







Redis 的特性:
-
更丰富的数据类型
-
进程内与跨进程;单机与分布式
-
功能丰富:持久化机制、过期策略
-
支持多种编程语言
-
高可用,集群
Redis 一共有几种数据类型?(注意是数据类型不是数据结构)
String、Hash、Set、List、Zset、Hyperloglog、Geo、Streams
Redis 基本数据类型
-
String 字符串 (可以用来存储字符串、整数、浮点数 )
-
操作命令
设置多个值(批量操作,原子性)
mset qingshan 2673 jack 666设置值,如果 key 存在,则不成功
setnx qingshan基于此可实现分布式锁。用 del key 释放锁。 但如果释放锁的操作失败了,导致其他节点永远获取不到锁,怎么办? 加过期时间。单独用 expire 加过期,也失败了,无法保证原子性,怎么办?多参数
set key value [expiration EX seconds|PX milliseconds][NX|XX]使用参数的方式
set lock1 1 EX 10 NX(整数)值递增
incr qingshan incrby qingshan 100(整数)值递减
decr qingshan decrby qingshan 100浮点数增量
set f 2.6 incrbyfloat f 7.3获取多个值
mget qingshan jack获取值长度
strlen qingshan字符串追加内容
append qingshan good获取指定范围的字符
getrange qingshan 0 8 -
存储(实现)原理
数据模型
set hello word 为例,因为 Redis 是 KV 的数据库,它是通过 hashtable 实现的(我 们把这个叫做外层的哈希)。所以每个键值对都会有一个 dictEntry(源码位置:dict.h), 里面指向了 key 和 value 的指针。next 指向下一个 dictEntry
typedef struct dictEntry { void *key; /* key 关键字定义 */ union { void *val; uint64_t u64; /* value 定义 */ int64_t s64; double d; } v; struct dictEntry *next; /* 指向下一个键值对节点 */ } dictEntry;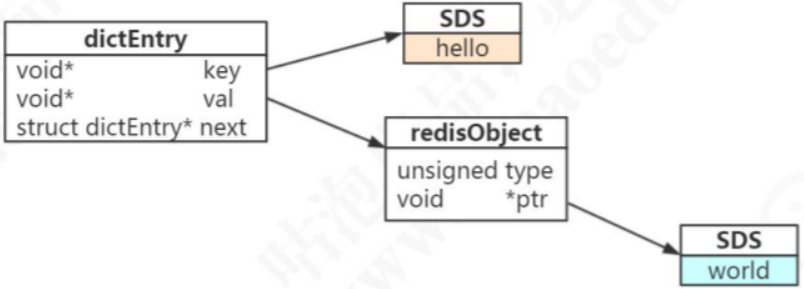
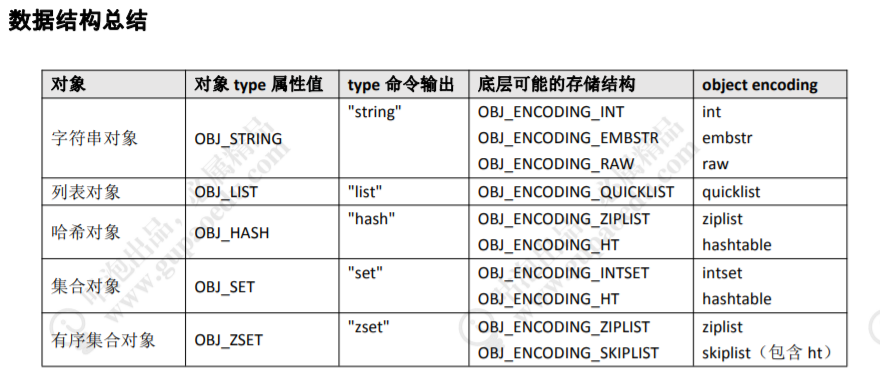
key 是字符串,但是 Redis 没有直接使用 C 的字符数组,而是存储在自定义的 SDS 中。 value 既不是直接作为字符串存储,也不是直接存储在 SDS 中,而是存储在 redisObject 中。实际上五种常用的数据类型的任何一种,都是通过 redisObject 来存储 的。
redisObject
redisObject 定义在 src/server.h 文件中
typedef struct redisObject { unsigned type:4; /* 对象的类型,包括:OBJ_STRING、OBJ_LIST、OBJ_HASH、OBJ_SET、OBJ_ZSET */ unsigned encoding:4; /* 具体的数据结构 */ unsigned lru:LRU_BITS; /* 24 位,对象最后一次被命令程序访问的时间,与内存回收有关 */ int refcount; /* 引用计数。当 refcount 为 0 的时候,表示该对象已经不被任何对象引用,则可以进行垃圾回收了 */ void *ptr; /* 指向对象实际的数据结构 */ } robj; -
应用场景
-
缓存
String 类型
热点数据缓存(例如报表,明星出轨),对象缓存,全页缓存。 可以提升热点数据的访问速度。
-
数据共享分布式
String 类型,因为 Redis 是分布式的独立服务,可以在多个应用之间共享 ,
例如:分布式 Session ,只需要引入spring-session-data-redis的依赖即可使用
<dependency> <groupId>org.springframework.session</groupId> <artifactId>spring-session-data-redis</artifactId> </dependency> -
分布式锁
String 类型 setnx 方法,只有不存在时才能添加成功,返回 true。
http://redisdoc.com/string/set.html 建议用参数的形式
SET key value [EX seconds] [PX milliseconds] [NX|XX]- EX seconds : 将键的过期时间设置为 seconds 秒。 执行 SET key value EX seconds 的效果等同于执行 SETEX key seconds value 。
- PX milliseconds : 将键的过期时间设置为 milliseconds 毫秒。 执行 SET key value PX milliseconds 的效果等同于执行 PSETEX key milliseconds value 。
- NX : 只在键不存在时, 才对键进行设置操作。 执行 SET key value NX 的效果等同于执行 SETNX key value 。
- XX : 只在键已经存在时, 才对键进行设置操作。
//基于Jedis实现分布式锁,使用带参数的那种 public Boolean getLock(Object lockObject){ jedisUtil = getJedisConnetion(); //只用当设置成功后,才可以获取锁 boolean flag = jedisUtil.setNX(lockObj, 1); if(flag){ expire(locakObj,10); } return flag; } public void releaseLock(Object lockObject){ del(lockObj); } -
全局 ID
INT 类型,INCRBY,利用原子性
incrby userid 1000 -
计数器
int 类型,INCR 方法
incr onclick例如:文章的阅读量,微博点赞数,允许一定的延迟,先写入 Redis 再定时同步到 数据库。
-
限流
INT 类型,INCR 方法
以访问者的 IP 和其他信息作为 key,访问一次增加一次计数,超过次数则返回 false。
-
位统计
String 类型的 BITCOUNT(1.6.6 的 bitmap 数据结构介绍)。 字符是以 8 位二进制存储的。
set k1 a setbit k1 6 1 setbit k1 7 0 get k1a 对应的 ASCII 码是 97,转换为二进制数据是 01100001
b 对应的 ASCII 码是 98,转换为二进制数据是 01100010
因为 bit 非常节省空间(1 MB=8388608 bit)大约830万,可以用来做大数据量的统计。
例如:在线用户统计,留存用户统计
setbit onlineusers 0 1 setbit onlineusers 1 1 setbit onlineusers 2 0支持按位与、按位或等等操作。
BITOP AND destkey key [key ...] ,对一个或多个 key 求逻辑并,并将结果保存到 destkey 。 BITOP OR destkey key [key ...] ,对一个或多个 key 求逻辑或,并将结果保存到 destkey 。 BITOP XOR destkey key [key ...] ,对一个或多个 key 求逻辑异或,并将结果保存到 destkey 。 BITOP NOT destkey key ,对给定 key 求逻辑非,并将结果保存到 destkey 。计算出 7 天都在线的用户
BITOP "AND" "7_days_both_online_users" "day_1_online_users" "day_2_online_users" ... "day_7_online_users"如果一个对象的 value 有多个值的时候,怎么存储? 例如用一个 key 存储一张表的数据。

序列化?例如 JSON/Protobuf/XML,会增加序列化和反序列化的开销,并且不能 单独获取、修改一个值。可以通过 key 分层的方式来实现,例如:
mset student:1:sno GP16666 student:1:sname 沐风 student:1:company 腾讯获取值的时候一次获取多个值:
mget student:1:sno student:1:sname student:1:company缺点:key 太长,占用的空间太多。有没有更好的方式?
-
-
-
Hash 哈希(包含键值对的无序散列表。value 只能是字符串,不能嵌套其他类型 )
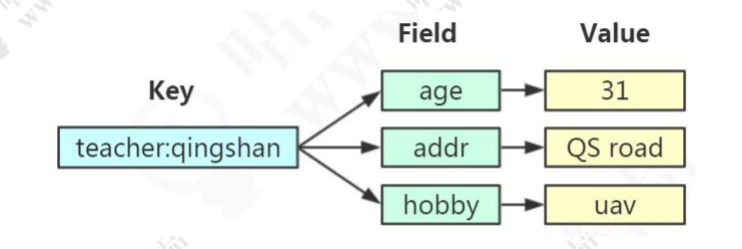
同样是存储字符串,Hash 与 String 的主要区别?
- 把所有相关的值聚集到一个 key 中,节省内存空间
- 只使用一个 key,减少 key 冲突
- 当需要批量获取值的时候,只需要使用一个命令,减少内存/IO/CPU 的消耗
Hash 不适合的场景:
- Field 不能单独设置过期时间
- 没有 bit 操作
- 需要考虑数据量分布的问题(value 值非常大的时候,无法分布到多个节点)
hset h1 f 6
hset h1 e 5
hmset h1 a 1 b 2 c 3 d 4
hget h1 a
hmget h1 a b c d
hkeys h1
hvals h1
hgetall h1
key 操作
hget exists h1
hdel h1
hlen h1
-
存储(实现)原理
Redis 的 Hash 本身也是一个 KV 的结构,类似于 Java 中的 HashMap。 外层的哈希(Redis KV 的实现)只用到了 hashtable。当存储 hash 数据类型时, 我们把它叫做内层的哈希。内层的哈希底层可以使用两种数据结构实现: ziplist:OBJ_ENCODING_ZIPLIST(压缩列表) hashtable:OBJ_ENCODING_HT(哈希表)
ziplist 压缩列表
ziplist 是一个经过特殊编码的双向链表,它不存储指向上一个链表节点和指向下一 个链表节点的指针,而是存储上一个节点长度和当前节点长度,通过牺牲部分读写性能, 来换取高效的内存空间利用率,是一种时间换空间的思想。只用在字段个数少,字段值 小的场景里面
问题:什么时候使用 ziplist 存储?
- 所有的键值对的健和值的字符串长度都小于等于 64byte(一个英文字母 一个字节);
- 哈希对象保存的键值对数量小于 512 个。
-
应用场景
-
String
String 可以做的事情,Hash 都可以做。
-
存储对象类型的数据
比如对象或者一张表的数据,比 String 节省了更多 key 的空间,也更加便于集中管 理。
-
购物车
key:用户 id;field:商品 id;value:商品数量。
hset userId:0001 shopId:99999 5
-
-
List 列表
-
存储类型
存储有序的字符串(从左到右),元素可以重复。可以充当队列和栈的角色。

-
操作命令
元素增减:
lpush queue a //从左开始添加元素 lpush queue b c rpush queue d e //从右边开始添加元素 lpop queue //从左边弹出元素 rpop queue // 从右边弹出元素 blpop queue //阻塞式左边的弹出元素 发布订阅模式 如果当前队列中没有了元素,就会阻塞 brpop queue //阻塞式的右边弹出元素取值
lindex queue 0 lrange queue 0 -1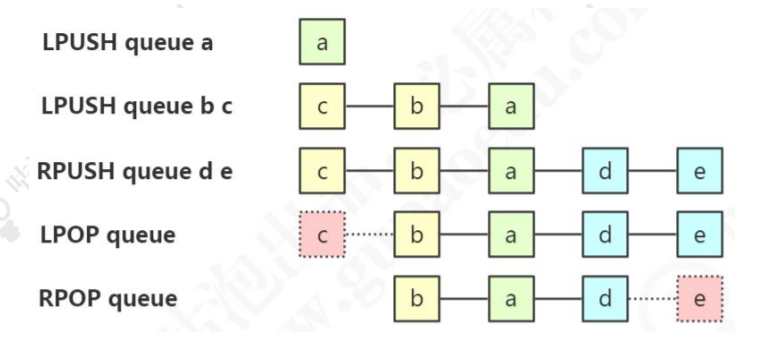
-
存储(实现)原理
在早期的版本中,数据量较小时用 ziplist 存储,达到临界值时转换为 linkedlist 进 行存储,分别对应 OBJ_ENCODING_ZIPLIST 和 OBJ_ENCODING_LINKEDLIST 。 3.2 版本之后,统一用 quicklist 来存储。quicklist 存储了一个双向链表,每个节点 都是一个 ziplist。
quicklist :
quicklist(快速列表)是 ziplist 和 linkedlist 的结合体。
quicklist中的head 和 tail 指向双向列表的表头和表尾
typedef struct quicklist { quicklistNode *head; /* 指向双向列表的表头 */ quicklistNode *tail; /* 指向双向列表的表尾 */ unsigned long count; /* 所有的 ziplist 中一共存了多少个元素 */ unsigned long len; /* 双向链表的长度,node 的数量 */ int fill : 16; /* fill factor for individual nodes */ unsigned int compress : 16; /* 压缩深度,0:不压缩; */ } quicklist; -
应用场景
-
用户消息时间线 timeline
因为 List 是有序的,可以用来做用户时间线
-
消息队列
List 提供了两个阻塞的弹出操作:BLPOP/BRPOP,可以设置超时时间。
BLPOP:BLPOP key1 timeout 移出并获取列表的第一个元素, 如果列表没有元素 会阻塞列表直到等待超时或发现可弹出元素为止。
BRPOP:BRPOP key1 timeout 移出并获取列表的最后一个元素, 如果列表没有元 素会阻塞列表直到等待超时或发现可弹出元素为止。
队列:先进先出:rpush blpop,左头右尾,右边进入队列,左边出队列。 右边进左边出
栈:先进后出:rpush brpop 右边近右边出
tip: 左边是链表的头部
-
-
-
Set集合
-
存储类型
String 类型的无序集合,最大存储数量 2^32-1(40 亿左右)。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QzGFJauR-1603368961704)(https://i.loli.net/2020/05/25/dlP8pwyEbjseLfS.png)]
-
操作命令
添加一个或者多个元素
sadd myset a b c d e f g获取所有元素
smembers myset统计元素个数
scard myset随机获取一个元素
srandmember key随机弹出一个元素
spop myset移除一个或者多个元素
srem myset d e f查看元素是否存在
sismember myset a -
存储(实现)原理
Redis 用 intset 或 hashtable 存储 set。如果元素都是整数类型,就用 inset 存储。 如果不是整数类型,就用 hashtable(数组+链表的存来储结构)。 问题:KV 怎么存储 set 的元素?key 就是元素的值,value 为 null。 如果元素个数超过 512 个,也会用 hashtable 存储。
-
应用场景
-
抽奖
随机获取元素
spop myset -
点赞、签到、打卡
这条微博的 ID 是 t1001,用户 ID 是 u3001。
用 like:t1001 来维护 t1001 这条微博的所有点赞用户。
点赞了这条微博:sadd like:t1001 u3001
取消点赞:srem like:t1001 u3001
是否点赞:sismember like:t1001 u3001
点赞的所有用户:smembers like:t1001
点赞数:scard like:t1001 比关系型数据库简单许多。
-
商品标签
用 tags:i5001 来维护商品所有的标签。
sadd tags:i5001 画面清晰细腻
sadd tags:i5001 真彩清晰显示屏
sadd tags:i5001 流畅至极
-
商品筛选
获取差集
sdiff set1 set2获取交集(intersection )
sinter set1 set2获取并集
sunion set1 set2iPhone11 上市了。
sadd brand:apple iPhone11
sadd brand:ios iPhone11
sad screensize:6.0-6.24 iPhone11
sad screentype:lcd iPhone11
筛选商品,苹果的,iOS 的,屏幕在 6.0-6.24 之间的,屏幕材质是 LCD 屏幕
sinter brand:apple brand:ios screensize:6.0-6.24 screentype:lcd -
用户关注、推荐模型
并集:A中有B中也有,去除重复的,
交集:A和B共同的部分才是交集
全集U={1,2,3,4,5} A={1,3,5} B={1,2,5} 。那么因为A和B中都有1,5,所以交集A∩B={1,5} 。再来看看,他们两个中含有1,2,3,5这些个元素,不管多少,反正不是你有,就是我有。那么说并集A∪B={1,2,3,5}
-
相互关注? (取并集)
sunion set1 set2 -
我(A)关注的人,他(B)也关注了?(取交集)
sinter set1 set2-
可能认识的人? (取差集 SET1中有的 而set2中没有的)
sdiff set1 set2 -
共同关注/共同好友的人
sinterstore set5 set1 set2 127.0.0.1:6379> smembers set1 //我关注了one 1) "two" 2) "one" 127.0.0.1:6379> smembers set2 //他也关注了one 1) "ghy" 2) "one" 127.0.0.1:6379> sinterstore set5 set1 set2 //我们两共同的共同关注的人 (integer) 1 127.0.0.1:6379> smembers set5 1) "one" //one
-
-
Redis实现关注关系
最近使用关系型数据库实现了用户之间的关注,于是思考换一种思路,使用Redis实现用户之间的关注关系。
综合考虑了一下Redis的几种数据结构后,觉得可以用集合实现一下。假设“我”的ID是1,“别人”的ID是2。
一、添加关注
添加关注分为两步:1、将对方id添加到自己的关注列表中;2、将自己的id添加到对方的粉丝列表中:
SADD 1:follow 2 SADD 2:fans 1二、取消关注
取消关注同样分为两步:1、将对方id从自己的关注列表中移除;2、将自己的id从对方的粉丝列表中移除:
SREM 1:follow 2 SREM 2:fans 1三、关注列表
查看我的关注列表:
SMEMBERS 1:follow查看别人的把id换掉就可以
四、粉丝列表
查看我的粉丝列表:
SMEMBERS 2:fans查看别人的把id换掉就可以
五、人物关系
5.1 我单向关注他
我单向关注他,要
同时满足两个条件:1、我的关注列表中有他(或他的粉丝列表中有我);2、我的粉丝列表中没有他(或他的关注列表中没有我)。SISMEMBER 1:follow 2 #true SISMEMBER 1:fans 2 #false5.2 他单向关注我
他单向关注我,要
同时满足两个条件:1、我的关注列表中没有他(或他的粉丝列表中没有我);2、我的粉丝列表中有他(或他的关注列表中有我)。SISMEMBER 1:follow 2 #false SISMEMBER 1:fans 2 #true5.3 我和某人是否互粉
我和某人是否互粉,要
同时满足两个条件:1、我的关注列表中有他(或他的粉丝列表中有我);2、我的粉丝列表中有他(或他的关注列表中有我)。同时成立才为互粉。SISMEMBER 1:follow 2 #true SISMEMBER 1:fans 2 #true互粉的关系是互相的,也可以反过来查。
六、我的互粉
查询和我互粉的人,实际是对我的关注和我的粉丝求交集
SINTER 1:follow 1:fans七、共同关注
查询1和2的共同关注,实际是1的关注和2的关注求交集
SINTER 1:follow 2:follow八、数量相关
8.1 我的关注数
SCARD 1:follow8.2 我的粉丝数
SCARD 1:fans九、问题
目前存在的问题是,我的关注列表 & 我的粉丝列表,无法做到按关注时间排序,终端下显示是结果按ID正序排列的。
考虑的解决方案是添加关注时同时存一份有序集合,关注时的时间戳是score。ZADD 1:follow 1457871625 2 ZADD 2:fans 1457871625 1那么我的关注列表是:
ZREVRANGE 1:follow 0 -1同时,ZREVRANGE查询时的索引可以作为分页游标,基本解决目前的问题。
粉丝列表同理。
-
-
-
ZSet有序集合
-
存储类型
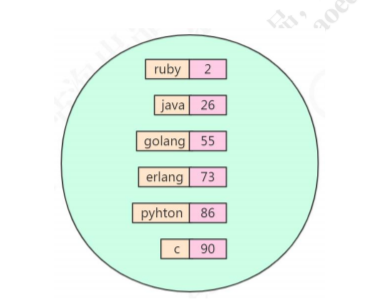
sorted set,有序的 set,每个元素有个 score。
score 相同时,按照 key 的 ASCII 码排序。
数据结构对比:
数据结构 是否允许重复元素 是否有序 有序实现方式 列表list 是 是 索引下标 集合set 否 否 无 有序集合zset 否 是 分值score -
操作命令
添加元素
zadd myzset 10 java 20 php 30 ruby 40 cpp 50 python获取全部元素
zrange myzset 0 -1 withscores zrevrange myzset 0 -1 withscores根据分值区间获取元素
zrangebyscore myzset 20 30移除元素 也可以根据 score rank 删除
zrem myzset php cpp统计元素个数
zcard myzset分值递增
zincrby myzset 5 python根据分值统计个数
zcount myzset 20 60获取元素 rank
zrank myzset java获取元素 score
zsocre myzset java -
存储(实现)原理
同时满足以下条件时使用 ziplist 编码:
-
元素数量小于 128 个
-
所有 member 的长度都小于 64 字节
在 ziplist 的内部,按照 score 排序递增来存储。插入的时候要移动之后的数据。
超过阈值之后,使用 skiplist+dict 存储。
什么是 skiplist?

我们先来看一下有序链表: 在这样一个链表中,如果我们要查找某个数据,那么需要从头开始逐个进行比较, 直到找到包含数据的那个节点,或者找到第一个比给定数据大的节点为止(没找到)。 也就是说,时间复杂度为 O(n)。同样,当我们要插入新数据的时候,也要经历同样的查 找过程,从而确定插入位置。
而二分查找法只适用于有序数组,不适用于链表。
假如我们每相邻两个节点增加一个指针(或者理解为有三个元素进入了第二层), 让指针指向下下个节点。

这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半 (上图中是 7, 19, 26)。在插入一个数据的时候,决定要放到那一层,取决于一个算法 (在 redis 中 t_zset.c 有一个 zslRandomLevel 这个方法)。
现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数 据大的节点时,再回到原来的链表中的下一层进行查找
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行 比较了。需要比较的节点数大概只有原来的一半。这就是跳跃表。
为什么不用 AVL 树或者红黑树?因为 skiplist 更加简洁
-
-
应用场景
-
排行榜
id 为 6001 的新闻点击数加 1:zincrby hotNews:20190926 1 n6001
获取今天点击最多的 15 条:zrevrange hotNews:20190926 0 15 withscores
-
-
-
BitMaps
Bitmaps 是在字符串类型上面定义的位操作。一个字节由 8 个二进制位组成。
应用场景: 用户访问统计 在线用户统计
-
Hyperloglogs
Hyperloglogs:提供了一种不太准确的基数统计方法,比如统计网站的 UV,存在 一定的误差。
-
Streams
支持多播1->N的可持久化的消息队列,用于实现发布订阅功能,借 鉴了 kafka 的设计。
**这样所有新增加的指针连成了一个新的链表**,但它包含的节点个数只有原来的一半 (上图中是 7, 19, 26)。在插入一个数据的时候,决定要放到那一层,取决于一个算法 (在 redis 中 t_zset.c 有一个 zslRandomLevel 这个方法)。
现在当我们想查找数据的时候,可以先沿着这个新链表进行查找。当碰到比待查数 据大的节点时,再回到原来的链表中的下一层进行查找
在这个查找过程中,由于新增加的指针,我们不再需要与链表中每个节点逐个进行 比较了。需要比较的节点数大概只有原来的一半。这就是跳跃表。
为什么不用 AVL 树或者红黑树?因为 skiplist 更加简洁
-
应用场景
-
排行榜
id 为 6001 的新闻点击数加 1:zincrby hotNews:20190926 1 n6001
获取今天点击最多的 15 条:zrevrange hotNews:20190926 0 15 withscores
-
-
BitMaps
Bitmaps 是在字符串类型上面定义的位操作。一个字节由 8 个二进制位组成。
应用场景: 用户访问统计 在线用户统计
-
Hyperloglogs
Hyperloglogs:提供了一种不太准确的基数统计方法,比如统计网站的 UV,存在 一定的误差。
-
Streams
支持多播1->N的可持久化的消息队列,用于实现发布订阅功能,借 鉴了 kafka 的设计。















 561
561

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









