







【冒泡排序】
1.冒泡排序思想:所谓冒泡法,就是按照物理现象质量轻的漂浮在上头的现象,将此现象应用在排序法中,从而形成从小到大有序记录。
2.冒泡法几种实现形式:
第一种:易懂,非标准冒泡法,将一个元素与后面所有的元素相比较,将较小的元素放在最前面。实现代码如BubbleSort1所示。
void BubbleSort1(int a[], int n)
{
int i,j;
for( i =0; i<n ; i++)
{
for( j = i+1; j<n; j++)
{
if(a[i] > a[j])
swap(&a[i], &a[j]);
}
}
}第二种:标准冒泡排序法,第一种冒泡法只是实现了排序,但并不完全算作冒泡算法,冒泡法强调的是相邻两个元素的比较后,较小的向上移动的思想,i表示已排序位置,j表示从后往前遍历冒泡比较,具体实现代码如BubbleSort2。
void BubbleSort2(int a[], int n)
{
int i,j;
for( i =0; i<n ; i++)
{
for( j = n-1; j>i; j--)
{
if(a[j] < a[j-1])
swap(&a[j], &a[j-1]);
}
}
}第三种:优化冒泡排序法,第二种冒泡法实际情况中会产生不必要的比较,如果输入记录只有两个未排序,其余已经排好序,这种情况下,如果仍采用第二种冒泡法,就产生了不必要的比较操作了,所以,优化第二种只需要加一个标志,来判断是否已经有序,有序的意思就是当从后往前遍历比较时,发现没有可交换的数据,说明后面的循环工作就没有必要进行,具体实现代码如BubbleSort3所示。
void BubbleSort3(int a[], int n)//n为数组长度
{
int i,j;
int flag = 1;//flag作为标记
for( i =0; i<n && flag; i++)//如果flag为0则退出循环,flag为0说明没有数据交换
{
flag =0 ;//初始化flag为0
for( j = n-1; j>i; j--)
{
if(a[j] < a[j-1])
{
swap(&a[j], &a[j-1]);
flag =1;//有数据交换
}
}
}
}3.完整的测试代码:
#include <stdio.h>
void print( int a[ ], int n )//打印数组
{
for ( int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
printf("\n\n");
}
void swap(int *a, int *b)//交换元素
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
void BubbleSort3(int a[], int n);//冒泡法第三种
/*void BubbleSort2(int a[], int n);//冒泡法第二种*/
/*void BubbleSort1(int a[], int n);//冒泡法第一种*/
void main()
{
int data[] = {6,5,4,3,2,1,2,3,4,5};
BubbleSort3(data, 10);
print(data, 10);
}【简单选择排序】
1.简单选择排序思想: 顾名思义,这个排序思想很简单,利用选择的方式进行排序,主要思路是选择除i位置后最小的元素与位置i的元素做替换,从数组第一个元素开始,先将第一个元素看作最小值,记录其位置,然后遍历后面所有的元素,找到比设定的最小值还小的元素,交换这两个元素,始终保持第i个元素是i..n中最小的。
2.完整的测试代码:
#include <stdio.h>
void print( int a[ ], int n )
{
for ( int i = 0; i < n; i++)
{
printf("%d ", a[i]);
}
}
void swap(int *a, int *b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
void SelectSort( int numbers[ ] , int length )
{
int i, j;
for( i = 0 ; i< length; i++)
{
int min = i;
for(j = i +1; j< length; j++)
{
if(numbers[j] < numbers[min])
min = j;
}
if( min != i )
swap(&numbers[min], &numbers[i]);
}
}
void main()
{
int data[] = {6,5,4,3,2,1,2,3,4,5};
SelectSort(data, 10);
print(data, 10);
}【直接插入排序】
1.直接插入排序思想:将一个待排序记录插入到有序的记录中,从而得到一个新的,记录数加1的记录组中,如同玩扑克牌理牌的过程,来一个新牌,找到它合适的位置插入就行。
2.完整测试代码:
#include <stdio.h>
void print( int a[ ], int n )
{
for ( int i = 1; i < n; i++)
{
printf("%d ", a[i]);
}
}
void InsertSort( int numbers[ ] , int length )
{
int i, j;
for( i = 2 ; i< length; i++)//第一个数据i=1直接插入,从第2个开始判断
{
if( numbers[i] < numbers[i-1])//如果待插入数据比最后一个记录小的时候可以进行下一步,否则直接插入到最后边
{
numbers[0] = numbers[i];//将待插入数据暂存在哨兵位置
for( j = i -1 ; numbers[j]> numbers[0]; j--)//将每一个比待插入记录大的元素向后移一位
{
numbers[j+1] = numbers[j];
}
numbers[j+1] = numbers[0];
//空出来的位置就是待插入记录应该插入的位置,下标j元素要小于待插入元素,所以此时应插在j的下一位置即j+1
}
}
}
void main()
{
int data[] = {0,6,5,4,3,2,1,2,3,4,5};//数组中i=0为哨兵,为了后面暂存记录用,没有实际意义
InsertSort(data, 11);
print(data, 11);
}
【希尔排序】
1.希尔排序思想:对于少量数据排序来说,插入排序高效许多,如果数据量较多时,如何改进插入排序呢。对于数据记录较多时,可以进行分组成数据量小的子序列,对每组子序列分别进行直接插入排序,从而得到基本有序的数列,基本有序就是小的基本在前面,大的基本在后面,不大不小的基本在中间,而如何分组成为难点,这里采用跳跃分割的策略,即将相距某个增量的记录组成一个子序列,再对每个子序列进行直接插入排序,就能够保证基本有序,而不会是局部有序。
2.增量的选取:对于大部分资料,均无法说明最好的增量序列应该如何取,但从能够获得不错的效率角度,还是可以得到的,具体请自行参考书籍。本实现方案采用增量increment= increment/3+1的方式,最后一个increment为1。
3.完整测试代码:
#include <stdio.h>
void print( int a[ ], int n )
{
for ( int i = 1; i < n; i++)
{
printf("%d ", a[i]);
}
}
void ShellSort( int numbers[ ] , int length )
{
int i, j;
int increment = length - 1;
do
{
increment = increment/3 + 1;
for( i = increment + 1 ; i < length ; i ++)
{
if( numbers[ i ] < numbers [ i - increment ] )
{
numbers[ 0 ] = numbers[ i ] ;
for ( j = i - increment ; j > 0 && numbers[ j ] > numbers[ 0 ] ; j -= increment )
{
numbers[ j + increment ] = numbers[ j ];
}
numbers[ j + increment ] = numbers[ 0 ];
}
}
}while(increment > 1) ;
}
void main()
{
int data[] = {0,9,1,5,8,3,7,4,6,2};
ShellSort(data, 10);
print(data, 10);
}4.ShellSort的while循环形式:
void ShellSort( int numbers[ ] , int length )
{
int i, j;
int increment = length - 1;
while( increment > 1)
{
increment = increment/3 + 1;
for( i = increment + 1 ; i < length ; i ++)//从increment后一个开始每一个都和其间隔为increment的前面的数据相比较,进行直接插入排序
{
if( numbers[ i ] < numbers [ i - increment ] )
{
numbers[ 0 ] = numbers[ i ] ;//i=0位置为哨兵
for ( j = i - increment ; j > 0 && numbers[ j ] > numbers[ 0 ] ; j -= increment )
{
numbers[ j + increment ] = numbers[ j ];
}
numbers[ j + increment ] = numbers[ 0 ];
}
}
}
}【堆排序】
1.堆的概念和性质:堆其实质就是一个完全二叉树,分为大堆和小堆,大堆根节点为最大的,每个结点的值都大于或者等于其左右孩子结点的值,小堆根节点最小,每个结点的值都小于或者等于其左右孩子结点的值,结点编号是按照层序遍历方式,结点从1开始编号,如下图所示:
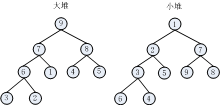
2.特别注意:对于一棵完全二叉树来说,需要关注一点性质,即:
如果i = 1, 则结点i就为二叉树的根;
如果i > 1, 则双亲结点就为i/2取整;
结点位置为i,其左右孩子结点位置分别为2*i,2*i+1。
3.堆排序思想:利用堆进行排序,将待排序的序列构造成大堆,整个序列最大值就是堆顶的根节点,排成从小到大的有序序列,只需要将堆顶和从最后一个元素开始交换,将剩余的n-1个序列重新构造成一个大堆,如此反复执行,直至所有的元素都与堆顶交换过,从而得到有序序列。
4.完整测试代码:
#include<stdio.h>
void HeapAjust( int a[ ], int i, int n);//重建大堆
void HeapSort( int a[ ], int n);//堆排序
void swap(int *a, int *b);//交换元素
void print( int a[ ], int length );//打印
void print( int a[ ], int length )
{
for ( int i = 1; i < length; i++)
{
printf("%d ", a[i]);
}
}
void swap(int *a, int *b)
{
int temp;
temp = *a;
*a = *b;
*b = temp;
}
void HeapSort( int a[ ], int n)//n为最后一个元素下标
{
int i;
for( i = n/2; i > 0 ; i-- )//待排序数据建成大堆
HeapAjust( a, i, n );
//交换根节点与最后,排成有序序列
for( i = n; i > 1; i-- )
{
swap( &a[ i ], &a[ 1 ]);
HeapAjust( a, 1, i-1 );
}
}
void HeapAjust( int a[ ], int i, int n)
{
int temp = a[ i ] ;
for( int j = 2*i; j <= n; j *= 2 )
{
if( j < n && a[ j ] < a[ j+1 ] )//j一定要小于n如果等于n,n+1超过界限了,n+1是已经排好序的
++j;
if( temp >= a[ j ] )
break;
a[ i ] = a[ j ];
i = j ;
}
a[ i ] = temp;
}
void main( )
{
int a[ ] ={0 ,50, 10, 90 ,30, 70, 40, 80, 60, 20 };
HeapSort( a, 9 );
print( a, 10 );
}【归并排序】
1.归并排序思路: 归并排序算法的基本操作是通过两两合并排序后再合并,最终得到有序序列,例如:
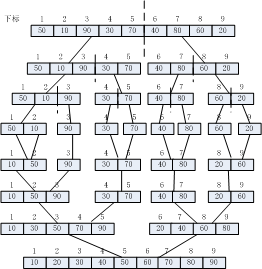
将待排序序列分为两部分,分别进行排序,合并时对两对序列逐位比较,较小者先放入暂存序列中,这里需要辅助数组。
2.完整测试代码【递归】:
#include<stdio.h>
#define MAX 10
//打印
void print( int a[ ], int n )
{
for( int i = 1; i < n ; i++ )
printf("%d ", a[ i ]);
printf("\n");
}
void Merge( int a[ ], int temp[ ] , int i , int m, int n )//将temp[i...m]与temp[m+1...n]有序归并到a[i...n]中
{
for( int k = i; k <= n; k++)
temp[k]= a[k];
int j = m +1;
for(int k = i; k <=n ; k++)
{
if(i > m)
a[k] = temp[j++];
else if (j > n)
a[k] = temp[i++];
else if (temp[i] < temp[j] )
a[k] = temp[i++];
else
a[k] = temp[j++];
}
}
void MergeSort( int a[ ] , int temp[ ], int start, int end)
{
int mid;
if( start == end)
return ;
else
{
mid = (start + end)/2;
MergeSort( a, temp, start, mid );
MergeSort( a, temp, mid + 1, end );
Merge( a, temp , start, mid , end );
}
}
void main( )
{
int a[MAX] = {0, 50 , 10 , 90 , 30 , 70 , 40, 80 , 60 , 20};
int temp[MAX];
MergeSort( a, temp, 1, MAX-1);
print(a, MAX);
}3.完整测试代码[非递归]
#include<stdio.h>
#include<stdlib.h>
#define INF 0x7ffffff
void Merge( int a[ ] , int l , int m, int r);
void MergeSort( int a[ ] , int l , int r)
{
int len = r - l +1;//序列全长
for( int gap = 1; gap <= len ; gap = gap*2 )//子序列长度以2倍递增
{
int left = l ;//左边界
while( left < r)
{
int mid = left + gap - 1 ;//中间位置
int right = left + 2*gap -1 ;//右边界
if( mid > r )//中间边界大于序列末尾边界,退出循环
break;
if( right > r )//右边界大于序列末尾边界,右边界就为末尾
right = r ;
if( right == mid )//右边界等于中间位置,结束循环
break;
Merge( a, left, mid, right );//合并a[left...mid]和a[mid+1...right]
left = right + 1;//下一子序列
}
}
}
void Merge( int a[ ] , int l , int m, int r)
{
int i , j ;
int n1 = m - l +1;//序列1长度
int n2 = r - m ;//序列2长度
int *left = new int[ n1+1 ];//序列1动态数组,子序列长度不定,所以动态开辟空间left[0...n1-1]
int *right = new int[ n2 +1 ];//序列2动态数组,子序列长度不定,所以动态开辟空间right[0...n2-1]
for( i = 0 ; i < n1 ; i++ )
left[ i ] = a[ l+i ];//序列1初始化
left[ n1 ] = INF;//序列最后一个值为无穷大
for( i = 0 ; i < n2 ; i++ )
right[ i ] = a[ m+1+i ];//序列2初始化
right[ n2 ] = INF;
i = j = 0 ;
for( int k = l ; k <= r ; k++ )//序列1,2有序合并,将数据存回a[l...r]中
{
if( left[ i ] < right[ j ] )
a[ k ] = left[ i++ ] ;
else
a[ k ] = right[ j++ ];
}
}
void main( )
{
int a[ ] = {7, 5, 4, 6, 9, 2, 1, 0, 3, 8};
MergeSort(a, 0, 9 );
for(int i = 0; i < 10; i++ )
printf("%d ", a[ i ]);
printf("\n\n");
}
----------【快速排序】
1.快速排序思想:通过一次排序将待排序列分为两部分,其中一部分的关键字要比另一部分的关键字小,基本操作通过对每个关键字处理,使其左边的元素都小于它,右边的元素都大于它,以达到整体有序。具体过程可以参考本博客快速排序算法
http://blog.csdn.net/xinyu913/article/details/46054265
2.完整测试代码:
#include<stdio.h>
void QuickSort( int a[ ], int low, int high);
int Partition( int a[ ], int low, int high); //此函数目的就是让选中的关键字在数组中其左面的记录都小于它,右边的都大于它
void swap( int a[ ], int i, int j )
{
int temp = a[ i ];
a[ i ] = a[ j ];
a[ j ] = temp;
}
int Partition( int a[ ], int low, int high)
{
int pivotkey = a[ low ];//选择子数组第一个记录作为枢轴记录
while( low < high )
{
while( low < high && a[high] >= pivotkey )
high--;
swap(a, low, high );
while( low < high && a[low] <= pivotkey )
low++;
swap(a, low, high );
}
return low;
}
void QuickSort( int a[ ], int low, int high)
{
int pivot;
if( low < high)
{
pivot = Partition( a, low, high );
QuickSort( a, low, pivot-1 );
QuickSort( a, pivot+1, high );
}
}
void print( int a[ ] , int low, int high)
{
for( int i = low; i <= high; i++ )
printf( "%d ", a[ i ] );
printf("\n\n");
}
void main( )
{
int a[ ] = {0,50,10,90,30,70,40,80,60,20};
QuickSort( a, 1, 9);
print( a, 1, 9);
}
【总体性能比较】
从一下几个角度进行分析以上几种排序性能:
1.算法的简单性:
简单: 冒泡,简单选择, 直接插入
改进:希尔,堆,归并,快速
2.平均时间复杂度
改进算法肯定要比简单算法强,但是其中希尔是改进中最弱的,堆,归并,快速都是O(nlgn),简单算法都是O(n^2),希尔介于中间。
3.最好情况
冒泡和直接插入略胜一筹,如果待排数据总是基本有序,没必要用改进算法,用简单算法就可以。
4.最坏情况
堆排序和归并排序强于快速排序和其他简单排序。
5.空间复杂度
归并需要辅助空间必然空间复杂度相对要高点O(n),快排也需要O(lgn)~O(n),其他均为O(1)。
6.稳定性
归并比较稳定
7.处理数据量
简单算法适用于数据量少,数据量多是用改进,而快排更优化,对快排设置阀值,低于阀值采用直接插入排序,将会优化快排效率。
【参考文献】
<大话数据结构><算法导论>















 3794
3794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









