






作者 | 智商掉了一地、ZenMoore
在互联网的浩瀚世界中,存在着无数复杂而扑朔迷离的任务等待我们去解决。如果要设计一个解决很多问题的通用智能体(AI agent),无论是关于购物、旅行、学习还是娱乐,要想在这个纷繁复杂的网络中驾驭大部分事物,我们需要一位真正的通才。而幸运的是,Mind2Web 数据集也许有机会成为我们探索互联网的指南,帮助我们开发和评估能够根据语言指令在任何网站上完成复杂任务的通用智能体。Mind2Web 包含来自 31 个领域、137 个网站的 2350 个任务,它具有以下特点:
- 反映了 Web 上多样化和与生活实际相关的使用案例。
- 提供具有真实世界网站的具有挑战性但又现实的环境。
- 测试在不同任务和环境中的泛化能力。
现有的 Web 智能体数据集要么使用模拟网站,要么只涵盖了有限的网站和任务,因此不适用于通用的 Web 智能体。和之前的数据集相比,Mind2Web 在以下几个方面独树一帜:
- 覆盖更多领域、网站和任务:包含来自31个不同领域的任务,覆盖了更广泛的主题和领域,使得智能体能够处理更多种类的任务。
- 真实世界网站:提供了真实世界的网站作为任务环境,这些网站反映了实际的在线体验,使得智能体可以在真实的网络环境中进行训练和测试。
- 广泛的用户互动模式:使得智能体能够适应不同的用户行为和操作方式,从而更好地应对各种任务要求。
咱们一起来看看这个数据集及相关任务的介绍吧~
论文题目:
Mind2Web: Towards a Generalist Agent for the Web
论文链接:
https://arxiv.org/abs/2306.06070
代码地址:
https://github.com/OSU-NLP-Group/Mind2Web
Demo 地址:
https://osu-nlp-group.github.io/Mind2Web/
大模型研究测试传送门
GPT-4能力研究传送门(遇浏览器警告点高级/继续访问即可):
https://gpt4test.com
论文速览
任务与领域
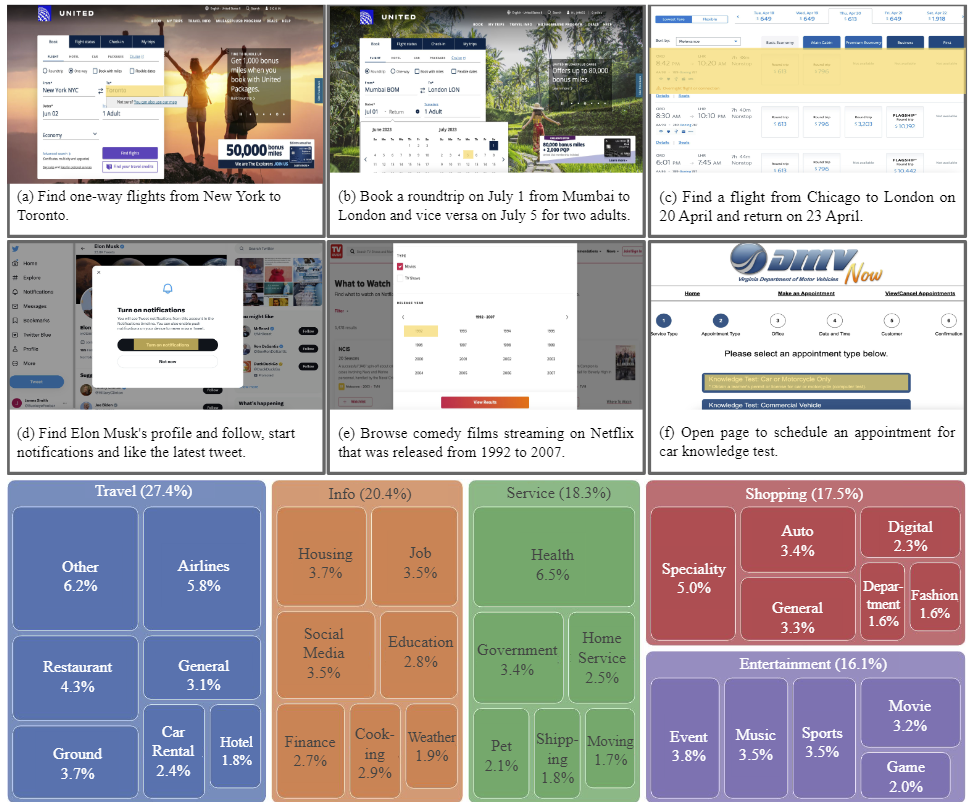
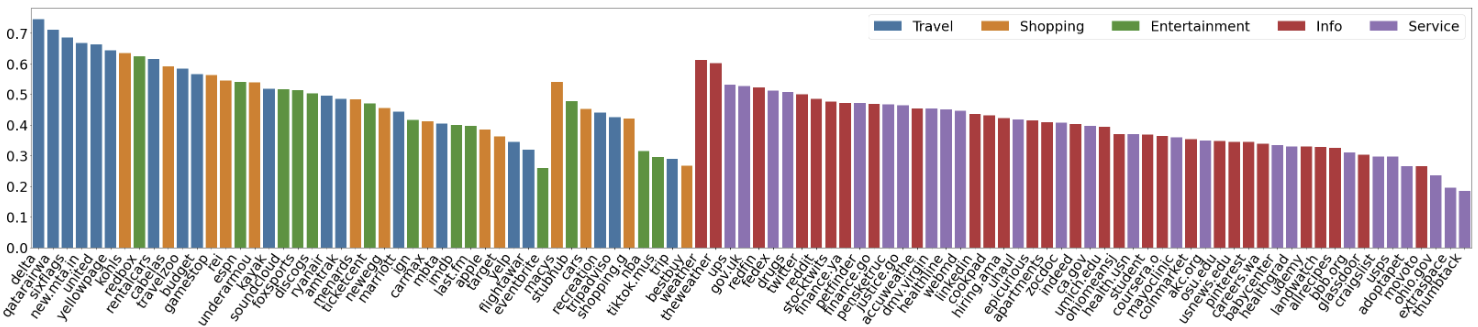
作者使用 SimilarWeb 的排名作为参考来收集这些网站,平衡了任务和网站的分布,以更好地测试不同级别的泛化能力,具体任务如下所示:
- 跨任务泛化:在相同环境中跨任务的泛化,例如从图 (a) 到 (c )。
- 跨网站泛化:在相同领域下跨网站的泛化,例如从图 (a) 到 (d)。
- 跨领域泛化:在不同任务和环境中的泛化,例如从图 (e) 到 (i)。
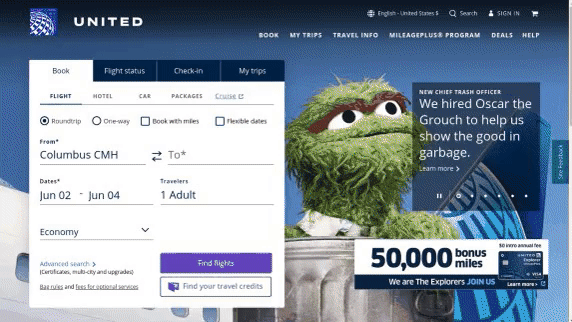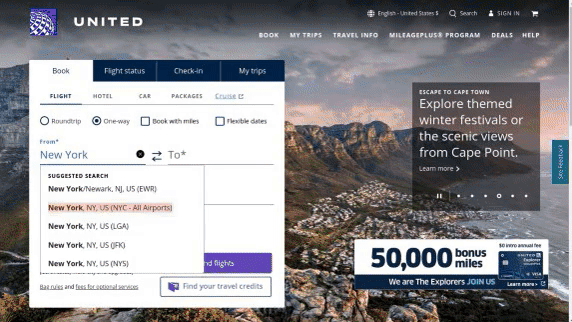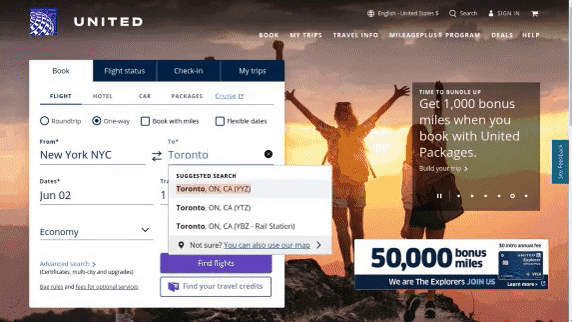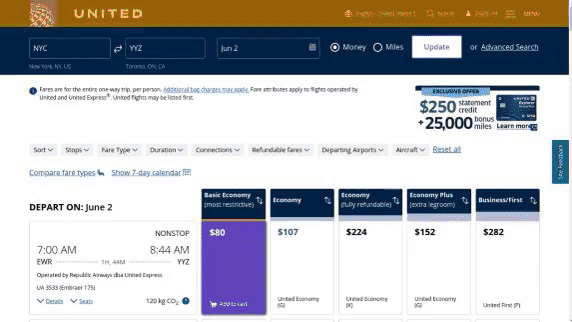
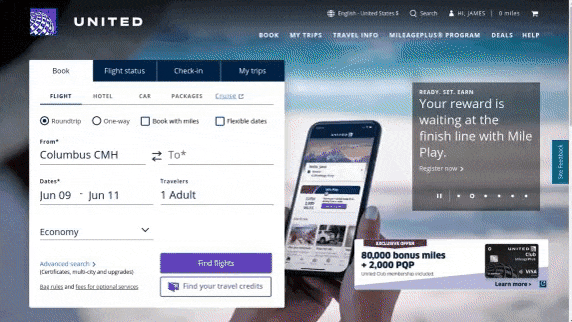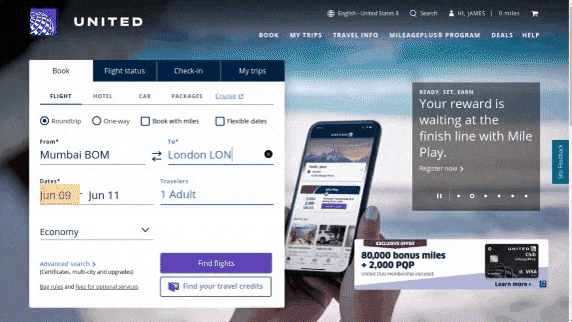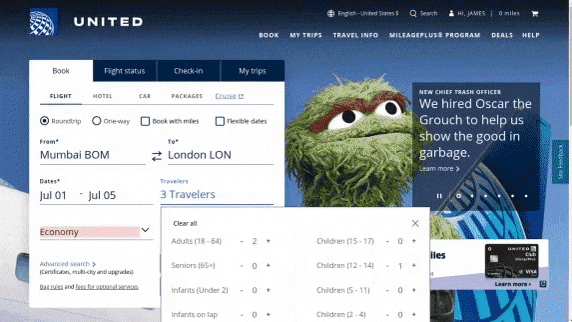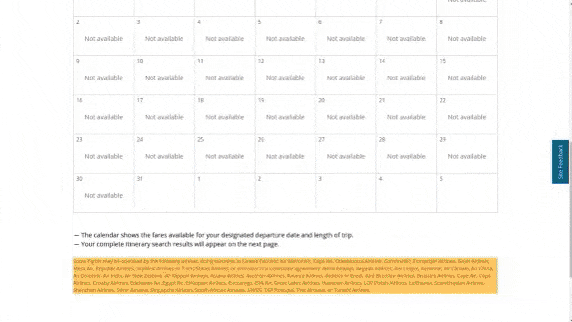
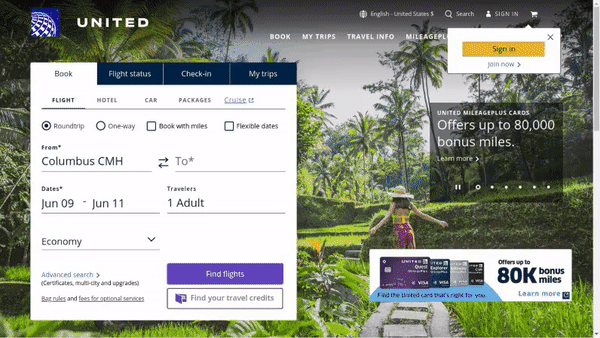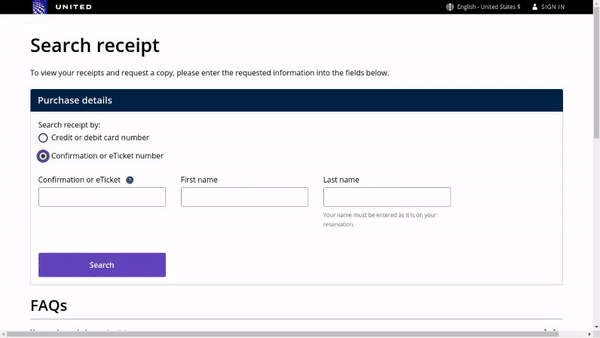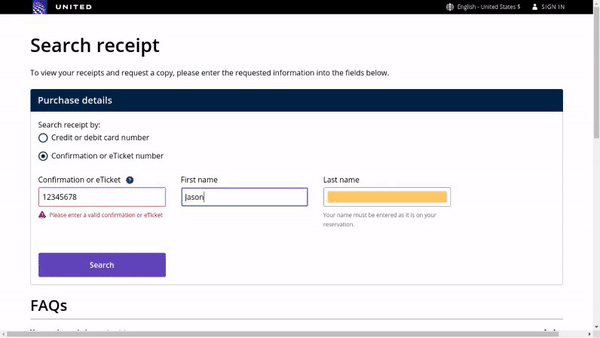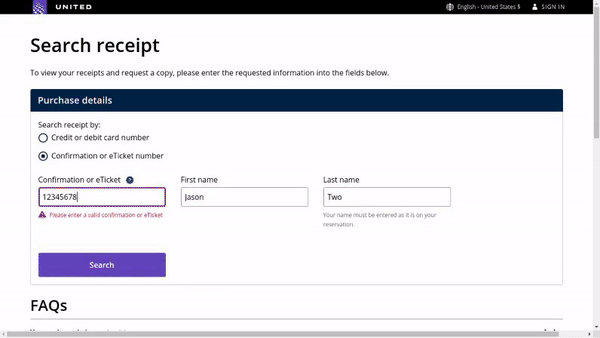
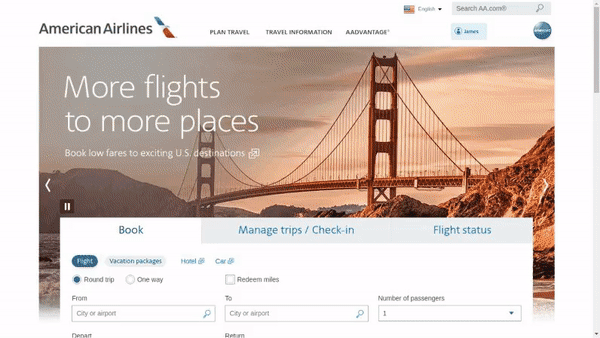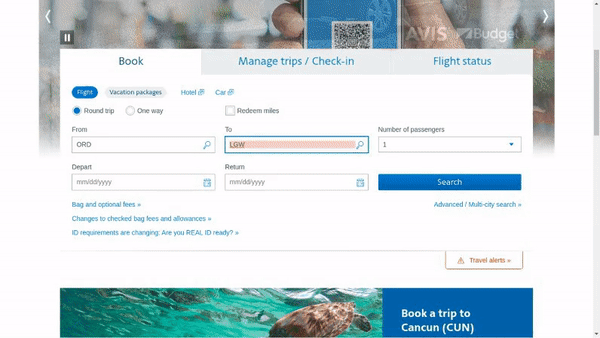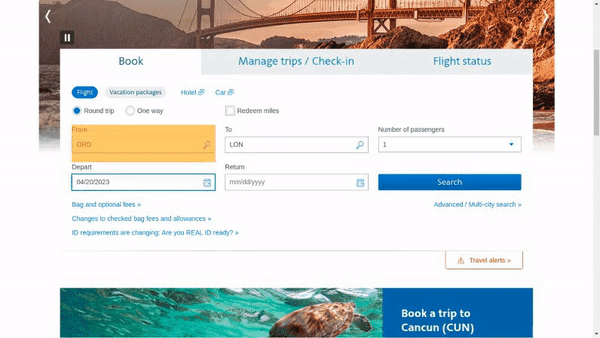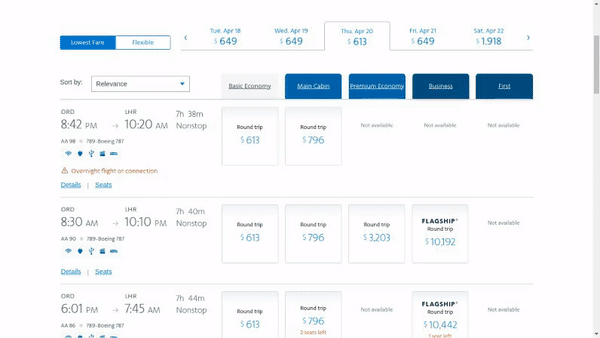
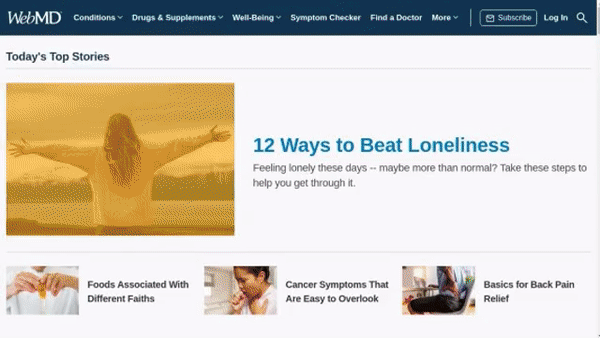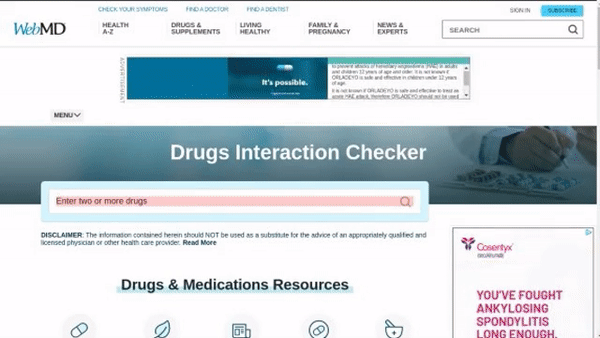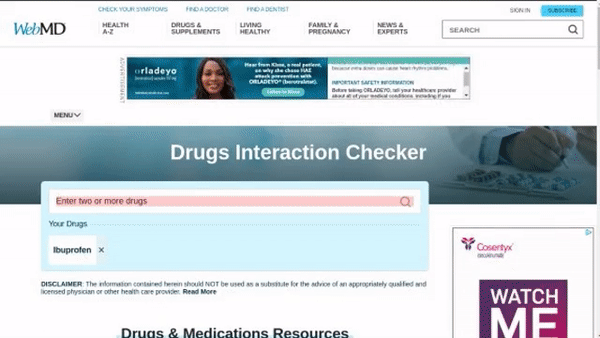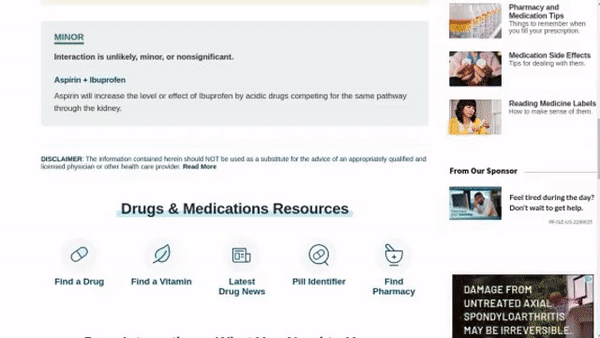

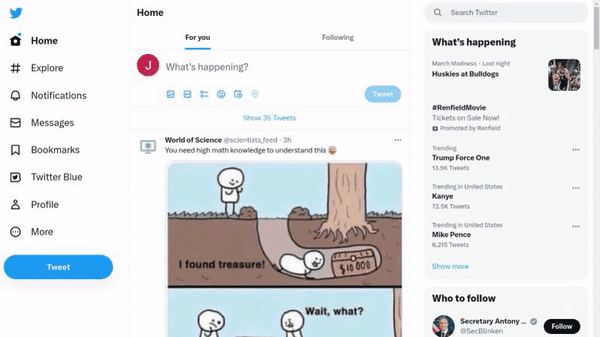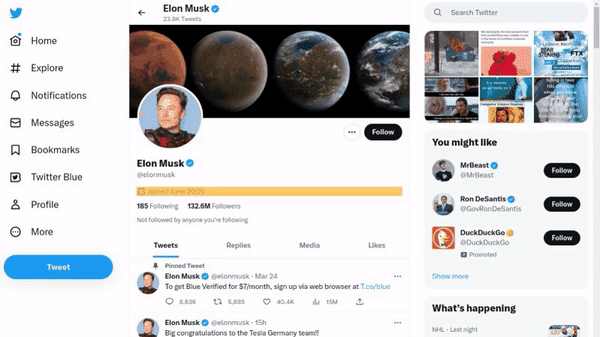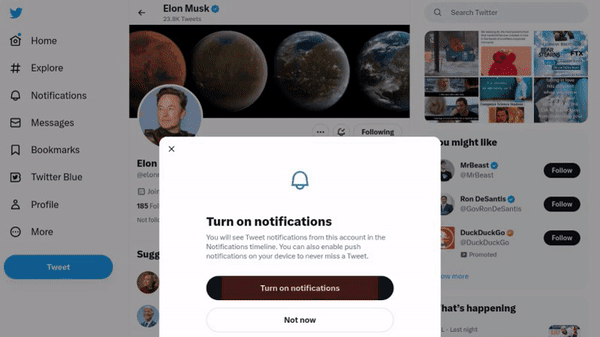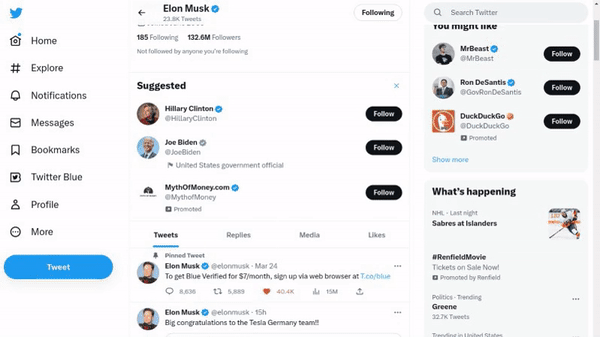
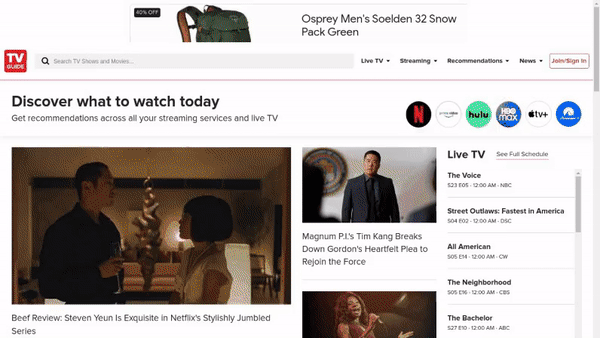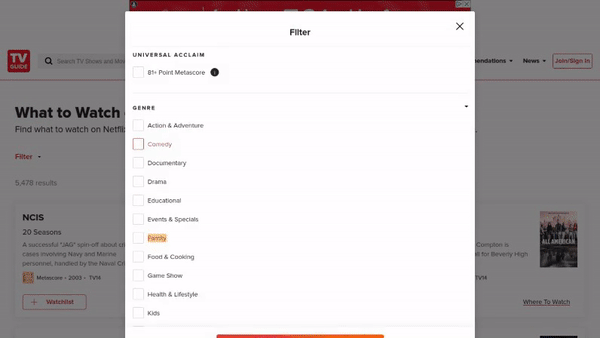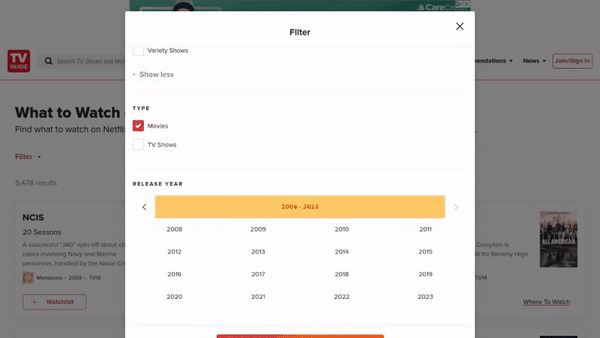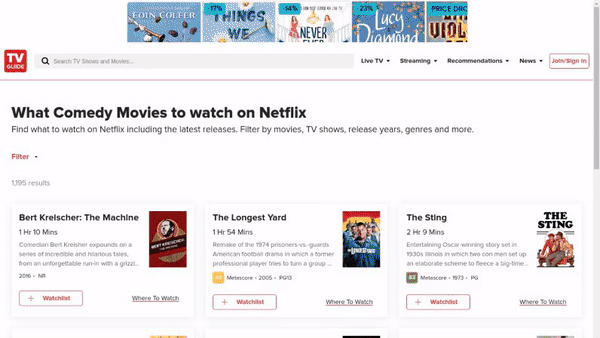
对于上述的每个任务,作者提供了以下组件信息:
- 任务描述:用自然语言句子描述任务。
- 操作序列:描述完成任务所需执行的操作序列。
- 每个操作是一个(操作类型,目标元素)对,其中目标元素是用户选择与之交互的网页元素,而操作则是要在该元素上执行的操作。
- 支持四种常见的操作:点击(Click)、悬停(Hover)、输入(Type)和选择(Select)。
- 网页快照:用作环境的快照,作者还提供了不同格式的快照:
- MHTML:包含网页的原始HTML代码。
- DOM快照:包含带有DOM、布局和样式信息的快照。
- 图像:包含网页的屏幕截图。
- HAR:包含所有网络流量以供回放。
- 跟踪:包含完整的交互跟踪以进行注释。
数据
数据通过亚马逊众包平台(Amazon Mechanical Turk)收集,主要分为三个阶段:
- 第一阶段-任务提出:首先要求工作者提出可以在给定网站上执行的任务。作者会仔细审核提出的任务,并选择在第二阶段进行注释的可行且有趣的任务。
- 第二阶段-任务演示:要求工作者演示如何在网站上执行任务。使用 Playwright 开发了一个注释工具,记录交互跟踪并在每个步骤中对网页进行快照。如图 2 所示,用红色标记的操作将导致转换到新网页。
- 第三阶段-任务验证:作者验证所有任务,以确保所有操作都是正确的,任务描述正确地反映了注释的操作。

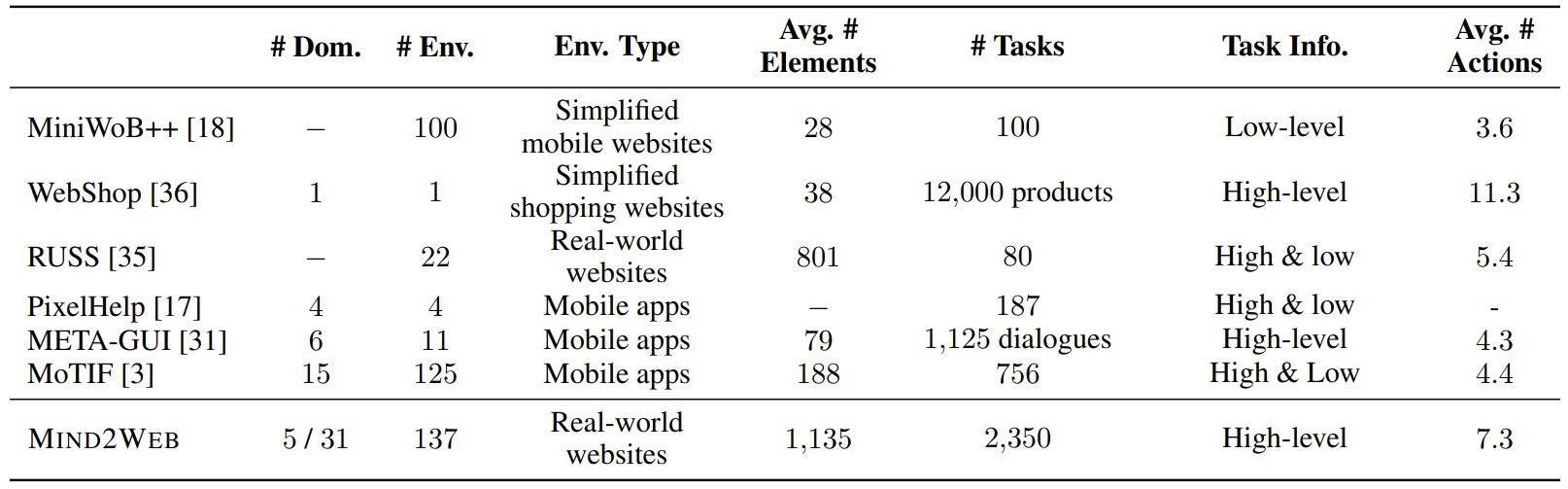
数据集统计与比较
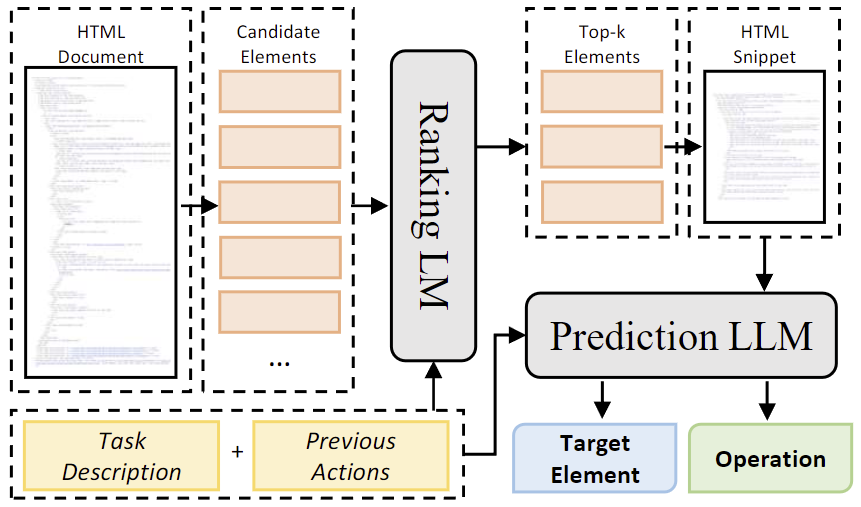
MINDACT 框架
作者利用 Mind2Web 的数据引入了一个探索性框架 MINDACT 来利用 LLM 的强大能力。原始的 HTML 文档可能包含数千个元素,直接将其输入 LLM 要么不可行,要么成本过高。
因此如图 3 所示,作者提出了一个两阶段的过程,将小型和大型 LLM 的优势相结合。
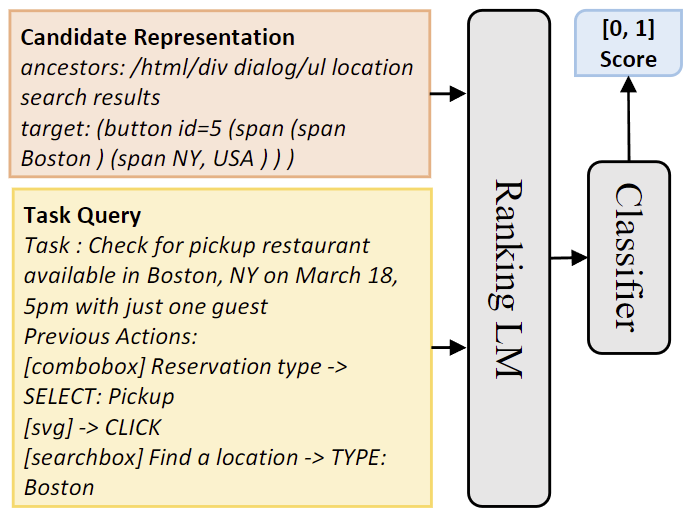
第一阶段:使用经过微调的小型 LLM 对网页上存在的元素进行排序,筛选出一小部分候选元素。如图 4 所示,将每个 DOM 元素与任务查询进行配对,并通过交叉编码器结构(Cross-Encoder)将其输入到仅编码器的 LLM 中,得到一个匹配得分。
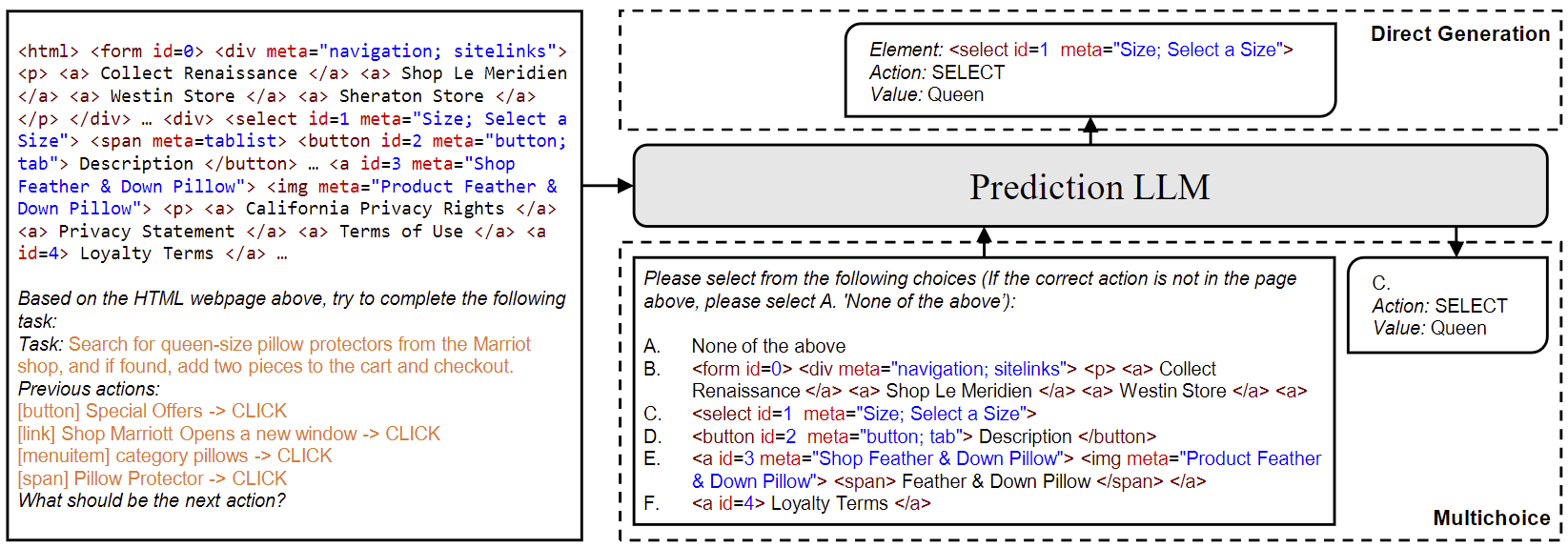
第二阶段:这些候选元素被整合成网页的代表性片段,然后由 LLM 处理以预测最终的操作,包括预测与交互的元素和相应操作。图 5 展示了一个示例,在每个输入中最多包含5个候选元素,以及一个“None”选项,并将候选集划分为若干组。
实验
- 候选元素生成:使用参数为 86M 的基础版本 DeBERTaB 作为小型 LLM,并进行了微调。在 TestCross-Task、TestCross-Website 和 TestCross-Domain 上,其 Recall@50 分别达到了 88.9%、85.3% 和85.7%。
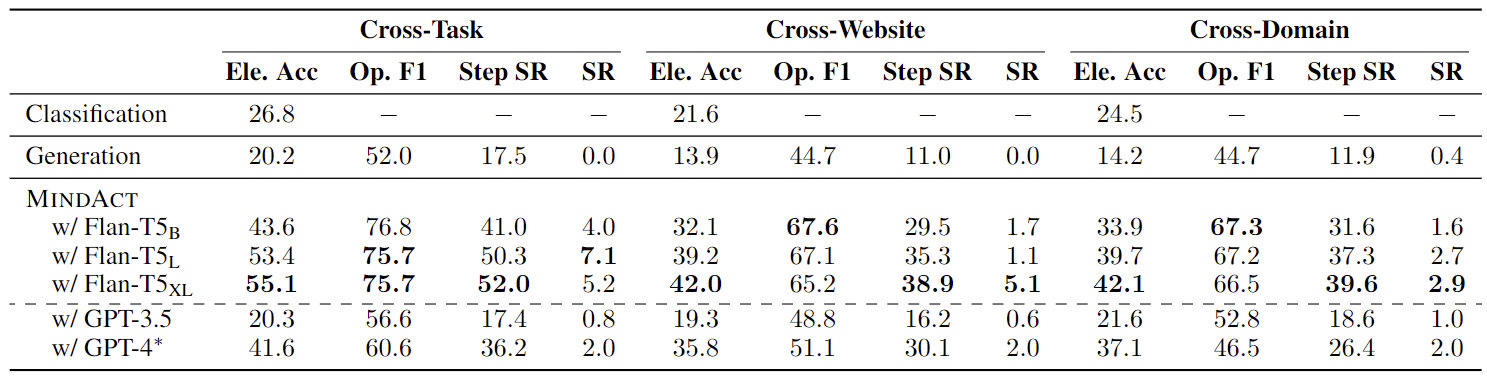
- 操作预测:如表 2 所示,在使用多选问题回答的形式时,MINDACT 表现出显著的提升。然而,对于所有模型来说,整体任务成功率仍然较低,因为在大多数情况下,智能体至少在一个步骤上出现错误。
- 三个层次的泛化能力:如图 6 所示,所有模型在跨任务设置中表现最佳,表明推广到未见环境仍然是一个主要挑战。相反,我们注意到跨网站和跨领域设置的性能非常相似,表明挑战主要源于网站设计和交互逻辑的多样性,而不是特定领域的特定问题。不同领域的任务往往共享相同的操作,预训练语言模型可能已经具备基于常识知识在高层次上分解复杂任务的能力。然而,将这样的知识应用到具体且多样化的环境中仍然是一个重大挑战。
- 使用 LLM 进行上下文学习:两个 LLM 模型,GPT-3.5-turbo 和 GPT-4 在上下文学习中表现相当。尽管 GPT-3.5 的准确率较低,但 GPT-4 在元素选择方面表现出色。然而,GPT-4 的高运行成本仍然是一个问题。因此,未来可以探索开发针对 Web 专门的较小模型方向。
小结
本文的作者们基于 Mind2Web 进行了初步探索,尝试利用大型语言模型(LLM)构建通用 Web 智能体。他们还提出了 MINDACT,一种利用 LLM 的能力来有效应对这一任务的智能体。虽然真实世界网站的原始 HTML 通常太大,无法直接输入到 LLM 中,但他们证明,通过先使用小型语言模型对其进行过滤,可以显著提高 LLM 的效果和效率。
本文的工作工作开辟了广泛的有前途的未来方向,包括整合多模态信息、利用来自真实网站的反馈进行强化学习,以及为 Web 理解和行动采取专门的语言模型。Mind2Web 的提出令人振奋,它不仅是一个普通数据集,更是一场关于智能体进化的探索。它的出现将带来前所未有的机遇和挑战,我们或许能够训练出真正的通才——一位能够在 Web 的广袤世界中独当一面的全能智能体。期待有更多的研究能揭开 Mind2Web 的精彩细节,打破任务的边界,为未来的网络智能体之旅开启全新篇章~
















 767
767

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









