







一、前言
当我们访问一个网站时,通常会在浏览器键入一个网址,如https://www.example.com,计算机在访问这个网站时,首先会将域名:www.example.com转换为相应的IP地址,再与之进行数据交互。而域名转换成IP地址的过程是怎么实现的呢?这就是DNS(Domain Name System,域名系统)协议的作用,DNS协议是互联网的核心协议之一,用于将域名转换为IP地址,以便计算机能够找到并访问网络上的资源。
二、基础简介
DNS协议是一种分布式数据库系统,它存储了域名和IP地址之间的映射关系,DNS协议文档详见RFC1035。
1. 域名结构
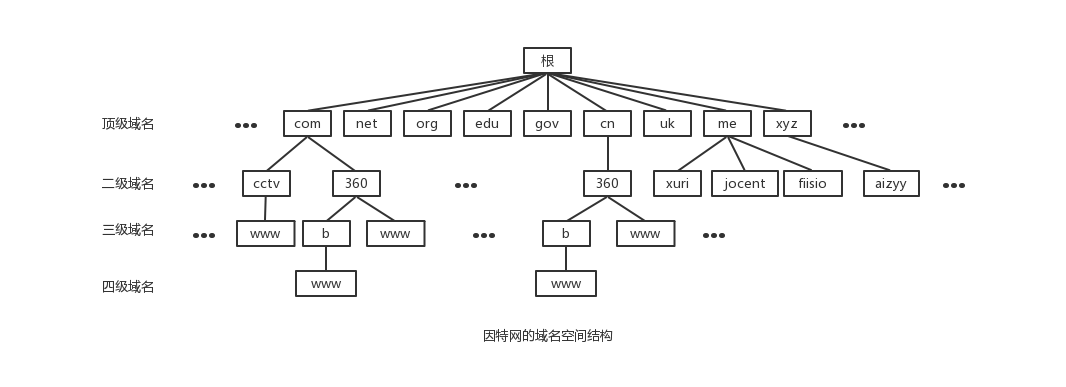
- 域名系统采用了层次结构的命名方法。
每一个域名都是一个标号序列(labels),用字母(A-Z,a-z,大小写等价)、数字(0-9)和连接符(-)组成,标号序列总长度不能超过255个字符,它由点号分割成一个个的标号(label),每个标号应该在63个字符之内,每个标号都可以看成一个层次的域名。级别最低的域名写在左边,级别最高的域名写在右边。
- 关于域名的层次结构,请看下面的示意图:
2.域名服务器
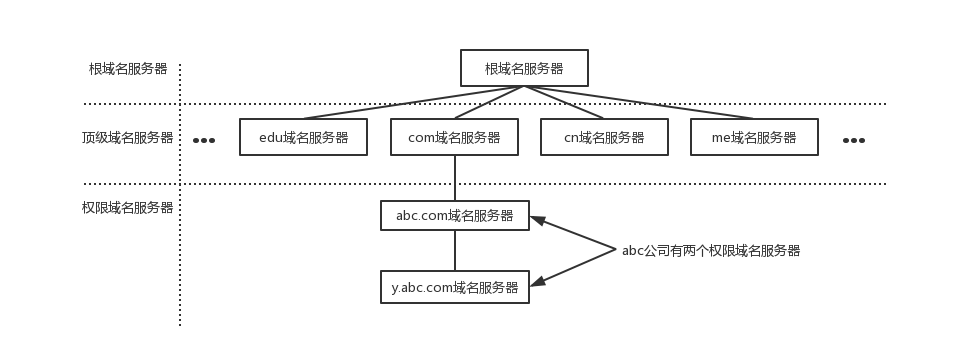
- 根域名服务器
最高层次的域名服务器,也是最重要的域名服务器,本地域名服务器如果解析不了域名就会向根域名服务器求助。全球共有13个不同IP地址的根域名服务器,它们的名称用一个英文字母命名,从a一直到m,这些服务器由各种组织控制,并由ICANN(互联网名称和数字地址分配公司)授权,由于每分钟都要解析域名数量多得令人难以置信,所以实际上每个根服务器都有镜像服务器,每个根服务器与它的镜像服务器共享同一个IP地址,
中国大陆地区内只有6组根服务器镜像(F,I(3台),J,L)。当你对某个根服务器发出请求时,请求会被路由到该根服务器离你最近的镜像服务器,所有的根域名服务器都知道所有的顶级域名服务器的域名和地址,如果向根服务器发出对example.com的请求,则根服务器是不能在它的记录文件中找到与example.com匹配的记录,但是它会找到com的顶级域名记录,并把负责com地址的顶级域名服务器的地址发回给请求者。
- 顶级域名服务器
负责管理在该顶级域名服务器下注册的二级域名,当根域名服务器告诉查询者顶级域名服务器地址时,查询者紧接着就会到顶级域名服务器进行查询。比如还是查询
example.com,根域名服务器已经告诉了查询者com顶级域名服务器的地址,com顶级域名服务器会找到example.com的域名服务器的记录,域名服务器检查其区域文件,并发现它有与example.com
相关联的区域文件。在此文件的内部,有该主机的记录。此记录说明此主机所在的 IP 地址,并向请求者返回最终记录。
- 权限域名服务器
负责一个区的域名解析工作;
- 本地域名服务器
当一个主机发出DNS查询请求的时候,这个查询请求首先就是发给本地域名服务器的。
3.域名组成
1)DNS 记录
- DNS记录是存储在DNS服务器上的数据单元,用于描述域名和IP地址之间的映射关系。常见的DNS记录包括A记录、AAAA记录、MX记录、NS记录等,下表为各记录的详细解释。
| 类型 | 说明 |
|---|---|
| A记录 | A记录是最常见和最常用的一种记录类型,用于指定主机名和IP(IPv4)地址之间的关系。通过添加A记录,网站管理者可以将域名与网站服务器地址进行绑定。 |
| AAAA记录 | 与A记录相对的是,AAAA记录是用于将域名解析到IPv6地址的一种DNS记录类型。国内很多解析服务器不支持AAAA记录的设置,如果想进行AAAA记录解析,就需要将域名的NS记录指向一些专业的域名解析厂商。 |
| CNAME记录 | CNAME记录也是比较常用的一种记录类型,它是主机名到主机名的映射。如果需要将域名指向另一个域名,而不是一个IP地址,那么就需要添加一条CNAME记录。在CDN、企业邮箱、全局流量管理等业务场景下,经常会使用到CNAME记录。 |
| NS记录 | NS记录用于将子域名交给其他DNS服务商解析时使用,从某种意义上来讲NS记录相当于设置子域名解析服务器的A记录,用于在解析请求时确定该服务器的IP地址。大多数域名注册商默认使用自己的NS记录来解析用户的域名,但用户也可以设置NS记录指向更专业安全的域名解析厂商。 |
| MX记录 | MX记录是邮件交换记录,主要用于邮箱解析,在发送邮件时根据收件人的地址后缀进行邮件服务器的定位。MX记录的权重对邮件服务非常重要,发送邮件时,会先对域名进行解析,查找MX记录,按照权重从小到大的顺序联通服务器进行邮件发送。 |
| TXT记录 | TXT记录,一般用于某个主机名的标识和说明,通过设置TXT记录可以使别人更方便地联系到你。此外TXT记录还常用于做SPF反垃圾邮件和SSL证书的DNS验证等。 |
| PTR记录 | PTR记录可以简单理解为A记录的反向记录,用于将一个IP地址指向对应的主机名,实现通过IP地址访问域名。 |
| SOA记录 | SOA记录又叫起始授权机构记录,NS标记多台解析服务器,SOA记录用于表明在众多NS记录中哪一台才是主服务器。当要查询的域名在所有递归解析服务器中没有域名解析的缓存时,就会回源来请求此域名的SOA记录,获取提供权威解析服务的地址。 |
| SRV记录 | SRV记录即服务定位(SRV)资源记录,用于定义提供特定服务的服务器的位置,如主机(hostname),端口(port number)等。 |
| URL转发 | URL转发,是将当前访问的域名指向另一个网络地址,可以分为显性转发和隐性转发两种。显性URL:将域名指向另一个网络地址时,访问域名自动跳转至目标网址,地址栏显示为目标网站地址;隐性URL:访问域名跳转到目标网站,但地址栏显示为原网站地址。 |
2)DNS 查询
- DNS查询是客户端向DNS服务器发出的请求,用于解析域名对应的IP地址,查询请求通常包含要查询的域名和查询类型(如A记录或AAAA记录),查询类型决定了返回的响应类型。
3)DNS 响应
- DNS响应是DNS服务器对查询请求的回应,响应中包含了查询结果以及查询的响应状态码,如果查询成功,响应状态码为“成功”,并且包含与查询请求中指定的查询类型对应的IP地址或权威DNS服务器的IP地址;如果查询失败,响应状态码为“失败”或“无法解析”。
4)DNS 缓存
- DNS缓存是DNS服务器上存储的已解析过的域名和IP地址映射关系。通过缓存可以减少重复查询的开销,提高DNS解析的效率。当客户端发出一个查询请求时,DNS服务器首先会检查本地缓存中是否已存在该域名的解析结果,如果存在则直接返回缓存结果,否则进行递归查询。
4.工作流程
- 客户端发出DNS查询请求,请求中包含要解析的域名和查询类型; DNS服务器在本地查找该域名的相关记录,如果找到则直接返回结果;
- 如果本地没有找到相关记录,则向根DNS服务器进行递归查询; 根DNS服务器返回给权威DNS服务器的IP地址;
- DNS服务器向权威DNS服务器发出递归查询请求; 权威DNS服务器返回给DNS服务器该域名的IP地址;
- DNS服务器将解析得到的IP地址返回给客户端; 客户端收到IP地址后,使用该IP地址进行资源访问。
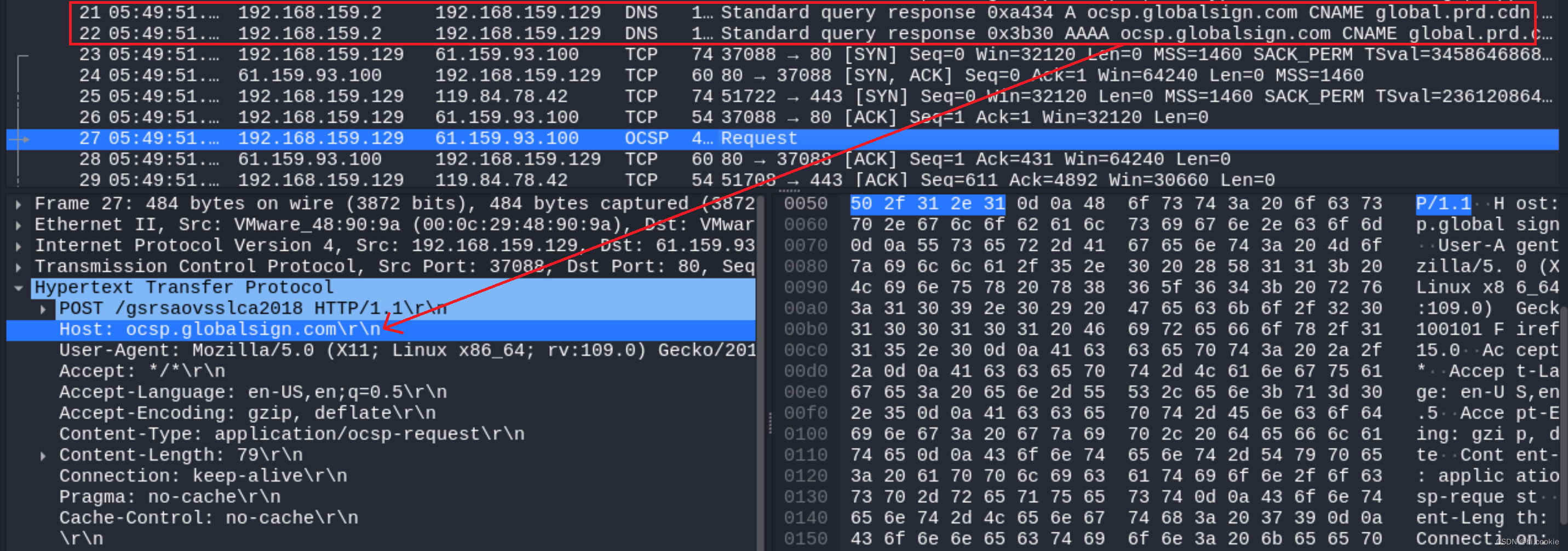
- 下图简单展示了请求访问网站资源的过程,即是先请求DNS域名,获得解析地址后再与之进行数据交互。
四、报文格式

1.头部
- 会话标识(
2字节)
是DNS报文的ID标识,对于请求报文和其对应的应答报文,这个字段是相同的,通过它可以区分DNS应答报文是哪个请求的响应
- 标志(
2字节)

| 字段 | 含义 |
|---|---|
| QR(1bit) | 查询/响应标志,0为查询,1为响应 |
| opcode(4bit) | 0表示标准查询,1表示反向查询,2表示服务器状态请求 |
| AA(1bit) | 表示授权回答 |
| TC(1bit) | 表示可截断的 |
| RD(1bit) | 表示期望递归 |
| RA(1bit) | 表示可用递归 |
| rcode(4bit) | 表示返回码,0表示没有差错,3表示名字差错,2表示服务器错误(Server Failure) |
- 数量字段(
8字节)
Questions、Answer RRs、Authority RRs、Additional RRs各自表示后面的四个区域的数目。Questions表示查询问题区域节的数量,Answers表示回答区域的数量,Authoritative namesversers表示授权区域的数量,Additional recoreds表示附加区域的数量。
2. 正文
1) Queries区域

-
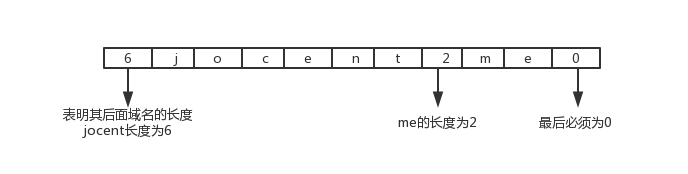
查询名:长度不固定,且不使用填充字节,一般该字段表示的就是需要查询的域名(如果是反向查询,则为IP,反向查询即由IP地址反查域名),一般的格式如下图所示。
-
查询类型:
| 类型 | 助记符 | 说明 |
|---|---|---|
| 1 | A | 由域名获得IPv4地址 |
| 2 | NS | 查询域名服务器 |
| 5 | CNAME | 查询规范名称 |
| 6 | SOA | 开始授权 |
| 11 | WKS | 熟知服务 |
| 12 | PTR | 把IP地址转换成域名 |
| 13 | HINFO | 主机信息 |
| 15 | MX | 邮件交换 |
| 28 | AAAA | 由域名获得IPv6地址 |
| 252 | AXFR | 传送整个区的请求 |
| 255 | ANY | 对所有记录的请求 |
- 查询类:通常为1,表明是Internet数据
2)资源记录(RR)区域,包括回答区域,授权区域和附加区域

回答区域,授权区域和附加区域的格式基本一致:
- 域名(2字节或不定长)
它的格式和Queries区域的查询名字字段是一样的。有一点不同就是,当报文中域名重复出现的时候,该字段使用2个字节的偏移指针来表示。比如,在资源记录中,域名通常是查询问题部分的域名的重复,因此用2字节的指针来表示,具体格式是:最前面的两个高位是11,用于识别指针;其余的14位从DNS报文的开始处计数(从0开始),指出该报文中的相应字节数。
一个典型的例子:C00C(1100000000001100,12正好是头部的长度,其正好指向Queries区域的查询名字字段
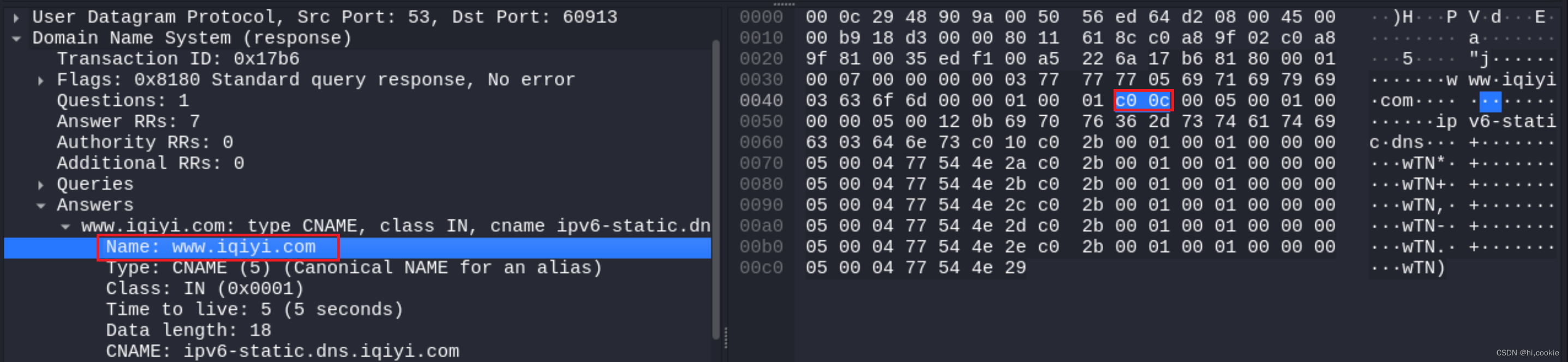
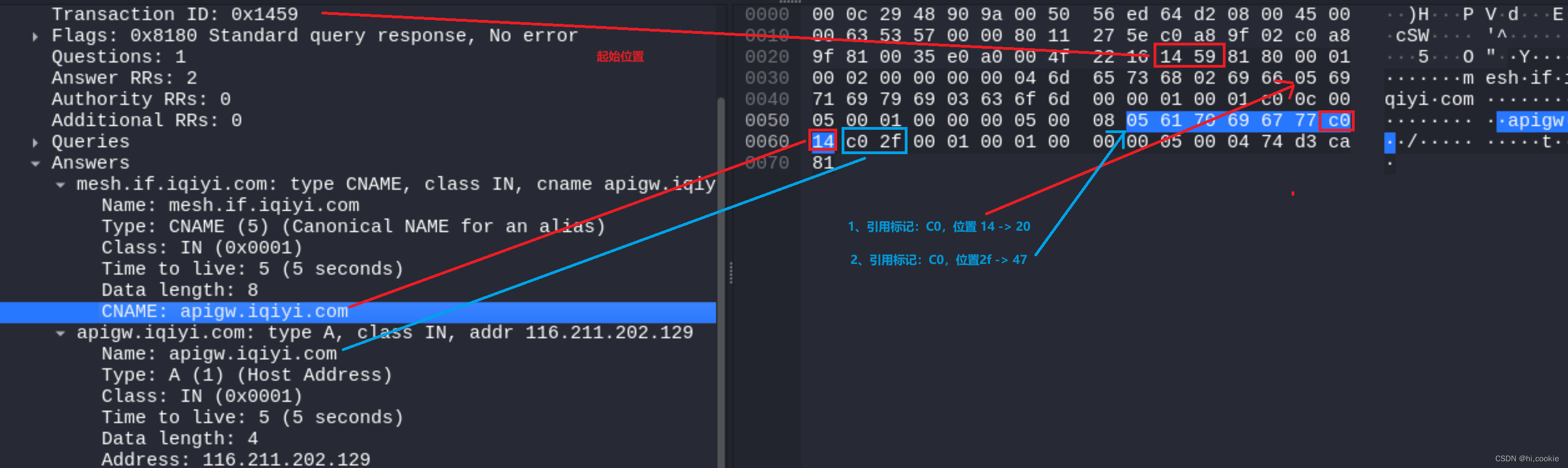
- 查询类型:表明资源纪录的类型,见1.2节的查询类型表格所示 ;
- 查询类:对于Internet信息,总是IN;
- 生存时间(TTL):以秒为单位,表示的是资源记录的生命周期,一般用于当地址解析程序取出资源记录后决定保存及使用缓存数据的时间,它同时也可以表明该资源记录的稳定程度,极为稳定的信息会被分配一个很大的值(比如86400,这是一天的秒数)。
- 资源数据:该字段是一个可变长字段,表示按照查询段的要求返回的相关资源记录的数据。可以是Address(表明查询报文想要的回应是一个IP地址)或者CNAME(表明查询报文想要的回应是一个规范主机名)等。
五、解析思路
1. 初始化libpcap
- 寻找并打开合适的网络接口(如
pcap_lookupdev()和pcap_open_live())。 - 设置过滤规则以便只捕获DNS相关的流量,通常会使用BPF (Berkeley Packet Filter)语法编写过滤器,比如
udp port 53,调用pcap_compile()、pcap_setfilter()应用规则。
char errbuf[PCAP_ERRBUF_SIZE];
pcap_t *handle;
struct bpf_program fp;
char filter_exp[] = "udp port 53"; // DNS traffic filter
if (argc != 2) {
printf("Usage: %s <interface>\n", argv[0]);
exit(EXIT_FAILURE);
}
handle = pcap_open_live(argv[1], 65535, 1, 1000, errbuf);
if (handle == NULL) {
fprintf(stderr, "Error opening device: %s\n", errbuf);
exit(EXIT_FAILURE);
}
if (pcap_compile(handle, &fp, filter_exp, 0, PCAP_NETMASK_UNKNOWN) == -1) {
fprintf(stderr, "Error compiling filter: %s\n", pcap_geterr(handle));
exit(EXIT_FAILURE);
}
if (pcap_setfilter(handle, &fp) == -1) {
fprintf(stderr, "Error setting filter: %s\n", pcap_geterr(handle));
exit(EXIT_FAILURE);
}
2. 捕获网络数据包
- 使用
pcap_loop()或pcap_dispatch()等函数开始捕获网络数据包。
if (pcap_loop(handle, -1, process_packet, NULL) == PCAP_ERROR) {
fprintf(stderr, "[*]Pcap_loop failed: %s\n", pcap_geterr(handle));
return -1;
}
3. 处理每个捕获的数据包
- 根据数据包头部信息(如以太网头部、IP头部、UDP头部),来确定是否是UDP协议且目的地或来源端口为53(DNS使用的端口号),进而再对DNS相关数据按照报文格式来解析,这里自定义函数dns_query_parser()来处理相关数据。
void process_packet(u_char* arg, const struct pcap_pkthdr *packet_header, const u_char *packet_data) {
struct ip* piphdr;
struct udphdr* pudphdr;
unsigned int payload_len;
// 跳过异常包
if (packet_header->caplen < packet_header->len) return;
// IP
packet_data += sizeof(struct ether_header);
// 解析IP层
piphdr = (struct ip*)packet_data;
// 获取IP地址
strcpy(sip, inet_ntoa(piphdr->ip_src));
strcpy(dip, inet_ntoa(piphdr->ip_dst));
// UDP
packet_data += piphdr->ip_hl * 4;
switch(piphdr->ip_p){
case IPPROTO_UDP:
pudphdr = (struct udphdr*)packet_data;
sport = ntohs(pudphdr->source);
dport = ntohs(pudphdr->dest);
payload_len = ntohs(piphdr->ip_len) - piphdr->ip_hl * 4 - sizeof(struct udphdr);
// DNS
packet_data += sizeof(struct udphdr);
printf("[*]Protocol UDP %s:%d => %s:%d payload_len:%d pkt_data:%s\n", sip, sport, dip, dport, payload_len, (u_char *)packet_data);
break;
default:
payload_len = 0;
packet_data = NULL;
break;
}
if (!payload_len || !packet_data ) return;
printf("[-]start dns query parser\n");
dns_query_parser(ctime(&packet_header->ts.tv_sec), packet_data, payload_len);
signal(SIGINT, stop);
signal(SIGTERM, stop);
signal(SIGQUIT, stop);
}
4. 解析DNS报文
- 把数据包内容转换为DNS报文格式,并根据DNS报文结构解析其中的内容。
- DNS报文结构通常包含一个12字节的固定头部,然后是多个查询或响应记录。根据DNS报文的类型(查询或响应)、opcode、qdcount(查询计数)、ancount(答案计数)等字段来决定如何解析剩余的报文内容。
- 下方,定义struct dnshdr结构体来处理头部数据(12个字节),再对查询数据进行解析,首先定义一个结构体(struct query_zone)来用于存相应结果,最后调用函数query_zone_parser()来处理。
/**
* DNS header
*/
struct dnshdr {
uint16_t id;
uint16_t flags;
uint16_t qdcount;
uint16_t ancount;
uint16_t nscount;
uint16_t arcount;
} __attribute__((packed));
struct query_zone{
u_char *name;
uint16_t qtype;
uint16_t class;
};
int dns_query_parser(u_char* timestamp, const u_char* payload_data, unsigned int payload_len) {
struct dnshdr* pdhdr;
int offset = sizeof(struct dnshdr);
// 解析DNS头部12个字节
pdhdr = (struct dnshdr*)payload_data;
// 指向后续域名请求数据
payload_data += offset;
payload_len -= offset;
dbg("[-]Header pdhdr->ancount:%d pdhdr->qdcount:%d offset:%d trans id:%p\n", ntohs(pdhdr->qdcount), ntohs(pdhdr->ancount), offset, pdhdr->id);
struct query_zone* qd = (struct query_zone*)malloc(sizeof(struct query_zone));
memset(qd, 0, sizeof(struct query_zone));
query_zone_parser(payload_data, payload_len, qd);
printf("%s %s:%d -> %s:%d [ %s ] %s %s\n", timestamp, sip, sport, dip, dport, "query", dns_types[qd->qtype], qd->name);
}
5. 提取DNS信息
- 遍历查询记录(QNAME、QTYPE、QCLASS)和响应资源记录(RRs,包括NAME、TYPE、CLASS、TTL和RDATA)来提取域名、类型(A记录、MX记录等)、IP地址或其他相关信息。
- 下方是对查询记录解析的示例代码:
int query_zone_parser(const u_char* pkt_data, unsigned int data_len, struct query_zone* qz) {
const u_char* p = pkt_data;
const u_char* end = pkt_data + data_len;
dbg("query_zone_parser data_len:%d\n", data_len);
u_char *name = (u_char*)malloc(sizeof(u_char) * 1024) ;
memset(name, 0, 1024);
u_char *dst = name;
for(; *p; ) {
memcpy(dst, p + 1, *p);
dbg("len:%d name:%s \n", *p, dst);
dst += *p;
p += *p + 1;
dbg("p:%p end:%p\n", p, end);
if (p > end )
goto err;
*dst = '.';
dst++;
}
*(--dst) = '\0';
uint16_t qtype = ntohs(*( (uint16_t *) ++p) );
if (qtype == 28)
qtype = 17;
else if(qtype > 16)
qtype = 0;
uint16_t class = ntohs(*( (uint16_t *) (p + 2)) );
dbg("name: %s qtype:%d class:%d \n", name, qtype, class);
qz->name = name;
qz->qtype = qtype;
qz->class = class;
return 0;
err:
return 1;
}
实现的效果如下,解析出了查询与响应的相关数据:
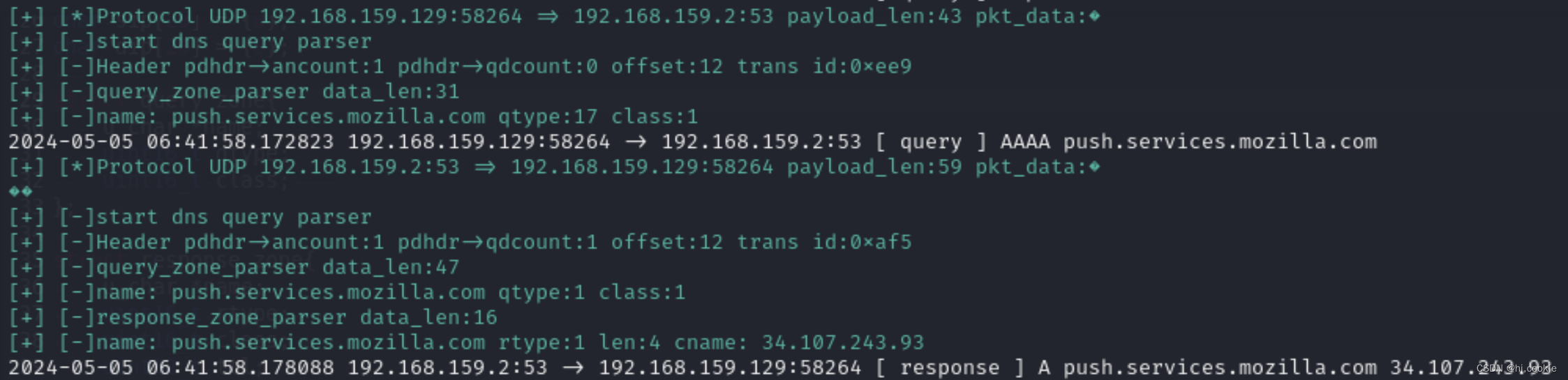















 917
917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









