







在本篇博文中,我将介绍一些大边界分类背后的数学原理。你将对支持向量机中的优化问题,以及如何得到大边界分类器,产生更好的直观理解。
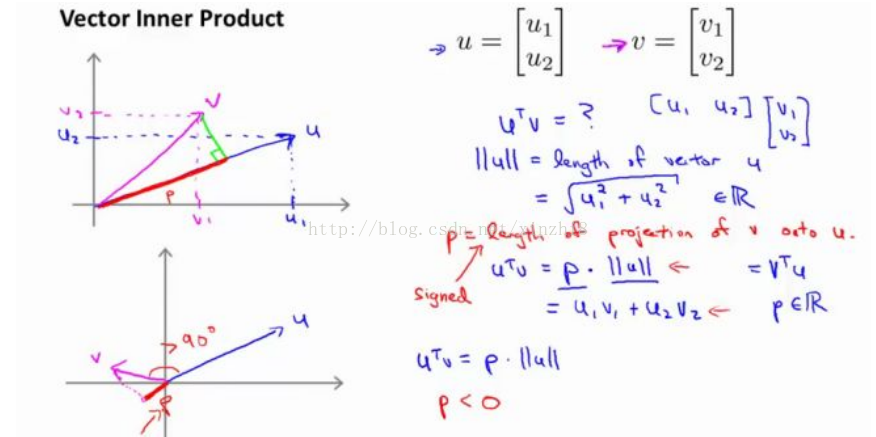
首先,让我来给大家复习一下关于向量内积的知识。假设我有两个向量,u 和 v 我将它们写在这里。两个都是二维向量,我们看一下,uT v 的结果。u T v 也叫做向量 u 和 v 之间的内积。由于是二维向量,我可以将它们画在这个坐标系上。我们说,这就是向量 u 即在横轴上,取值为某个 u 1 ,而在纵轴上,高度是某个 u 2 作为 u 的第二个分量。现在,很容易计算的一个量就是向量 u 的范数。||u|| 表示 u 的范数,即 u 的长度,即向量 u 的欧几里得长度。根据毕达哥拉斯定理:
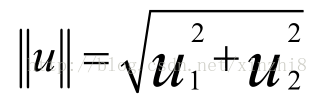
这是向量 u 的长度,它是一个实数。现在你知道了这个的长度是多少了。我刚刚画的这个向量的长度就知道了。现在让我们回头来看向量 v ,因为我们想计算 内积。v 是另一个向量,它的两个分量 v 1 和 v 2 是已知的。向量 v 可以画在这里,现在让我们来看看如何计算 u 和 v 之间的内积。这就是具体做法,我们将向量 v 投影到向量 u 上,我们做一个直角投影,或者说一个 90 度投影将其投影到 u 上,接下来我度量这条红线的长度。我称这条红线的长度为 p,因此 p 就是长度,或者说是向量 v 投影到向量 u 上的量,我将它写下来,p 是 v投影到向量 u 上的长度,因此可以将 uT v=p●u ,或者说 u的长度。这是计算内积的一种方法。如果你从几何上画出 p 的值,同时画出 u 的范数,你也会同样地计算出内积,答案是一样的。另一个计算公式是:uT v 就是[u1 u2] 这个一行两列的矩阵乘以 v。因此可以得到 u 1 ×v 1 + u 2 ×v 2 。根据线性代数的知识,这两个公式会给出同样的结果。顺便说一句,uT v=v T u。因此如果你将 u 和 v 交换位置,将 u 投影到 v 上,而不是将 v投影到 u 上,然后做同样地计算,只是把 u 和 v 的位置交换一下,你事实上可以得到同样的结果。申明一点,在这个等式中u 的范数是一个实数,p 也是一个实数,因此 uT v 就是两个实数正常相乘。

这就是我们先前给出的支持向量机模型中的目标函数。为了讲解方便,我做一点简化,仅仅是为了让目标函数更容易被分析。
我接下来忽略掉截距,令θ 0 = 0,这样更容易画示意图。我将特征数 n 置为 2,因此我们仅有两个特征 x 1 和 x 2 ,现在 我们来看一下目标函数,支持向量机的优化目标函数。当我们仅有两个特征,即 n=2 时,这个式子可以写作:
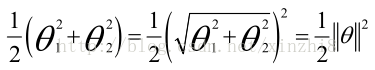
我们只有两个参数θ 1 和θ 2 。你可能注意到括号里面的这一项是向量θ的范数,或者说是向量θ的长度。我的意思是如果我们将向量θ写出来,那么我刚刚画红线的这一项就是向量θ的长度或范数。这里我们用的是之前学过的向量范数的定义事实上这就等于向量θ的长度。当然你可以将其写作θ 0 、θ 1 、θ 2 ,如果θ 0 等于 0,那就是θ 1 θ 2 的长度。在这里我将忽略θ 0 ,这样来写θ的范数,它仅仅和θ 1 θ 2 有关。但是,数学上不管你是否包含θ 0 ,其实并没有差别,因此在我们接下来的推导中去掉θ 0 不会有影响这意味着我们的目标函数是等于1/2*||θ||^2,因此支持向量机做的全部事情就是 极小化参数向量θ范数的平方或者说长度的平方现在我将要看看这些项:θT X更深入地理解它们的含义。给定参数向量θ给定一个样本 x,这等于什么呢? 在前一页幻灯片上,我们画出了在不同情形下,uT v 的示意图,我们将会使用这些概念,θ和 x (i) 就类似于 u 和 v 。
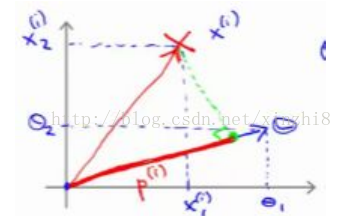
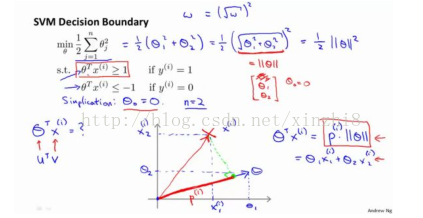
让我们看一下示意图:我们考察一个单一的训练样本,我有一个正样本在这里,用一个叉来表示这个样本x (i),意思是在水平轴上取值为x 1(i),在竖直轴上取值为x2 (i)。这就是我画出的训练样本。尽管我没有将其真的看做向量。它事实上就是一个始于原点,终点位置在这个训练样本点的向量。现在,我们有一个参数向量我会将它也画成向量。我将θ 1 画在横轴这里,将θ 2 画在纵轴这里,那么内积θ T x (i) 将会是什么呢?使用我们之前的方法,我们计算的方式就是我将训练样本投影到参数向量θ,然后我来看一看这个线段的长度,我将它画成红色。我将它称为 p(i) 用来表示这是第 i 个训练样本在参数向量θ上的投影。根据我们之前幻灯片的内容,我们知道的是θ T x (i) 将会等于 p 乘以向量 θ 的长度或范数。这就等于θ1 *x1(i)+θ2*x2 (i)这两种方式是等价的,都可以用来计算θ和 x (i) 之间的内积。
这告 诉了 我 们 什 么 呢 ? 这 里 表 达 的 意 思 是 :

现在让我们考虑下面这里的训练样本。现在,继续使用之前的简化,即θ 0 =0,我们来看一下支持向量机会选择什么样的决策界。这是一种选择,我们假设支持向量机会选择这个决策边界。这不是一个非常好的选择,因为它的间距很小。这个决策界离训练样本的距离很近。我们来看一下为什么支持向量机不会选择它。对于这样选择的参数θ,可以看到参数向量 θ 事实上是和决策界是 90 度正交的,因此这个绿色的决策界对应着一个参数向量 θ指向这个方向,顺便提一句θ 0 =0 的简化仅仅意味着决策界必须通过原点 (0,0)。现在让我们看一下这对于优化目标函数意味着什么。
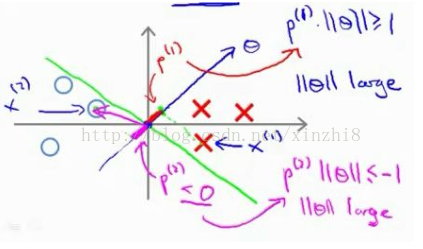
比如这个样本,我们假设它是我的第一个样本 x (1) ,如果我考察这个样本到参数θ的投影,投影是这个短的红线段,就等于 p (1) ,它非常短。类似地,这个样本如果它恰好是 x (2) , 我的第二个训练样本,则它到θ的投影在这里。我将它画成粉色,这个短的粉色线段是 p (2) ,即第二个样本到我的参数向量θ的投影。因此,这个投影非常短。p (2) 事实上是一个负值,p (2) 是在相反的方向,这个向量和参数向量θ的夹角大于 90 度,p (2)的值小于 0。我们会发现这些 p (i) 将会是非常小的数,因此当我们考察优 化 目 标 函 数 的 时 候 , 对 于 正 样 本 而 言 , 我 们 需 要p (i)*||θ||>=1,但是如果 p (i) 在这里非常小,那就意味着我们需要θ的范数 非 常 大 .因 为如 果 p (1) 很 小,而 我们 希 望p (1)*||θ||>=1,令其实现的唯一的办法就是这两个数较大。如果 p (1) 小,我们就希望θ的范数大。类似地,对于负样本而言我们需要p (2)*||θ||<= -1。我们已经在这个样本中看到 p (2) 会是一个非常小的数,因此唯一的办法就是θ的范数变大。但是我们的目标函数是希望找到一个参数θ,它的范数是小的。因此,这看起来不像是一个好的参数向量θ的选择。
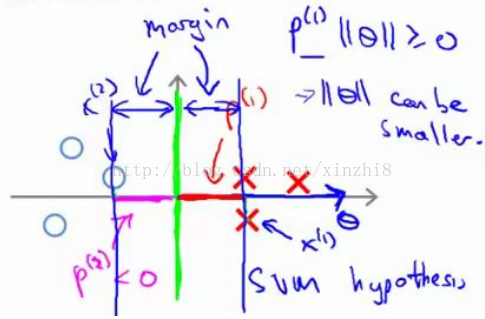
相反的,来看一个不同的决策边界。比如说,支持向量机选择了这个决策界,现在状况会有很大不同。如果这是决策界,这就是相对应的参数θ的方向,因此,在这个决策界之下,垂直线是决策界。使用线性代数的知识,可以说明,这个绿色的决策界有一个垂直于它的向量θ。现在如果你考察你的数据在横轴 x 上的投影,比如这个我之前提到的样本,我的样本 x (1) ,当我将它投影到横轴 x 上,或说投影到θ上,就会得到这样的p (1) 。它的长度是 p (1) ,另一个样本,那个样本是 x (2) 。我做同样的投影,我会发现,p (2) 的长度是负值。你会注意到现在 p (1) 和p (2) 这些投影长度是长多了。如果我们仍然要满足这些约束,p (1)*||θ||>1,则因为 p (1) 变大了,θ 的范数就可以变小了。因此这意味着通过选择右边的决策界,而不是左边的那个,支持向量机可以使参数θ的范数变小很多。因此,如果我们想令θ的范数变小,从而令θ范数的平方变小,就能让支持向量机选择右边的决策界。这就是支持向量机如何能有效地产生大间距分类的原因。看这条绿线,这个绿色的决策界。我们希望正样本和负样本投影到θ的值大。要做到这一点的唯一方式就是选择这条绿线做决策界。这是大间距决策界来区分开正样本和负样本这个间距的值。这个间距的值就是 p (1) p (2) p (3) 等等的值。通过让间距变大,即通过这些 p (1) p (2) p (3) 等等的值,支持向量机最终可以找到一个较小的θ范数。这正是支持向量机中最小化目标函数的目的。















 317
317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









