









目录
很久之前在看美团技术博客的时候,就对其中“磁盘预读和io”的章节的感觉理解得不是特别清晰,这也导致了从b-tree到b+tree的发展的背景或者说b+tree的产生背景不是特别的理解。近日正好在看索引和存储相关的资料,对这一块有了一些新的感受。因此重新梳理了一下思路。
1 磁盘相关
首先需要看下磁盘的结构,
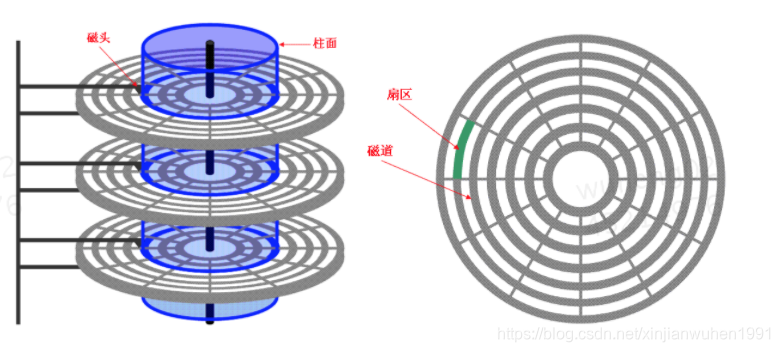
1.1 基础认知
从以上两张图片可以看出磁盘的基础核心结构。这个在以前操作系统的课程就学过,无需多言,不过有些是以前在操作系统课程上没有注意过的细节。记录下来作为特殊说明。
-
磁片和磁头之间有着非常小的间隙,不会有直接摩擦,所以磁片可以高速旋转。
-
只有停电不工作的时候,磁头才会停在停靠区。只要是有电的状态,磁片是一直处于旋转状态。
-
高速旋转的同时,磁头是可以完成读写。读写的时候现在非常高,非ssd的大多都有几百兆,比如是300m,一个扇区是0.5k。相当于读一个扇区只需要0.5/(300*1024),只要0.001ms。该时间远小于磁片移过一个扇区的时间。因此在磁片高速移动的情况下是完全可以读取数据的。
-
顺序读取为什么比跳跃式读取的效率高非常多(不需要寻道时间,只需很少的旋转时间)
-
扇区:
尽管扇区是能独立寻址的最小单位。但是因为磁片io操作成本高昂,操作系统对其进行了优化,磁盘io的时候不仅读了访问地址本身(扇区)的内容,而且对其邻近的的地址内容也会读取,本身加上邻近的组成一块,操作系统读写单位是块。两者加起来才是一页,一次io就是读写一页。
扇区是磁盘自身的属性,但是block块则是操作系统的属性,一般4个扇区作为一个块来读写。也是一次io的过程。
1.2 case
看一个实际的磁盘的参数,Megatron 747磁盘有下列参数:
1. 8个圆盘,16个盘面
2. 每个盘面有2^16次个磁道
3. 每个磁道平均有256个扇区
4. 每个扇区有4KB个字节
所以它是 16个盘面 * 2^16个磁道 * 256个扇区 * 4KB个字节 = 1TB的大小。一个磁道存放1MB字节。如果一个块是16KB,那么1个块使用4个连续的扇区,一个磁道上有32个块
一个磁道大概有 1M数据。但是一个盘面的磁道非常多,所以磁盘的容量还是比较可观的
2 索引相关
和索引相关的数据结构是经历了一个发展的过程的。二叉树(二叉平衡树) --> b-tree --> b+ tree --> lvm tree+
2.1 二叉树及b-tree问题
最简单的能用来做索引的我们能想到的自然是二叉树,但是二叉树很容易出现树深度过深的情况(即使有二叉平衡树的存在,但是不能从根本上改变树的深度随着数据的复杂度的提高而变深的情况)。度过大而造成磁盘I/O读写过于频繁,进而导致查询效率低下。
为了解决这个问题,我们很自然的想到的解决方式是多路树。 而且多路树完美契合计算机系统的io,如上面第一节所说的,磁盘的读写并不是以扇区为单位,而是以页为单位。所以我们应该在每个几点里面多塞几路信息,以减少整体树的宽度。由此发展出B树。
b-tree是一个多路树,其基本特点就是其索引数据和真实数据存在同一个物理磁盘节点上。
b-tree的查询方式是 B树必须用中序遍历的方法按序扫库,不适合范围查询。
Note:为什么从b树要到B+tree https://blog.csdn.net/zk3326312/article/details/79377680
2.2 b+tree 问题:
从通用意义上来说,b+ tree,随机的一批数据不能随机的往里面插入,得针对每一条数据,查到对应的维值,以保证数据的顺序。这样插入的时候就会出现随机io。带来的收益就是读的时候是能定位到一个磁盘块,能够高效的读取。
b+tree的一个典型的实现就是MySQL数据库的 innoDb引擎的索引
劣:B+树最大的性能问题是会产生大量的随机IO,随着新数据的插入,叶子节点会慢慢分裂,逻辑上连续的叶子节点在物理上往往不连续,甚至分离的很远,但做范围查询时,会产生大量读随机IO。
优:相当于b树,查询效率稳定,尤其是是适合范围查询和遍历。不用每次都进行中序遍历
由于b+ tree的缺点,进而LVM应运而生。
2.1 LVM树
为了克服B+树的弱点,HBase引入了LSM树的概念,即Log-Structured Merge-Trees。
为了更好的说明LSM树的原理,下面举个比较极端的例子:
现在假设有1000个节点的随机key,对于磁盘来说,肯定是把这1000个节点顺序写入磁盘最快,但是这样一来,读就悲剧了,因为key在磁盘中完全无序,每次读取都要全扫描;
那么,为了让读性能尽量高,数据在磁盘中必须得有序,这就是B+树的原理,但是写就悲剧了,因为会产生大量的随机IO,磁盘寻道速度跟不上。
LSM树本质上就是在读写之间取得平衡,和B+树相比,它牺牲了部分读性能,用来大幅提高写性能。
它的原理是把一颗大树拆分成N棵小树, 它首先写入到内存中(内存没有寻道速度的问题,随机写的性能得到大幅提升),在内存中构建一颗有序小树,随着小树越来越大,内存的小树会flush到磁盘上。当读时,由于不知道数据在哪棵小树上,因此必须遍历所有的小树,但在每颗小树内部数据是有序的。
Hbase就是LVM数据结构作为索引的一个典型
3 关于内存寻址和磁盘寻址的一些思考
内存寻址:
内存寻址取决于系统总线
磁盘的寻址:
https://blog.csdn.net/lovingprince/article/details/6118117
从直观的感受而言,cpu肯定需要告诉磁盘一个逻辑的地址,这个通信的过程不通过内存,但是不管通过什么样的io通信,但是肯定还是和cpu和内存通信类似的。
只是磁盘和内存的最小管理单位不一样而已。
磁盘一般是扇区是最小的单位,所以在chs模式下,cpu需要使用一串的比特位来告诉磁盘,到底读写哪个扇区。
最早的8位寻址方式,chs各八位,总共24位,但是有些比如扇区最早只有63个,这样可以用剩余的比特位来标识扇区。
随着寻址位数现在到23位,磁盘的空间也大大增加。
但是这个寻址位数取决于什么,个人理解取决于cpu总线和磁盘里面的寄存器大小(主要应该还是取决于磁盘里面那个单片机的寄存器)。
7 总结
数据存储是存在文件系统上的,存储的目的是为了使用,支持一些高级操作。这些高级操作有增删改查之类的。
这个文件系统如何设计还是看使用场景的增删改查的具体情况有针对性的设计。比如针对去重精度不一样,底层文件的数据结构也是不一样的。
8 疑问
问题:叶子几点只是一个record的标识还是说叶子节点就是record的存储?
美团MySQL文章有个疑问,数据是复合的数据结构的时候,搜索树应该是什么样的
9 参考资料
[磁盘在飞速旋转的时候为什么磁头还能精准的写入数据](https://www.zhihu.com/question/25422373/answer/30744239)
[硬盘的读写原理](https://www.cnblogs.com/leezhxing/p/4420988.html)
[美团技术博客-索引分析] https://tech.meituan.com/mysql_index.html
[b+ tree 的问题] https://blog.csdn.net/dbanote/article/details/8897599]














 507
507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









