







七、正则化(Regularization)
7.1 过拟合的问题
参考视频 : 7 - 1 - The Problem of Overfitting (10 min).mkv
我们目前学习了线性回归和逻辑回归算法,它们能有效地解决问题,但将其应用到特定的机器学习应用是,会遇到过拟合(over-fitting)的问题,导致模型的预测效果变差。
用线性回归中的预测房价举例:
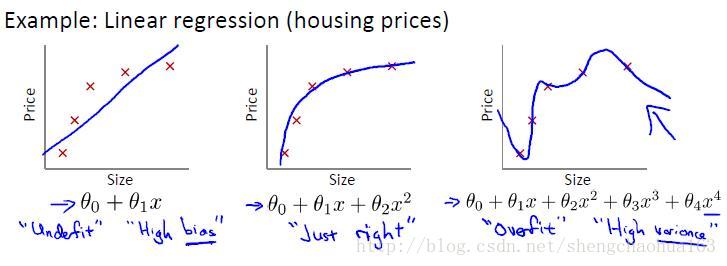
第一个模型是一个线性模型,属于欠拟合;第三个是一个四次方的模型,过分地拟合了原始数据,丢失了算法的本质:预测新数据,它预测新数据的表现一定会很差!
分类问题举例:
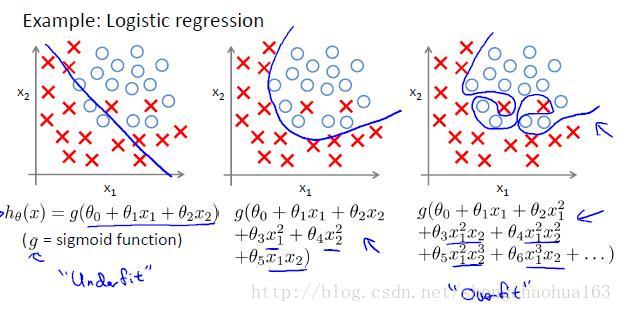
以多项式理解,x的次数越高,拟合的越好,但相应的预测新数据的能力就变得很差!
发现了过拟合问题,我们应该如何处理?
1. 丢弃一些不能帮助我们正确预测的特征。可以手工选择保留那些特征,或使用一些模型选择的算法(PCA等)来帮助清洗数据
2. 正则化。保留所有的特征,但是减小参数的大小(magnitude)
7.2 代价函数
参考视频 : 7 - 2 - Cost Function (10 min).mkv
在回归问题中假设模型是: hθ(x)=θ0+θ1x1+θ2x22+θ3x33+θ4x44 h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 2 + θ 3 x 3 3 + θ 4 x 4 4 ,我们可以看出来:正是那些高次项导致了过拟合的产生。所以如果我们能让这些高次项的系数接近于0的话,我们就能很好的拟合了。
如何减小高次项的系数 θ θ 值呢?这就是正则化的基本方法。如果要减小 θ3,θ4 θ 3 , θ 4 ,我们需要修改代价函数,为 θ3,θ4 θ 3 , θ 4 设置惩罚项。修改后的代价函数如下:
假如我们有非常多的特征,而且不知道哪些特征需要进行惩罚,我们将对所有的特征进行惩罚,一般化的代价函数如下:

如果选择的正则化参数过大,则会把所有的参数都最小化了,导致模型变成 hθ(x)=θ0 h θ ( x ) = θ 0 ,也就是上图中的红色直线,是欠拟合。
所以对于正则化,我们要取一个合理的正则化参数值,这样才能取得比较好的效果。
7.3 正则化线性回归
之前介绍过两种求解线性回归的算法:一种基于梯度下降,一种基于正规方程。
(一)基于梯度下降求解正则化线性回归:
梯度下降算法为:
求偏导数,分为j=0无惩罚和j≠0有惩罚:
所以正则化线性回归的梯度下降算法为:
Repeat{
R
e
p
e
a
t
{
(二)基于正规方程求解正则化线性回归:
7.4 正规化逻辑回归
参考视频:7 - 4 - Regularized Logistic Regression (9 min).mkv
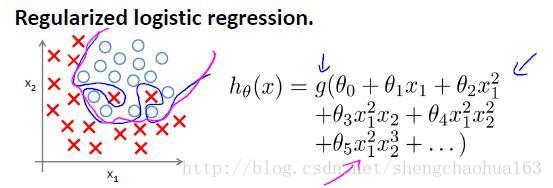
逻辑回归的代价函数:
正则化后的代价函数:
所以正则化逻辑回归的梯度下降算法为:
Repeat{
R
e
p
e
a
t
{
注意:虽然正则化逻辑回归的梯度下降的表达式和正则化线性回归的看起来一样,但是逻辑回归的 hθ(x)=g(θTx) h θ ( x ) = g ( θ T x ) 与线性回归 hθ=θTx h θ = θ T x 不同。记住 θ0 θ 0 不参与正则化。
目前大家对机器学习算法可能还只是略懂,不过一旦你精通了线性回归、高级优化算法和正则化技术,就已经说明你对机器学习理解已经非常深入了。















 610
610

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









