







 本文探讨了并查集算法的效率问题及其两种优化方法:Union by Rank(根据秩合并)和Path Compression(路径压缩)。通过这些优化,可以将最坏情况下的时间复杂度降低到O(LogN)。文中还提供了不同语言的代码实现示例,供读者下载学习。
本文探讨了并查集算法的效率问题及其两种优化方法:Union by Rank(根据秩合并)和Path Compression(路径压缩)。通过这些优化,可以将最坏情况下的时间复杂度降低到O(LogN)。文中还提供了不同语言的代码实现示例,供读者下载学习。
在上一篇文章中,我们介绍了Union-Find算法,通过union()和find()操作来检测图中的循环。
然而那些操作虽然简单但却并不高效,最坏情况的时间复杂度是线性的即O(n)。这是因为,为了表示子集而创建的树可能是单向倾斜的,并变得像一个链表。
最坏情况的示例
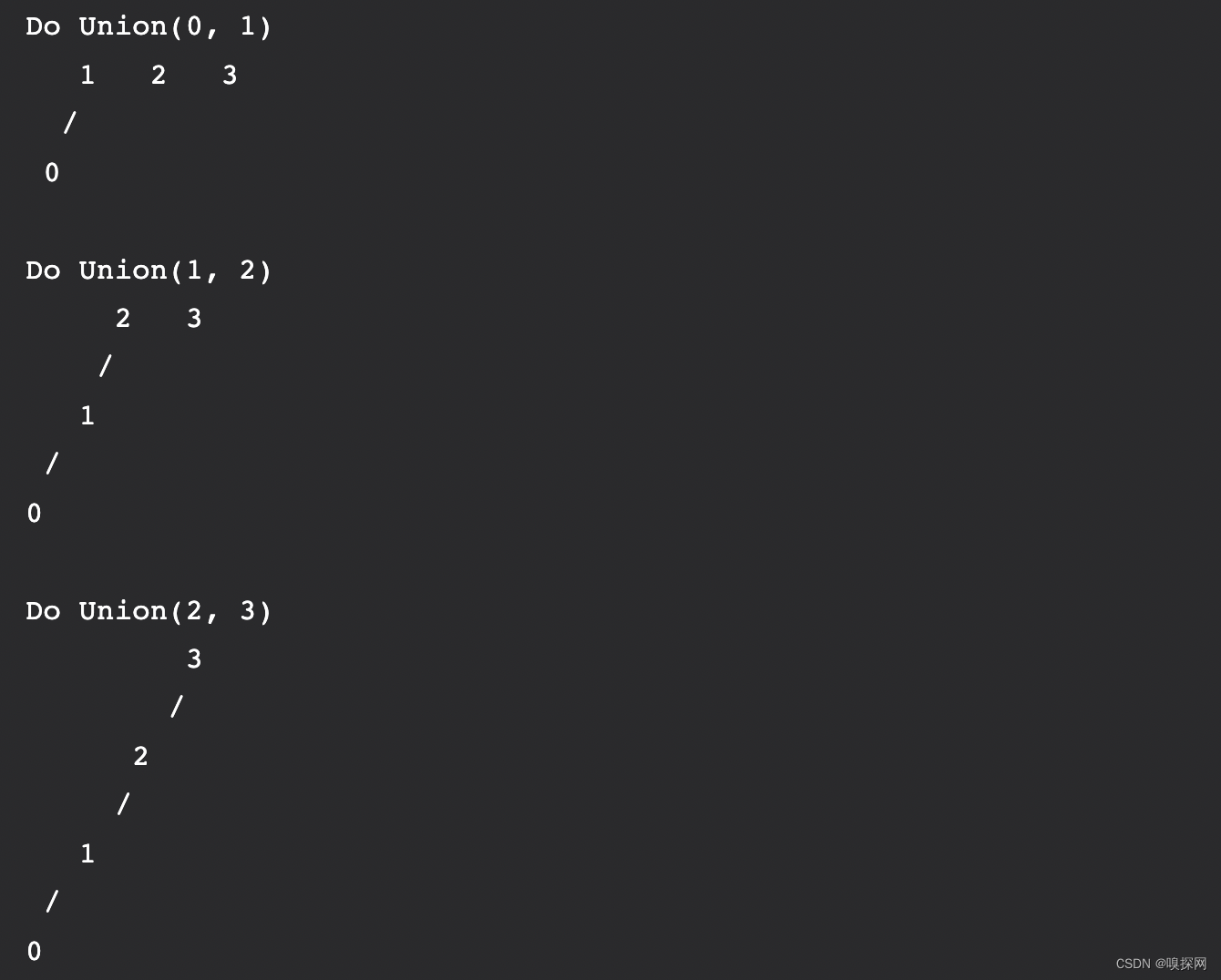
假设有 4 个元素 0、1、2、3
最初,所有元素都是可以认为是单元素的子集。
随着我们不断进行Union()操作,元素之间的关系会变得像一个链表
上述情况类似于二叉查找树的极端情况,两者的时间复杂度都是线性的。二叉树可以通过旋转来维持平衡以保证时间复杂度维持在O(lonN),相应的我们也可以采用一些手段来优化Union()和Find()两个操作 。
第一个优化方法可以概述为,总是在更深的树的根下附加更小的深度树(rank值小的树连接到rank值大的树上)。这种技术称为union by rank。优先使用术语rank而不是 height,因为如果使用路径压缩技术(Path compression我们
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









