









何谓索引
如《存储(一)—— 序言》中所说,找出自己想要的东西并不难,难的是从大量自己不想要的信息中飞快的找出自己想要的东西。
缓存已经帮我们把数据从更远更慢的介质提前移动到了更近更快的介质上,即便如此,从百万、千万、上亿条的数据中找出我们想要的那条数据,也并非易事。
好比查字典,不可能一页一页翻,所以,字典都是有目录的,这个目录,就是索引了。
道理都是一样的,Redis的目录是hash,MySQL的目录是B+树,HBase的目录是LSM树,全文检索是倒排索引。。。
都是查找数据,咋还有这么多类型的索引,下面让我们来看看每一种索引都是为了解决什么问题而出现的,其背后的原理又是什么?
哈希
哈希大概是我们最熟悉的数据结构了,key经过哈希后直接映射到数组下标,使得hash得以拥有O(1)的时间复杂度。
虽然大家已经烂熟于心,这里还是画一下,看看这个O(1)是怎么来的,以及为什么哈希并不是万能的。
哈希表的结构如下:
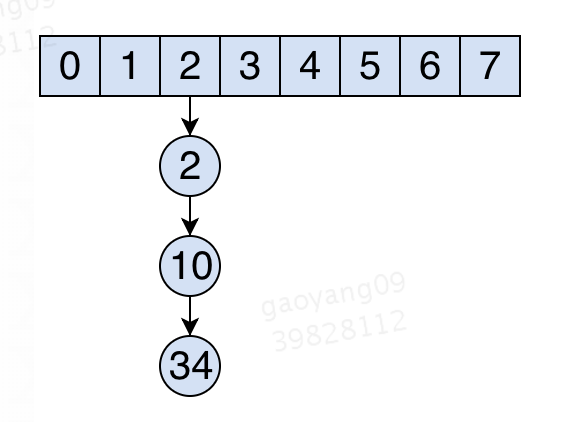
数组长度是8,现在我们要找key=10的节点,寻找过程是这样的:
- 10对8取模得到数组下标,10 % 8 = 2;
- 取出数组下标2中的链表
- 遍历链表,找到key=10的节点
数组通过下标访问是O(1)的,之后遍历链表时,单独对链表这种数据结构来说,是O(n)的,但是考虑到链表的长度相对哈希表中所有的元素数量来说,基本可以无视了,举个例子,hash表中有1000W个元素,链表的长度是8,这个8相对于1000W来说,可以忽略了,所以,hash的访问速度整体是O(1)的。
再来看一个现实世界中的例子,拿字典来说,我们要找阿拉伯数字”3“,查过目录之后,我们知道”3“在第2页,假使我们能一次翻到第二页,然后发现第二页中有3个词,于是我们不得不”遍历“,找到数字”3“,而这个遍历第二页的过程相对于整本字典上万字来说,也是可以忽略的。
哈希的不足
哈希的好处已经很明显:O(1)的时间复杂度。
为何hash索引并不是应用最广泛(个人观点哈)的索引结构呢?
主要是有下面几个原因:
无序
hash中存储的元素只适合随机查找,不适合范围扫描。而我们对于数据的查询需求中,很常见的一类正是范围扫描:
select * from table where id between a and b
对于这种场景,hash是无能为力的。
既然无序,自然对于排序的支持也是无能为力的,比如这种:
select * from table where id > a order by id limit 10
联合索引
我们常说,联合索引怎么怎么样,经常提到联合索引最左匹配原则,这都是对B+树而言的,比如有两个字段a,b建立了联合索引,那么,如果索引的结构是B+树,下面的语句是可以使用索引的:
select * from table where a = 10;
但是,如果此时索引结构是hash,那就和最左匹配啊,联合索引啊无缘了,大家可以想想为什么会这样。
性能以及占用的空间和散列函数的好坏有关
在极端情况下,我们的hash结构可能会变成这样:
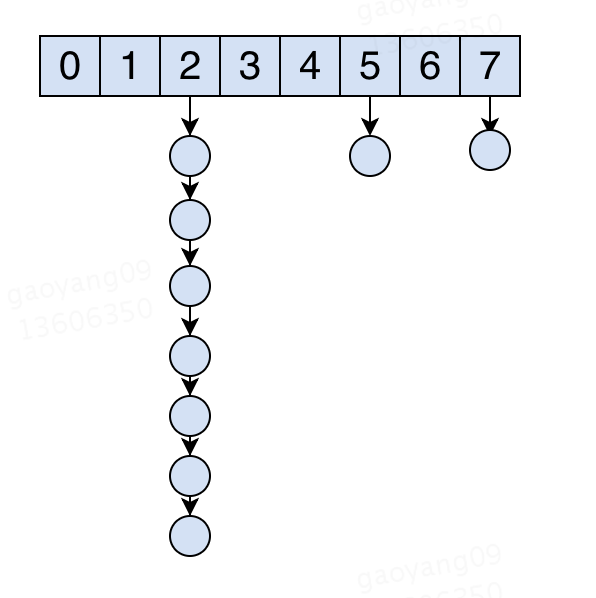
这样的结构下,在一长串的链表中找一个key就变得很慢了。
当然,为了解决这个问题,你可以这么搞:
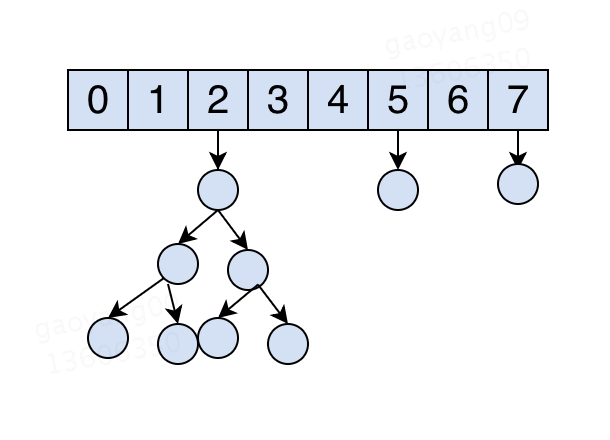
然并卵,再好的散列函数,在样本足够多的情况下,hash表中各个槽位链表的长度最终也是个正态分布,有长有短。
有兴趣的同学可以想想为何java中hashmap的默认负载因子选了0.75,而不是其他值?
局部性原理
想这样一个问题,如果你的key足够多,多到内存装不下了,这时hash索引必修有一部分存储到磁盘上,内存中hash操作很快,但是到了磁盘上,这就是噩梦了,
如存储(三)—— 局部性原理中提到的,空间上相近的数据在hash中会被散开到很远的地方,此时局部性原理几乎完全无效,于是乎,大量的随机I/O到来,
B+树
关于B+树的内容,接下来会有单独一篇来详细介绍,这里只简要(但是很重要)说明B+树是为了解决怎样的问题而诞生的。
但凡数据集,绝大多数都会涉及到排序,这也是hash索引不能广泛应用的原因,而一旦涉及到排序,那么索引就变成在有序的数据中查找特定条目的工具,因为是在有序数据集中的查找,那么其时间复杂度最理想的状态下也是O(logn)的,这一点上是比不了hash的O(1)的,anyway,其带来的好处是远远大于这个效率的提升的,这个下一篇会讲到。
LSM Tree
全称log structed merge tree,如果说关系型数据库中索引是B+树的天下,那么在NoSQL领域,LSM就是夜空中最亮的星了。这是一种将机械磁盘的顺序写发挥到极致的适合大规模数据量写入的一种结构,初次接触时,其思想深深的震撼了我一把,这个下下篇会详细介绍。
倒排索引
还有一类比较特殊的索引,光是听名字就很让人好奇,倒排索引,倒排?咋还倒排啊?
这类索引主要用在全文检索中,最常用的场景,想想你打开搜索引擎,然后输入一个词,点击搜索之后,所有包含这个词的网页都会出现在下面。如果好多网页都包含这个关键词,那么怎么决定这些网页展示的顺序呢?这个和检索的结果的“评分”有关,这个评分背后涉及到一系列的复杂的算法,这里不讲(其实是我不懂。。。)。
当然,对于某些搜索引擎来说,设个网页展现的顺序已经不仅仅是技术范畴内的事情了,还会涉及到商业利益,甚至涉及到人的良知,比如没有底线的竞价排名,这是悲伤的话题,尤其是在天朝。
倒排
来解释一下啥叫倒排,假想你是工程师,给了你5篇文章,要你做一个系统,输入一个词,如果文章中包含这个词的话,就把这篇文章展示出来。
暴力解法
遍历永远是最直接最简单但通常不是最高效的办法,哈哈哈。
每篇文章搜一遍,有这个词就展示出来。
5篇文章,无可厚非,如果是50亿篇呢?
分词
其实你可以这么搞:
- 把每篇文章中的每个词都单独拿出来(分词),扔到一个集合里,比如hashmap
- hashmap的key是一个单词(词语),value呢?value是包含这个词的所有文章的编号列表。
- 对与检索词,直接从hashmap中找出来文章编号列表,根据编号找到文章展示出来就OK了。
来画一个示意图:

关于分词,其背后也有很多考虑,比如英文分词,中文分词,无意义词(is, are, a, 的)的过滤等等,这里不展开。
到这里已经明白倒排索引这个名字的由来了吧,所谓倒排,是因为我们不是从一篇文章中查找某个词,而是反过来,从某个词查找包含这个词的文章,所以,这种索引就叫做倒排索引了。
trie(字典树)
对于分出来的词,数量少的话还可以用hashmap或者平衡树来存储,但是如果词特别多的时候,从存储空间上来说,就不划算了。
如果这考虑小写英文字母的话,英文字母一共只有26个,也就是说,存储的单词越多,重复的字母就越多,既然重复,那就可能有压缩的空间,压缩又要保持查询的高效,这时就是trie的领域了。
trie的核心思想在于公共前缀。
假设我们有abc cd ad abcd 这样四个词要存储,如果用trie存储的话,是这个样子的:
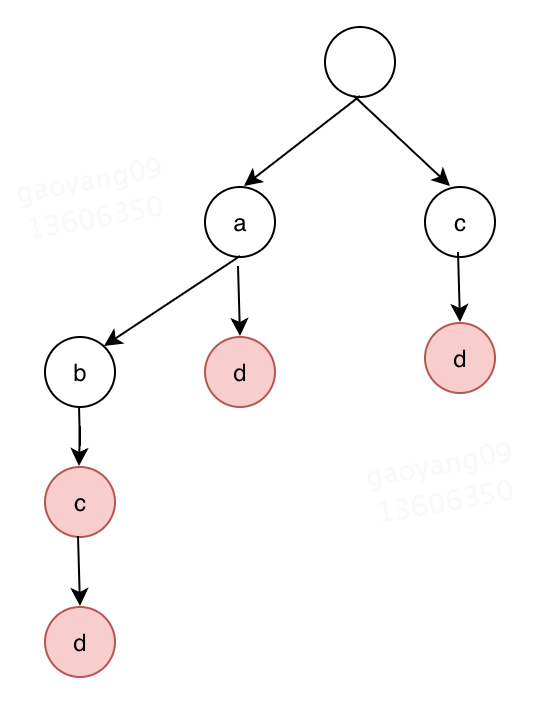
深色的节点表示从跟节点起到本节点是一个完整的词。
这样一来,当单词很多时,依靠共用公共前缀,大大节省了存储空间,而且,这种数据结构查询起来也是很快的。
真是美妙的数据结构。
想想各大网站的域名解析,DNS服务器中茫茫多的域名们也是以这种方式存储的。
本篇介绍了索引的由来和作用,以及常见的几种索引结构,hash索引和倒排索引说的多一点,接下来两篇会详细介绍B+树和LSM树。















 2808
2808











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









