







 本文介绍了如何使用HttpClient 4.x库处理带有验证码的网站登录问题。首先阐述了登录流程,包括浏览器如何处理cookie和验证码。接着,通过实例展示了获取验证码图片并将其保存到本地,再人工输入验证码进行登录的过程。还提到了在POST请求中构造所需参数来模拟登录,最终成功登录并能抓取其他网页信息。建议将HTTPClient操作封装为独立类以避免二次请求时的错误。
本文介绍了如何使用HttpClient 4.x库处理带有验证码的网站登录问题。首先阐述了登录流程,包括浏览器如何处理cookie和验证码。接着,通过实例展示了获取验证码图片并将其保存到本地,再人工输入验证码进行登录的过程。还提到了在POST请求中构造所需参数来模拟登录,最终成功登录并能抓取其他网页信息。建议将HTTPClient操作封装为独立类以避免二次请求时的错误。
对于爬虫来说,验证码通常是实现过程中的一个巨大的障碍,因为验证码的多样性,有的甚至变态至极,所有一般来说使用代码自动识别验证码是非常困难的,本问的内容就是讲如何将验证码保存到本地,然后通过人工输入验证码实现登陆,从而抓取网页信息。
首先说说整个登陆的流程,当我们打开一个网站的时候,浏览器就会记录该网站的cookie,用于识别信息,同时服务器会向浏览器发送一张验证码的图片,并与该cookie的信息是相关联的,并以此识别用户,然后post提交数据的时候一同提交就实现认证登陆了。
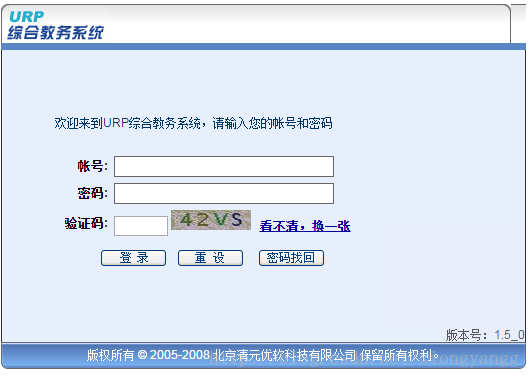
以下登陆我们学校的教务处作为例子,这是我们教务处的登陆界面。
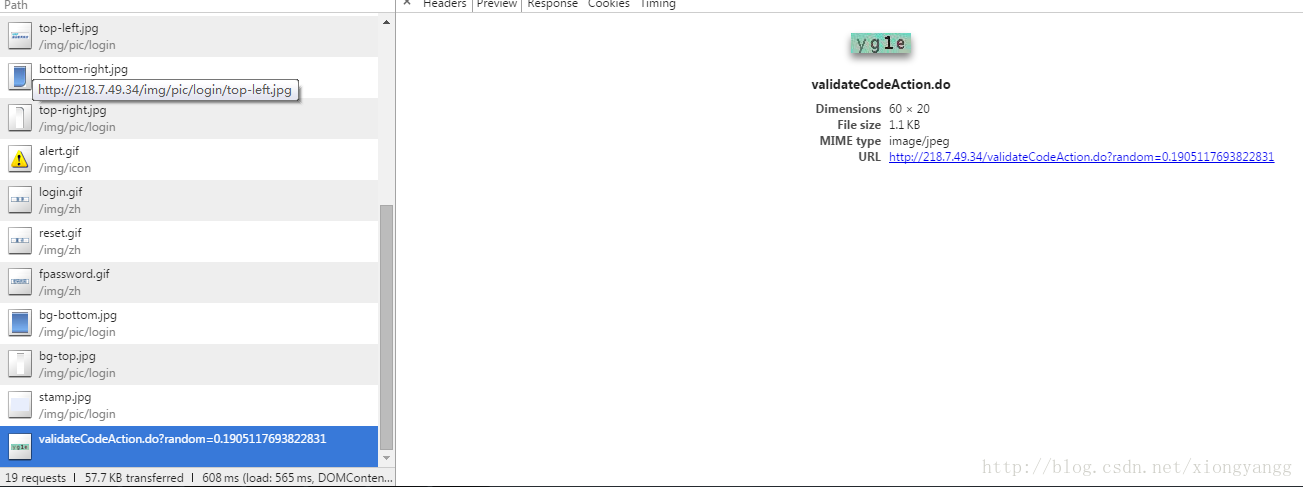
右键打开chrome的审查元素,跟踪到验证码的链接。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6837
6837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









