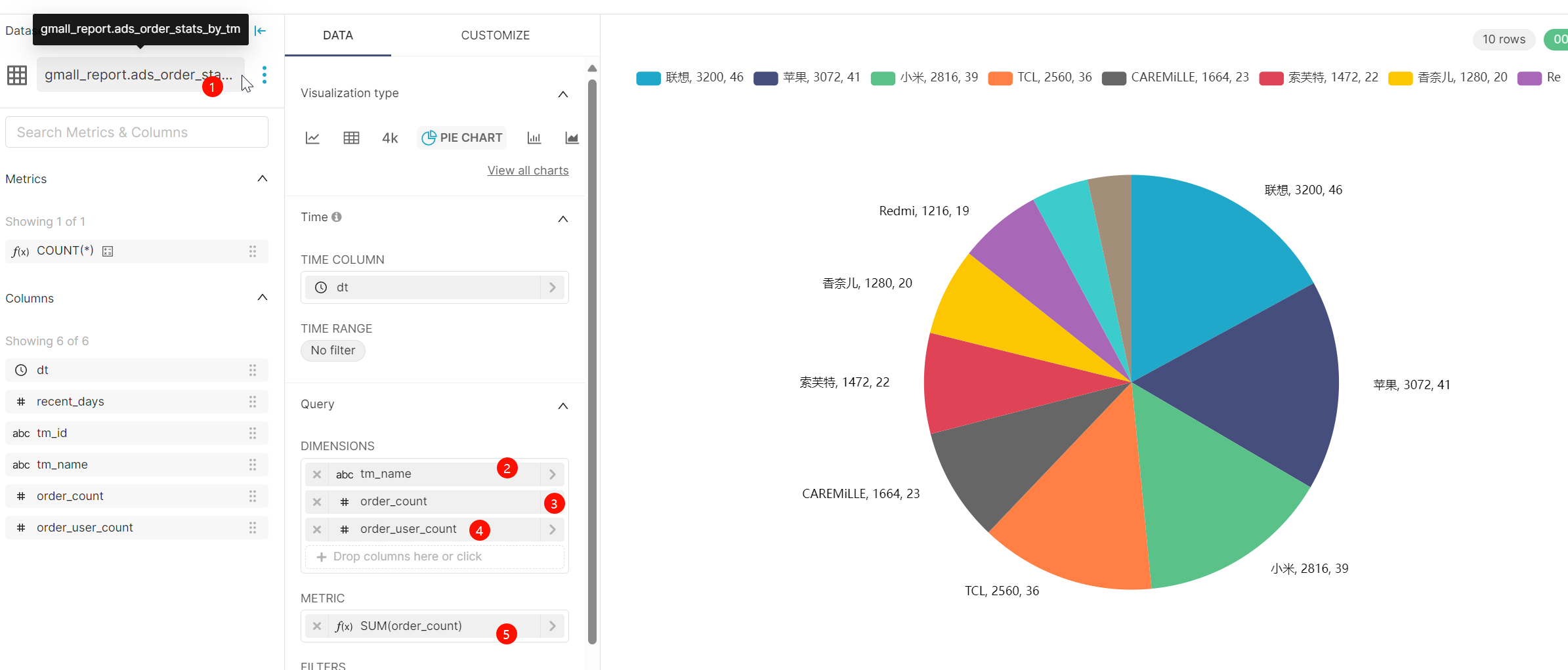
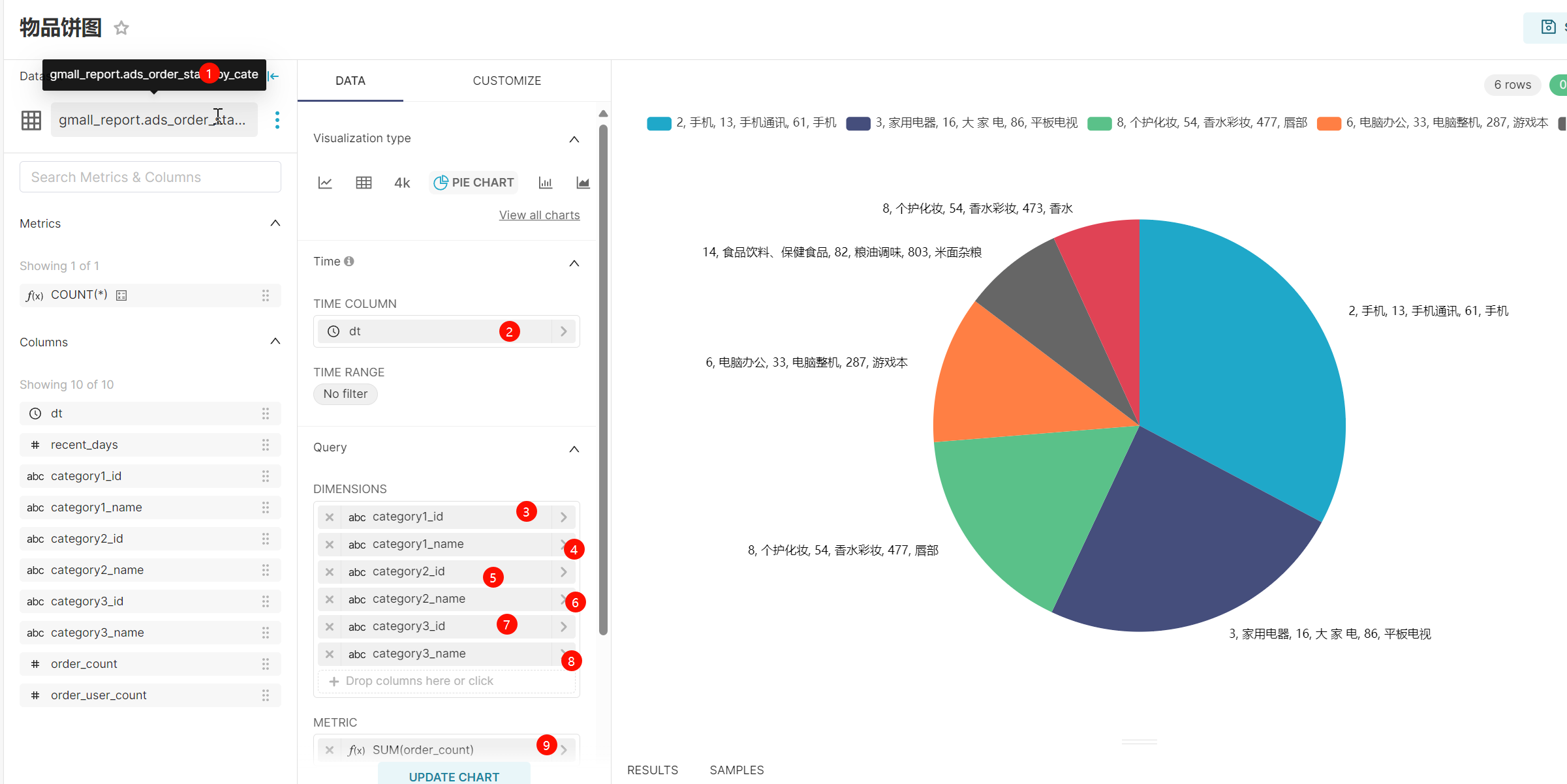
物品饼图:















 1642
1642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









