







本文总结一下JDK中集合类的实现。首先看下集合类的继承图:
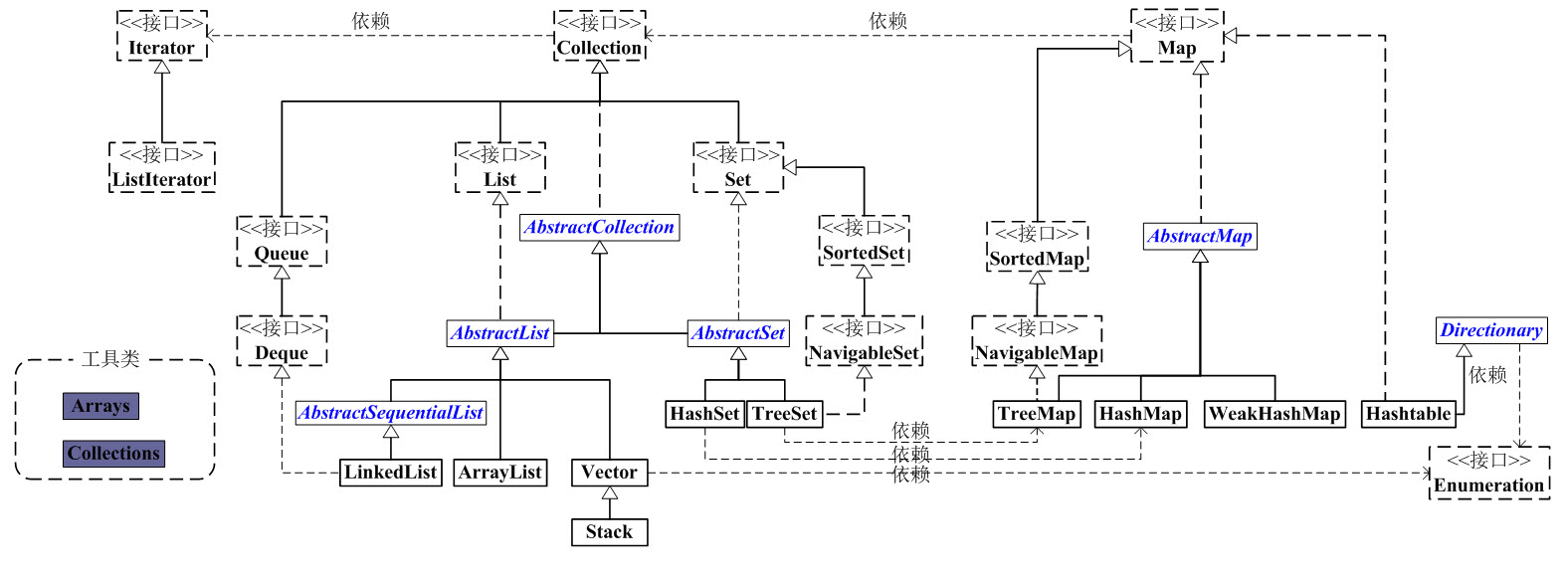
可看出,接口主要有Collection和Map两大主线,其中Collection又有List和Set两个分支。List是一个有序的队列,每一个元素都有它的索引;而Set是一个不允许有重复元素的集合。Map是一个key-value键值对映射,AbstractMap是个抽象类,它实现了Map接口中的大部分API。Hashtable继承于Dictionary,也实现了Map接口。
下面逐个说明:
ArrayList
ArrayList 是一个数组队列,相当于动态数组。与Java中的数组相比,它的容量能动态增长。它继承于AbstractList,实现了List,RandomAccess,Cloneable,java.io.Serializable接口。ArrayList不是线程安全的。
ArrayList包含两个重要的对象:elementData和size。
size是动态数组的实际大小,这里主要说说elementData。它是Object[]类型的数组,保存了添加到ArrayList中的元素。elementData是个动态数组,可通过构造函数ArrayList(int initialCapacity)来执行它的初始容量为initialCapacity;如果通过不含参数的构造函数ArrayList()来创建ArrayList,则elementData的容量默认是10。当ArrayList容量不足以容纳全部元素时,ArrayList会重新设置容量= (原始容量x3) / 2 + 1。
ArrayList转对象数组方式:Integer[] newText = (Integer[])v.toArray(new Integer[0]);
LinkedList
LinkedList是继承于AbstractSequentialList的双向链表,可被当作堆栈、队列或双端队列进行操作。实现了List,Deque,Cloneable,java.io.Serializable接口。LinkedList不是线程安全的。
LinkedList包含两个重要的成员:header和size。
size是双向链表中节点的个数,而header是双向链表的表头,它是双向链表节点所对应的类Entry的实例。Entry中包含成员变量: previous、next和element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。
LinkedList是通过双向链表去实现的,因此它的顺序访问会非常高效,而随机访问效率比较低。它的索引是通过一个计数索引值来实现的。例如,当调用get(int location)时,首先会比较“location”和“双向链表长度的1/2”;若前者大,则从链表头开始往后查找,直到location位置;否则,从链表末尾开始先前查找,直到location位置。
Vector
Vector是矢量队列,继承于AbstractList,实现了List、RandomAccess和Cloneable接口。Vector是线程安全的。
Vector包含了3个成员变量:elementData、elementCount和capacityIncrement。
elementData是Object[]类型的数组,它保存了添加到Vector中的元素。如果初始化Vector时,没指定elementData的大小,则默认大小10。随着Vector中元素的增加,Vector的容量也会动态增长。
elementCount是动态数组的实际大小。
capacityIncrement是动态数组的增长系数。如果在创建Vector时指定了capacityIncrement的大小,则每次当Vector中动态数组容量增加的大小都是capacityIncrement。
Vector的线程安全,是通过基本在所有方法上都加了synchronized关键字实现的。
HashMap
HashMap是一个散列表,存储的内容是key-value键值对映射。继承于AbstractMap,实现了Map、Cloneable和java.io.Serializable接口。HashMap不是线程安全的。HashMap的key、value都可以为null,映射不是有序的。
HashMap包括几个重要的成员变量:table、size、threshold、loadFactor和modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的key-value键值对都是存储在Entry数组中的。
size是HashMap的大小,是HashMap保存的键值对的数量。
threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold=容量 * 负载因子,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
loadFactor即负载因子,哈希表在其容量自动增加之前可以达到多满的一种尺度。默认为0.75。
modCount是用来实现fail-fast机制的。
HashMap是先调用Object的hashCode方法(native实现),然后indexFor(与table数组长度-1取模)得到对应数组下标。

Hash冲突:当put()操作的key与entry数组有冲突时,新的entry仍然会被安放在对应的索引下标内,替换原有的值。同时,为了保证旧值不丢失,会将新的entry的next指向旧值。这就实现了在一个数组索引空间内存放多个值。为了避免冲突,需要将hashCode()和hash()方法实现的足够好,尽可能减少冲突的产生。
HashMap将key为null的元素都放在table的位置0处。
HashTable
HashTable也是一个散列表,存储的内容是键值对(key-value)映射。继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。Hashtable是线程安全的。Hashtable的key、value都不可以为null,映射不是有序的。
HashMap包括几个重要的成员变量:table、size、threshold、loadFactor和modCount。基本同HashMap一致,不再赘述。
HashTable的线程安全,是通过基本在所有方法上都加了synchronized关键字实现的。
LinkedHashMap
LinkedHashMap是一个有序的key-value集合,继承于HashMap,实现了Map接口。按插入的顺序排序,不是线程安全的,不允许使用 null 值和 null 键。
LinkedHashMap底层使用哈希表与双向链表来保存所有元素。重新定义了数组中保存的元素 Entry,该 Entry 除了保存当前对象的引用外,还保存了其上一个元素 before 和下一个元素 after 的引用,从而在哈希表的基础上又构成了双向链接列表。
初始化时增加 accessOrder 参数,默认为 false,代表按照插入顺序进行迭代;设置为 true时代表以访问顺序进行迭代。
在进行put等元素操作的时候,LinkedHashMap会对自己维护的双向链表执行相同的操作。
TreeMap
TreeMap是一个有序的key-value集合,通过红黑树实现。继承于AbstractMap,实现了NavigableMap(支持一系列的导航方法)、Cloneable和java.io.Serializable接口。排列顺序根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。TreeMap不是线程安全的。
TreeMap包含几个重要的成员变量: root、size和comparator。
root是红黑数的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。红黑数排序时,根据Entry中的key进行排序;Entry中的key比较大小是根据比较器comparator来进行判断的。
size是红黑数中节点的个数。
comparator是键值排序的比较实现。
HashSet
HashSet是一个没有重复元素的集合,由HashMap实现的,不保证元素的顺序,而且HashSet允许使用 null 元素。HashSet不是线程安全的。
TreeSet
TreeSet是一个有序的集合,作用是提供有序的Set集合。继承于AbstractSet抽象类,实现了NavigableSet<E>(支持一系列的导航方法)、Cloneable和java.io.Serializable接口。TreeSet是基于TreeMap实现的。TreeSet中的元素支持2种排序方式:自然排序 或者 根据创建TreeSet 时提供的 Comparator 进行排序。这取决于使用的构造方法。TreeSet不是线程安全的。















 23万+
23万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









