







 这篇论文探讨了如何使用CLIP模型改进图像质量评估,通过修改提示以减少歧义。实验结果显示,在未微调时,CLIP-IQA性能与BRISQUE相当;但在微调后,效果不佳。论文方法创新性有限,实验呈现侧重于可视化,缺乏具体量化数据。
这篇论文探讨了如何使用CLIP模型改进图像质量评估,通过修改提示以减少歧义。实验结果显示,在未微调时,CLIP-IQA性能与BRISQUE相当;但在微调后,效果不佳。论文方法创新性有限,实验呈现侧重于可视化,缺乏具体量化数据。
论文《Exploring CLIP for Assessing the Look and Feel of Images》阅读
论文概述
今天带来的是论文《Exploring CLIP for Assessing the Look and Feel of Images》,论文主要通过 CLIP 模型来完成图像的质量(how it looks,即quality perception)和情感(how it feels, 即abstract perception)评分。
论文由南洋理工S-Lab完成,论文内容相对简单。整体来讲就是在 vision-language 跨模态大模型训练的时候将原始的prompt改为形容词及其反义词的二元组prompt,以减小表达中的歧义。
论文发表在AAAI 2023上,模型取名为CLIP-IQA。
Preliminary
下面介绍一下一些基本术语:
IQA: Image Quality Assessment 图像质量评价
CLIP:a Vision-Language Pre-Training SOTA model,主要完成跨模态对齐(Cross-modal Alignment, CMA)
方法论
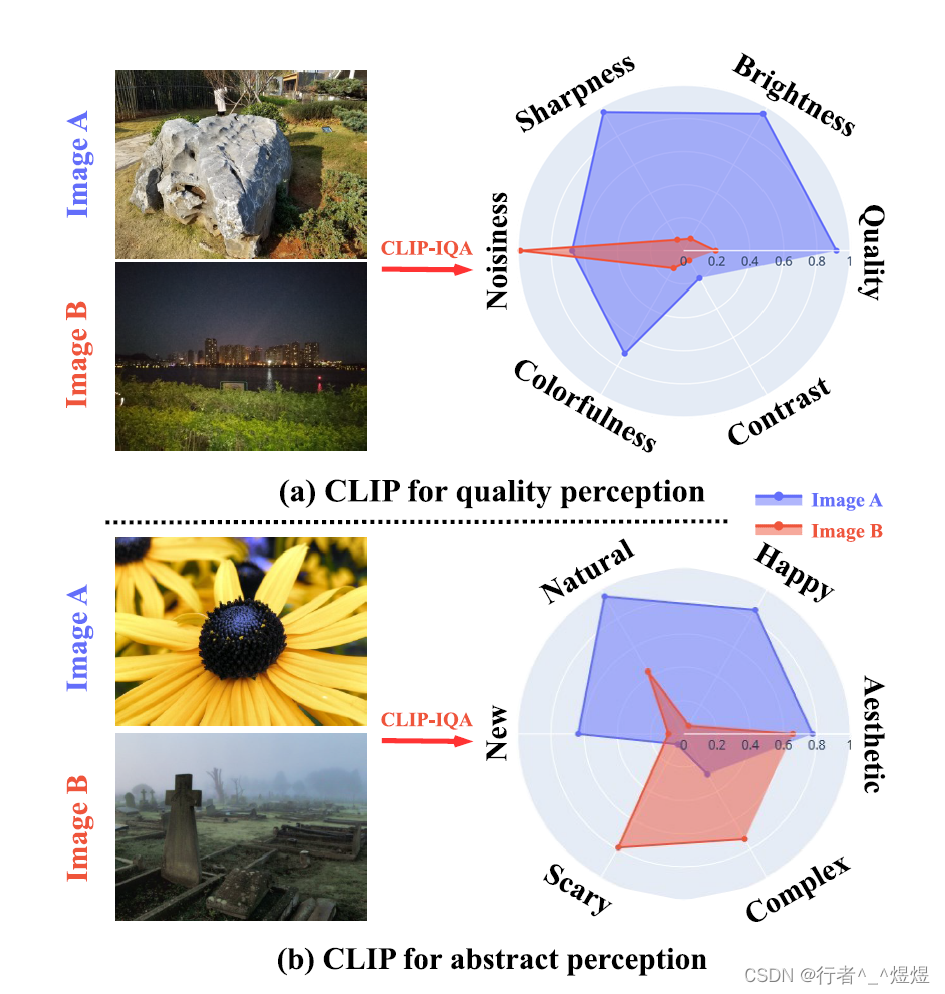
本文主要聚焦于IQA中关于look和feel的评价,其实也就是客观质量评价和主观质量评价,分别(1)关注图片质量(look)如何(粗粒度讲分为“好”/“不好”;细粒度讲包括“噪声”、“明亮度”、“对比度”、“色彩”等(非CV方向,可能翻译不太准));(2)关注图像内容蕴含的抽象感受(例如“恐怖”、“自然”、“快乐”、“复杂”等)。
随着大模型的火热,现阶段主要基于CLIP完成跨模态语义对齐,分别通过NLP token 和 CV images 的 描述,将图像和文本语义在空间中的描述进行统一,最终完成语义的挖掘。
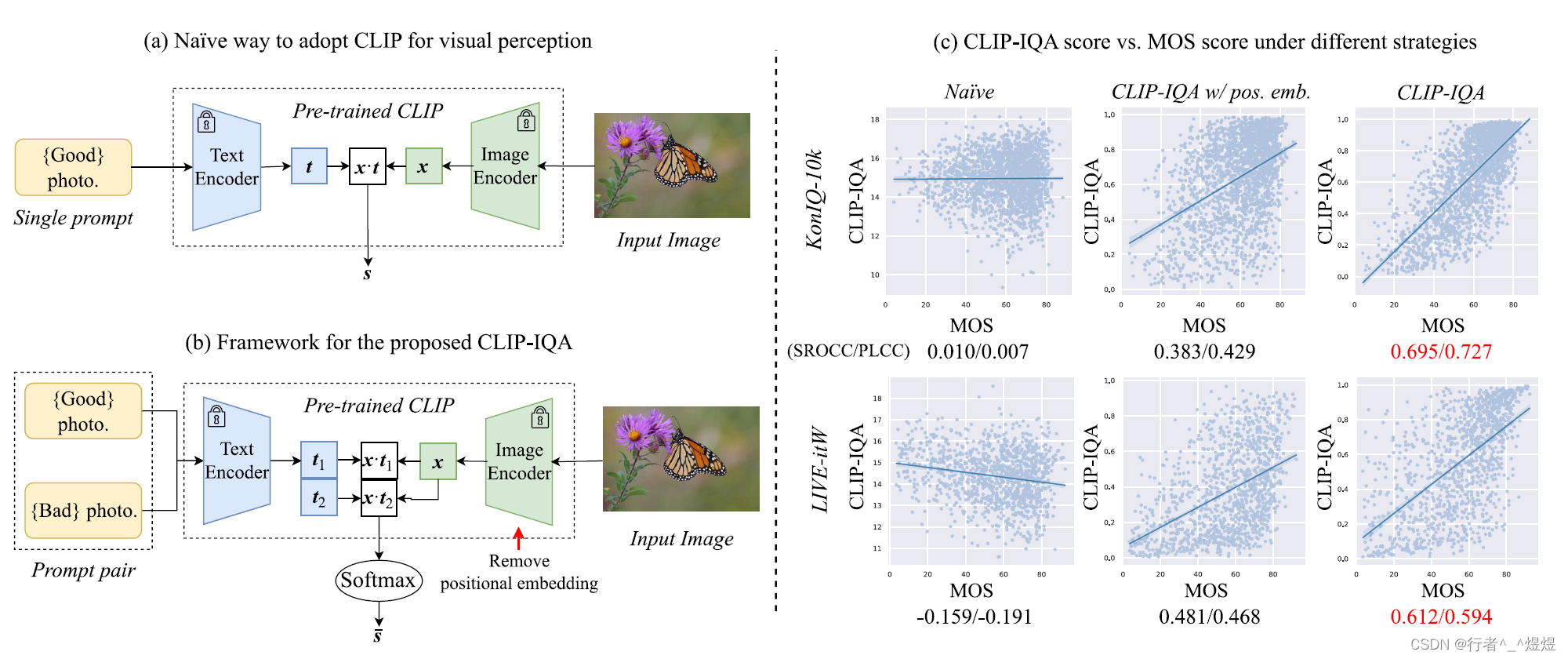
作者认为当前主要问题是文本和图像可能存在偏差,具体而言就是文本描述存在歧义,使得无法真正做到文本和图像的一一对应。
作者怎么做的呢?其实就是把原来的文本换成二元组,加上文本描述的反义词,通过反义词从而消除文本的歧义,分别和图像生成的embedding做相似性比较,然后两个相似性分数通过softmax,得到最终的分类预测分数。即,
s = x ⊙ t ∥ x ∥ ⋅ ∥ t ∥ . (1) s=\frac{\boldsymbol{x} \odot \boldsymbol{t}}{\|\boldsymbol{x}\| \cdot\|\boldsymbol{t}\|}. \tag{1} s=∥x∥⋅∥
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









