







文章目录
参考牛客网高级项目教程
狂神说Redis教程笔记
功能需求

- 1.项目中需要用到多线程的定时任务,如帖子评分计算与排名
- 2.为提高性能,需要用到线程池,先了解传统的JDK、Spring线程池的使用
- 3.传统的线程池的定时任务
Scheduler不适用于分布式部署,而采用Spring整合Quartz方案
1. 为何分布式部署Scheduler不合适,而采用Quartz
- 因为,如果采用JDK和Spring线程池的
Scheduler,定时任务参数存于内存- 每台服务器都同时自动调用定时任务,会同时运行一个程序,没有必要,也有可能会产生冲突
- 但是,采用Quartz,在集群环境下,定时任务参数存于数据库DB中
- 这样,每台服务器会定时任务调度器都会访问DB,通过加锁方式去抢DB
- 如果服务器1先抢到DB,会查看表中数据的运行状态,如果为等待运行状态,将状态改位运行状态,然后去处理定时任务
- 在此时间里,服务器2再拿到DB,会读取到正在运行状态,说明已经有服务器在处理,因此,无需再处理

一、JDK线程池认识与测试
1. 使用JDK普通线程池创建线程
ExecutorService-JDK线程池接口
线程的创建和释放,需要占用不小的内存和资源。
如果每次需要使用线程时,都new 一个Thread的话,难免会造成资源的浪费,
而且无限制创建,之间相互竞争,会导致过多占用系统资源导致系统瘫痪。不利于扩展,比如如定时执行、定期执行、线程中断
- ExecutorService是Java提供的线程池
- 可以通过ExecutorService获得线程。它可以有效控制最大并发线程数,提高系统资源的使用率,
- 同时避免过多资源竞争,避免堵塞,同时提供定时执行、定期执行、单线程、并发数控制等功能,也不用使用TimerTask了。
Executors.newFixedThreadPool(5)-线程池创建方式-固定线程数
- 创建固定数量的可复用的线程数,来执行任务。
- 当线程数达到最大核心线程数,则加入队列等待有空闲线程时再执行。

ThreadPoolExecutor-创建线程池的最终方式
-
这是所有创建线程都要调用的核心方法
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue) { this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, Executors.defaultThreadFactory(), defaultHandler); }
corePoolSize : 核心线程数,一旦创建将不会再释放。如果创建的线程数还没有达到指定的核心线程数量,将会继续创建新的核心线程,直到达到最大核心线程数后,核心线程数将不在增加;如果没有空闲的核心线程,同时又未达到最大线程数,则将继续创建非核心线程;如果核心线程数等于最大线程数,则当核心线程都处于激活状态时,任务将被挂起,等待空闲线程来执行。
maximumPoolSize : 最大线程数,允许创建的最大线程数量。如果最大线程数等于核心线程数,则无法创建非核心线程;如果非核心线程处于空闲时,超过设置的空闲时间,则将被回收,释放占用的资源。
keepAliveTime : 当线程空闲时,所允许保存的最大时间,超过这个时间,线程将被释放销毁,但只针对于非核心线程。
unit : 时间单位,TimeUnit.SECONDS等。
workQueue : 任务队列,存储暂时无法执行的任务,等待空闲线程来执行任务。
threadFactory : 线程工程,用于创建线程。
handler : 当线程边界和队列容量已经达到最大时,用于处理阻塞时的程序
executorService.submit(task)-根据任务创建线程
- 当将一个任务添加到线程池中的时候,线程池会为每个任务创建一个线程,该线程会在之后的某个时刻自动执行。
- 有返回结果
private static final Logger logger = LoggerFactory.getLogger(ThreadPoolTests.class);
// JDK普通线程池-定义5个线程
private ExecutorService executorService = Executors.newFixedThreadPool(5);
// 为了能在测试中显示出日志结果,让当前主测试类线程睡眠10秒
private void sleep(long m) {
try {
Thread.sleep(m);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 测试JDK普通线程池
*/
@Test
public void testExecutorService() {
// 定义每个线程执行逻辑
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ExecutorService!");
}
};
// 使用线程池创建10次线程执行任务
for (int i = 0; i < 10; i++) {
executorService.submit(task);
}
sleep(10000);
}
测试结果:

2. JDK定时任务线程池
ScheduledExecutorService
- 继承于ExecutorService接口,提高定时任务的线程池
public interface ScheduledExecutorService extends ExecutorService {
}
- 因此,创建线程池的方式最终底层也调用了父类的方法
newScheduledThreadPool-创建定时任务线程池的静态方法
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
/**
* Creates a new {@code ScheduledThreadPoolExecutor} with the
* given core pool size.
*
* @param corePoolSize the number of threads to keep in the pool, even
* if they are idle, unless {@code allowCoreThreadTimeOut} is set
* @throws IllegalArgumentException if {@code corePoolSize < 0}
*/
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue());
}
scheduleAtFixedRate-创建执行定时任务的线程
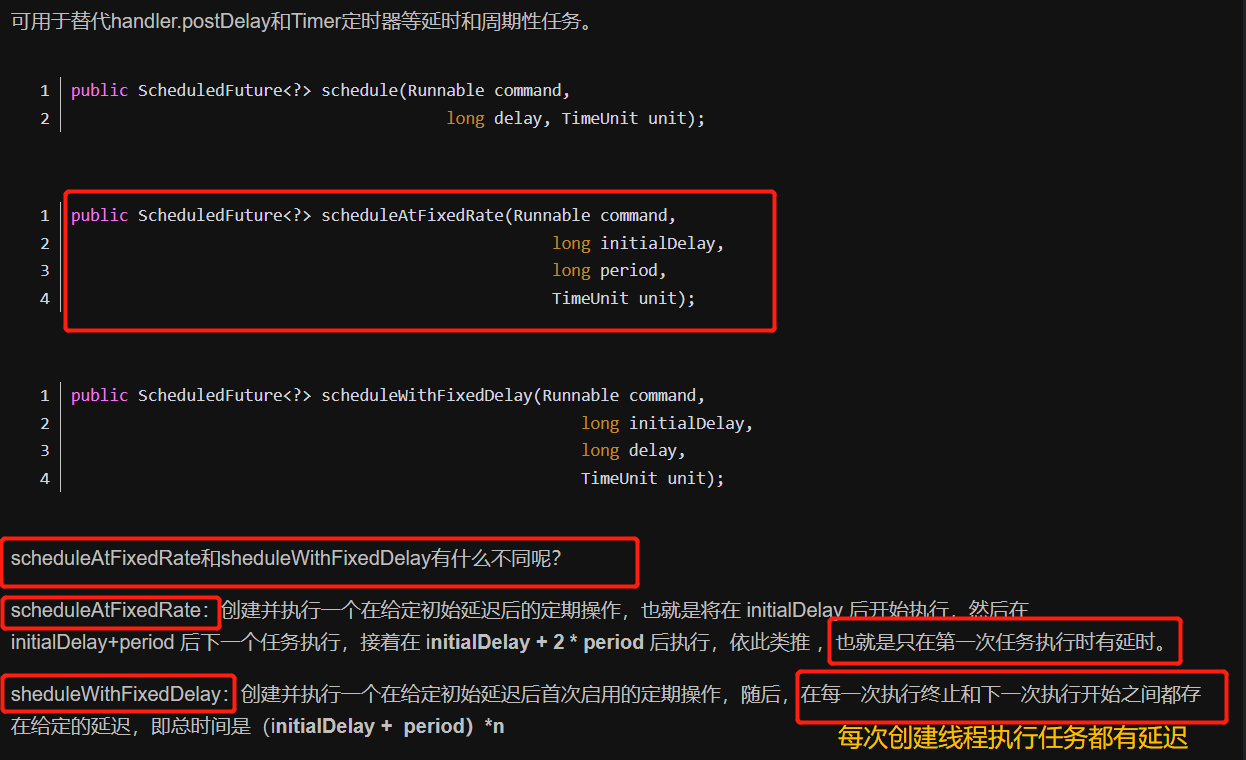
// JDK可执行定时任务的线程池
private ScheduledExecutorService scheduledExecutorService = Executors.newScheduledThreadPool(5);
/**
* 测试JDK定时任务线程池
*/
@Test
public void testScheduledExecutorService() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ScheduledExecutorService");
}
};
scheduledExecutorService.scheduleAtFixedRate(task, 10000, 1000, TimeUnit.MILLISECONDS);
sleep(20000);
}
测试结果:

二、Spring线程池的认识与测试
1. Spring普通线程池
ThreadPoolTaskExecutor-Spring线程池
-
使用Spring线程池,自动初始化线程池,需要进行配置参数,否则线程池中创建的线程过多,性能浪费

-
配置参数如下:
-
因此,比JDK线程池使用更灵活
第一个是一开始5个,如果不够用就自动扩充到15个,如果15个还不够用,那么就把任务缓冲到队列里队列里最大可以容下100个任务
-
# TaskExecutionProperties
spring.task.execution.pool.core-size=5 # 核心线程个数
spring.task.execution.pool.max-size=15 # 线程最多可以扩容的个数
spring.task.execution.pool.queue-capacity=100 # 队列容量(任务多,先放队列里,等待线程池空闲)
// Spring普通线程池
@Autowired
private ThreadPoolTaskExecutor taskExecutor;
@Test
public void testThreadPoolTaskExecutor() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ThreadPoolTaskExecutor");
}
};
for (int i = 0; i < 10; i++) {
taskExecutor.submit(task);
}
sleep(10000);
}
测试结果:

2. Spring定时任务线程池
@EnableScheduling -启动定时任务
- 使用Spring定时任务线程池,需要新建配置类,加上启动定时任务的注解才可以使用,否则Bean无法使用
@Configuration
@EnableScheduling // 启动定时任务
@EnableAsync // 支持异步执行任务
public class ThreadPoolConfig {
}
ThreadPoolTaskScheduler-Spring定时任务线程池
-
同样,自动初始化线程池,在配置文件中指定核心线程数量

-
配置参数:
- 只需配置核心线程数量即可
# TaskSchedulingProperties spring.task.scheduling.pool.size=5
为何定时任务线程池不需要指定最大线程数量和线程队列
- 因为,与普通线程池不同,普通线程池,根据请求的任务创建线程,请求任务不确定,因此需要指定最大线程数量和线程队列
- 定时任务线程池更加定时任务创建线程,多少个定时任务是确定的,在服务器启动时候就知道,故,线程数量也是确定的
// Spring可执行定时任务的线程池
@Autowired
private ThreadPoolTaskScheduler taskScheduler;
@Test
public void testThreadPoolTaskScheduler() {
Runnable task = new Runnable() {
@Override
public void run() {
logger.debug("Hello ThreadPoolTaskScheduler");
}
};
Date startTime = new Date(System.currentTimeMillis() + 10000); // 当前时间往后延迟10s
taskScheduler.scheduleAtFixedRate(task, startTime, 1000);
sleep(30000);
}
测试结果

3. Spring普通线程池简化处理
@Async- 异步创建线程处理任务
// 让该方法在多线程环境下,被异步的调用.
@Async
public void execute1() {
logger.debug("execute1");
}
- 异步创建线程,处理定义的任务
@Autowired
AlphaService alphaService;
@Test
public void testThreadPoolTaskExecutorSimple() {
for (int i = 0; i < 10; i++) {
alphaService.execute1();
}
sleep(10000);
}
测试结果

4. Spring定时线程池简化处理
@Scheduled(initialDelay = 10000, fixedRate = 1000)-异步创建定时任务线程池
@Scheduled(initialDelay = 10000, fixedRate = 1000)
public void execute2() {
logger.debug("execute2");
}
/**
* Spring定时任务线程池简化
*/
@Test
public void testThreadPoolTaskSchedulerSimple() {
sleep(30000);
}
测试结果

三、SpringQuartz认识与测试
1. Quartz认识
导入包
<!-- 整合Quartz-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
</dependency>
Scheduler-核心任务调度器接口
- 代表一个Quartz的独立运行容器,
- Trigger和JobDetail可以注册到Scheduler中,两者在Scheduler中拥有各自的组及名称,
- 组及名称是Scheduler查找定位容器中某一对象的依据,Trigger的组及名称必须唯一,
- JobDetail的组和名称也必须唯一(但可以和Trigger的组和名称相同,因为它们是不同类型的)。
- Scheduler定义了多个接口方法,允许外部通过组及名称访问和控制容器中Trigger和JobDetail。
Job-作业任务的接口
- 是一个接口,只有一个方法
void execute(JobExecutionContext context), - 开发者==自定义实现该接口定义运行任务==,
JobExecutionContext类提供了调度上下文的各种信息。
JobDetail-配置Job的接口
- Quartz在每次执行Job时,都重新创建一个Job实例,所以它不直接接受一个Job的实例,相反它接收一个Job实现类,以便运行时通过newInstance()的反射机制实例化Job。
- 因此需要通过一个类
JobDetail来描述Job的实现类及其它相关的静态信息,- 如Job名字、
- 属于哪个组,
- 对Job任务的描述、
- 关联监听器等相关参数的配置。
Trigger-触发器配置接口
- 配置Job任务什么时候运行,以什么频率运行
- 描述触发Job执行的时间触发规则。主要有SimpleTrigger和CronTrigger这两个子类。
- 当仅需触发一次或者以固定时间间隔周期执行,SimpleTrigger是最适合的选择;
- 而CronTrigger则可以通过Cron表达式定义出各种复杂时间规则的调度方案:如每早晨9:00执行,周一、周三、周五下午5:00执行等。
Scheduler可以将Trigger绑定到某一JobDetail中,这样当Trigger触发时,对应的Job就被执行。
一个Job可以对应多个Trigger,但一个Trigger只能对应一个Job。
可以通过SchedulerFactory创建一个Scheduler实例。Scheduler拥有一个SchedulerContext,它类似于ServletContext,保存着Scheduler上下文信息,Job和Trigger都可以访问SchedulerContext内的信息。
SchedulerContext内部通过一个Map,以键值对的方式维护这些上下文数据,SchedulerContext为保存和获取数据提供了多个put()和getXxx()的方法。可以通过Scheduler# getContext()获取对应的SchedulerContext实例。
2. Quartz执行过程
- 1.Quartz通过Job定义定时任务
- 2.定义JobDetail和Trigger配置文件,配置Job任务
- 3.首次启动服务器时,Quartz会读取配置文件,并立即自动将数据储存到DB中,然后配置类就不再使用
- 今后执行定时任务,都会直接访问数据库
- 配置类只在第一次启动时使用一次
3. Quartz数据库表的设计
jobDetail配置信息表
CREATE TABLE `qrtz_job_details` (
`SCHED_NAME` varchar(120) NOT NULL, # 定时任务名字
`JOB_NAME` varchar(190) NOT NULL, # job名字
`JOB_GROUP` varchar(190) NOT NULL, # job组名
`DESCRIPTION` varchar(250) DEFAULT NULL, # job的描述
`JOB_CLASS_NAME` varchar(250) NOT NULL, # job对应哪个类
`IS_DURABLE` varchar(1) NOT NULL,
`IS_NONCONCURRENT` varchar(1) NOT NULL,
`IS_UPDATE_DATA` varchar(1) NOT NULL,
`REQUESTS_RECOVERY` varchar(1) NOT NULL,
`JOB_DATA` blob,
PRIMARY KEY (`SCHED_NAME`,`JOB_NAME`,`JOB_GROUP`),
KEY `IDX_QRTZ_J_REQ_RECOVERY` (`SCHED_NAME`,`REQUESTS_RECOVERY`),
KEY `IDX_QRTZ_J_GRP` (`SCHED_NAME`,`JOB_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
Trigger触发器相关配置数据表
触发器简单配置
CREATE TABLE `qrtz_simple_triggers` (
`SCHED_NAME` varchar(120) NOT NULL, # 任务名字
`TRIGGER_NAME` varchar(190) NOT NULL, # 触发器名字
`TRIGGER_GROUP` varchar(190) NOT NULL, # 触发器组名
`REPEAT_COUNT` bigint(7) NOT NULL, # 反复执行的次数
`REPEAT_INTERVAL` bigint(12) NOT NULL,
`TIMES_TRIGGERED` bigint(10) NOT NULL,
PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),
CONSTRAINT `qrtz_simple_triggers_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`) REFERENCES `qrtz_triggers` (`SCHED_NAME`, `TRIGGER_NAME`, `TRIGGER_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
触发器完整配置
CREATE TABLE `qrtz_triggers` (
`SCHED_NAME` varchar(120) NOT NULL,
`TRIGGER_NAME` varchar(190) NOT NULL,
`TRIGGER_GROUP` varchar(190) NOT NULL,
`JOB_NAME` varchar(190) NOT NULL, # 对应job名称
`JOB_GROUP` varchar(190) NOT NULL, # 对应job组名
`DESCRIPTION` varchar(250) DEFAULT NULL,
`NEXT_FIRE_TIME` bigint(13) DEFAULT NULL, # 下一次什么时候开始执行
`PREV_FIRE_TIME` bigint(13) DEFAULT NULL, # 上一次什么时候执行完
`PRIORITY` int(11) DEFAULT NULL,
`TRIGGER_STATE` varchar(16) NOT NULL,
`TRIGGER_TYPE` varchar(8) NOT NULL,
`START_TIME` bigint(13) NOT NULL,
`END_TIME` bigint(13) DEFAULT NULL,
`CALENDAR_NAME` varchar(190) DEFAULT NULL,
`MISFIRE_INSTR` smallint(2) DEFAULT NULL,
`JOB_DATA` blob,
PRIMARY KEY (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`),
KEY `IDX_QRTZ_T_J` (`SCHED_NAME`,`JOB_NAME`,`JOB_GROUP`),
KEY `IDX_QRTZ_T_JG` (`SCHED_NAME`,`JOB_GROUP`),
KEY `IDX_QRTZ_T_C` (`SCHED_NAME`,`CALENDAR_NAME`),
KEY `IDX_QRTZ_T_G` (`SCHED_NAME`,`TRIGGER_GROUP`),
KEY `IDX_QRTZ_T_STATE` (`SCHED_NAME`,`TRIGGER_STATE`),
KEY `IDX_QRTZ_T_N_STATE` (`SCHED_NAME`,`TRIGGER_NAME`,`TRIGGER_GROUP`,`TRIGGER_STATE`),
KEY `IDX_QRTZ_T_N_G_STATE` (`SCHED_NAME`,`TRIGGER_GROUP`,`TRIGGER_STATE`),
KEY `IDX_QRTZ_T_NEXT_FIRE_TIME` (`SCHED_NAME`,`NEXT_FIRE_TIME`),
KEY `IDX_QRTZ_T_NFT_ST` (`SCHED_NAME`,`TRIGGER_STATE`,`NEXT_FIRE_TIME`),
KEY `IDX_QRTZ_T_NFT_MISFIRE` (`SCHED_NAME`,`MISFIRE_INSTR`,`NEXT_FIRE_TIME`),
KEY `IDX_QRTZ_T_NFT_ST_MISFIRE` (`SCHED_NAME`,`MISFIRE_INSTR`,`NEXT_FIRE_TIME`,`TRIGGER_STATE`),
KEY `IDX_QRTZ_T_NFT_ST_MISFIRE_GRP` (`SCHED_NAME`,`MISFIRE_INSTR`,`NEXT_FIRE_TIME`,`TRIGGER_GROUP`,`TRIGGER_STATE`),
CONSTRAINT `qrtz_triggers_ibfk_1` FOREIGN KEY (`SCHED_NAME`, `JOB_NAME`, `JOB_GROUP`) REFERENCES `qrtz_job_details` (`SCHED_NAME`, `JOB_NAME`, `JOB_GROUP`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
定时器执行的状态数据表
- Quartz底层会定期检查定时器运行是否正常
CREATE TABLE `qrtz_scheduler_state` (
`SCHED_NAME` varchar(120) NOT NULL, # 定时器名称
`INSTANCE_NAME` varchar(190) NOT NULL, # 定时器实例名称
`LAST_CHECKIN_TIME` bigint(13) NOT NULL, # 定时器检查的时间-检查定时器是否出现问题
`CHECKIN_INTERVAL` bigint(13) NOT NULL,
PRIMARY KEY (`SCHED_NAME`,`INSTANCE_NAME`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
锁的数据表
- 当多个Quartz访问数据表时,会根据锁的名称进行管理加锁
CREATE TABLE `qrtz_locks` (
`SCHED_NAME` varchar(120) NOT NULL,
`LOCK_NAME` varchar(40) NOT NULL, # 锁的名称
PRIMARY KEY (`SCHED_NAME`,`LOCK_NAME`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
4. Quartz测试案例
4.1 定义job任务
- 定义测试的定时任务-打印出当前处理任务的线程名和一句话
public class AlphaJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
System.out.println(Thread.currentThread().getName() + ": execute a quartz job.");
}
}
4.2 配置Job相关信息
- 使用工厂模式,创建jobDetail和Trigger配置类实例
// FactoryBean可简化Bean的实例化过程:
// 1.通过FactoryBean封装Bean的实例化过程.
// 2.将FactoryBean装配到Spring容器里
使用SpringIOC统一管理
// 3.将FactoryBean注入给其他的Bean.
例如将JobDetailFactoryBean注入给Trigger工厂,Trigger触发时,对应的jobDetail配置也被加载
// 4.该Bean得到的是FactoryBean所管理的对象实例.
例如会获取到JobDetailFactoryBean创建的jobDetail实例
配置JobDetail
// 配置JobDetail
@Bean
public JobDetailFactoryBean alphaJobDetail() {
JobDetailFactoryBean factoryBean = new JobDetailFactoryBean();
factoryBean.setJobClass(AlphaJob.class);
factoryBean.setName("alphaJob");
factoryBean.setGroup("alphaJobGroup");
factoryBean.setDurability(true); // 声明这个任务是不是持久化的
factoryBean.setRequestsRecovery(true); // 声明这个任务是不是可恢复的
return factoryBean;
}
配置Trigger
- 当仅需触发一次或者以固定时间间隔周期执行,SimpleTrigger是最适合的选择;
- 而CronTrigger则可以通过Cron表达式定义出各种复杂时间规则的调度方案:如每早晨9:00执行,周一、周三、周五下午5:00执行等。
// 配置Trigger(SimpleTriggerFactoryBean, CronTriggerFactoryBean)
@Bean
public SimpleTriggerFactoryBean alphaTrigger(JobDetail alphaJobDetail) {
SimpleTriggerFactoryBean factoryBean = new SimpleTriggerFactoryBean();
factoryBean.setJobDetail(alphaJobDetail); // 优先绑定到传入名称相同的jobDetail
factoryBean.setName("alphaTrigger"); // 名称唯一
factoryBean.setGroup("alphaTriggerGroup"); // 组名唯一
factoryBean.setRepeatInterval(3000); // 重复执行时间间隔3s
factoryBean.setJobDataMap(new JobDataMap()); // 使用默认map装数据
return factoryBean;
}
4.3 SpringBoot中配置Quartz线程池参数和数据库连接
# QuartzProperties
# 数据库的类型
spring.quartz.job-store-type=jdbc
# 调度器名称
spring.quartz.scheduler-name=communityScheduler
# 调度器id自动生成
spring.quartz.properties.org.quartz.scheduler.instanceId=AUTO
# 储存到数据库用到的类
spring.quartz.properties.org.quartz.jobStore.class=org.quartz.impl.jdbcjobstore.JobStoreTX
# 储存到数据库用到的驱动
spring.quartz.properties.org.quartz.jobStore.driverDelegateClass=org.quartz.impl.jdbcjobstore.StdJDBCDelegate
# 是否采用集群方式
spring.quartz.properties.org.quartz.jobStore.isClustered=true
# 使用的线程池-Quartz底层自带的线程池
spring.quartz.properties.org.quartz.threadPool.class=org.quartz.simpl.SimpleThreadPool
# 线程池核心数量设定
spring.quartz.properties.org.quartz.threadPool.threadCount=5
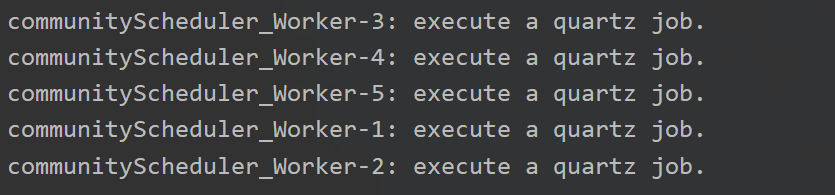
测试结果
-
定时线程创建成功
-
数据库中也储存了数据

4.5 删除job数据
- 因为入库后,今后每次启动程序,都会自动调用定时器线程处理任务
- 为了停止执行,需要将数据库中的数据删除,可以使用调度器Scheduler进行删除job数据
boolean deleteJob(JobKey jobKey)-删除job数据方法
@Autowired
private Scheduler scheduler;
/**
* 使用调度器删除job数据
*/
@Test
public void testDeleteJob() {
try {
// 传入的jobKey数据,job名称和组名
// 返回删除结果的布尔值
boolean result = scheduler.deleteJob(new JobKey("alphaJob", "alphaJobGroup"));
System.out.println(result);
} catch (SchedulerException e) {
e.printStackTrace();
}
}
测试结果
communityScheduler_Worker-1: execute a quartz job.
true















 405
405











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









