






FAKE NEWS!!!
—— 唐纳德·特朗普
犹记得几年前川普当选前后,各种假新闻乱飞,川普不得不一次又一次在推上痛斥假新闻的画面。现在想想,仅仅只是文字或者P图的假新闻就已经让可怜的川宝烦不胜烦,如果是再加上现在层出不穷的各种合成视频,川宝又将如何应对呢?
3.5研究测试:
hujiaoai.cn
4研究测试:
askmanyai.cn
Claude-3研究测试:
hiclaude3.com
其实不光是川宝深受其害,即使是我们在日常生活中也常常为之迷惑,比如当看到一些所谓的“电影预告片”或者”梦想旅游目的地推荐”视频,都已经不敢再提前激动了,而是不得不先在心里打个问号,“这是真实的吗”?笔者前段时间就还为“龙妈出演真人版冰雪奇缘艾莎女王”的视频预告而期待了好久,直到后来看到另一个视频才意识到不过又是一个AI生成的“Fake Video”!
诚然,生成式AI技术的大力发展进一步拓宽了我们的创作边界,随之而来的对生成视频辨析也逐渐成为了一个社会难题。不过,据港大最新的一项研究显示,哪怕包括Sora在内的生成式视频识别其实并没有那么难,只要掌握了规律,甚至一眼就能辨别真伪。那究竟是如何做的呢?
论文标题:
What Matters in Detecting AI-Generated Videos like Sora?
论文链接:
https://arxiv.org/pdf/2406.19568

视频生成与检测
近年来,随着扩散模型(Diffusion Model)在图像合成领域的成功应用,视频生成领域也受到了启发,出现了一系列基于扩散模型的视频生成研究,如Stable Video Diffusion、Runway Gen-2和Pika Labs等模型都是通过在大量数据上训练,从而提供了高质量的视频生成能力。特别是由OpenAI开发的Sora模型,展示了模拟现实世界中人类、动物和环境的潜力,引发了人们对视频生成技术能否成为世界模拟器的讨论。
然而,尽管这些技术取得了显著进展,它们在模拟真实视频方面的能力仍然与理想状态存在差距。本文的研究团队通过使用Stable Video Diffusion模型生成合成视频,并与Pexels的真实野外视频进行比较,探讨了当前视频生成技术在外观、运动和几何这三个基本维度上的局限性。这项研究不仅有助于理解现有技术的限制,而且对于评估视频生成模型作为世界模拟器的潜力具有重要意义。
此外,检测生成图像的问题在过去几年中已经得到了广泛研究,早期的研究集中在基于GAN的模型生成图像,而随着扩散模型的发展,研究重点转向了如何检测由这些模型生成的图像。尽管如此,对于视频生成模型的鲁棒性和通用检测器的研究仍然是一个尚未充分探索的领域。本文的研究旨在填补这一空白,通过分析扩散生成的视频并提出一个简单而有效的框架,用于鲁棒和通用的生成视频检测,这不仅对技术社区具有指导意义,也对社会安全具有重要影响。
实证研究与分析
本文从Pexels收集了覆盖动物、人物、自然景观、城市景观、室内场景的真实视频,并采用最新的开源视频生成模型Stable Video Diffusion (SVD)进行领域内(in-domain)设置研究,即检测模型在同模型生成的假视频上进行训练和测试。此外,为了研究更具挑战性的跨领域(cross-domain)设置,即模型在一个AI模型(例如SVD)生成的假视频上训练,并在其他AI模型上评估。从而将测试集扩展到了由Sora、Pika Labs和Runway-Gen2生成的视频。
本文通过关键帧提取和视频片段分割来准备数据集,使用SVD模型以关键帧作为条件图像生成合成视频,从而减少真实视频和假视频之间的内容差距,随机抽取了90%的视频用于训练,剩余的用于领域内测试,并确保领域内测试集中真实视频片段和由SVD生成的合成视频数量相等,以避免模型仅依赖视频内容进行预测。
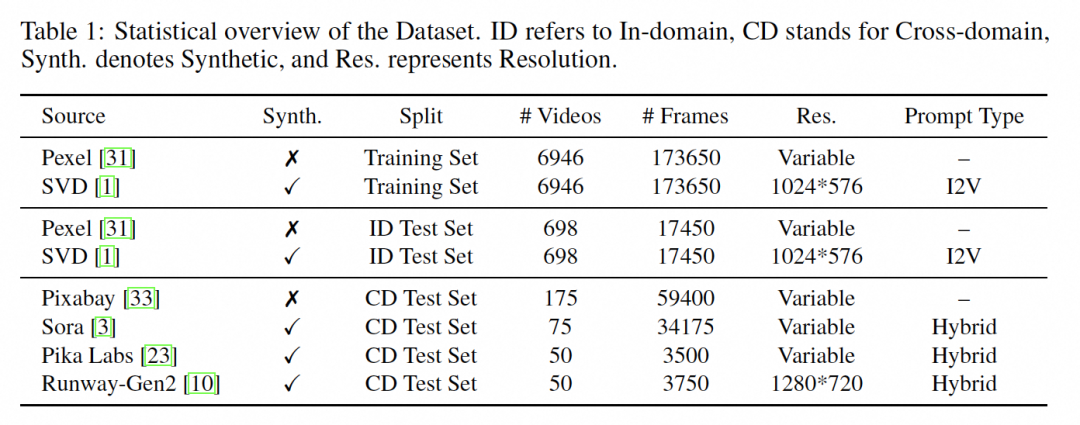
在实证研究中,研究者们设计了一个全面的视频表示(Comprehensive Video Representation, CVR),以分析AI生成的视频与真实视频之间的差异,他们将视频分解为三个组成部分:外观表示、运动表示和几何表示。
-
外观表示不仅限于原始RGB信息,还使用DINOv2模型提取每帧的高级视觉特征;
-
运动表示利用光流来研究合成视频和真实视频之间的运动模式;
-
几何表示则通过估计每帧的深度图来研究生成视频的几何属性。
通过这种分解,研究者们能够仅以CVR的一个组成部分作为输入,使用3D卷积网络单独预测视频的真实性。
外观表示

上图显示了外观分类器对三个视频的定性分析结果。对于每个视频,本文对5帧(奇数行)及其相应的渐变CAM可视化(偶数行)进行采样,以说明结果。最上面的视频是SVD从我们的域内测试集中生成的视频。下面两个来自我们由Runway-Gen2和Pika生成的跨域测试集。
可以注意到,在第一个视频中,渐变CAM识别出该男子的面部变得模糊,水瓶和桌子上的书变得扭曲,桌子表面出现了一个不自然的凹槽;在第二个视频中,渐变CAM识别了狗周围草地颜色变化不一致以及狗头部外观变化不自然的问题;在第三个视频中,渐变CAM识别出汽车周围地面的纹理和颜色都发生了突变。
运动表示

上图显示了运动分类器对两个视频的定性分析结果。对于每个视频,我们呈现采样的5帧RGB图像(第一行)、光流可视化(第二行)和相应的渐变CAM结果(第三行)。第一个视频来自我们域内测试集中SVD生成的视频,第二个视频来自我们的跨域测试集中Sora生成的视频。
在第一个视频中,渐变CAM识别出动物头部的不规则抖动模式,这违反了物理规则;在Sora生成的视频中,渐变CAM识别了由异常克隆现象引起的一些详细结构区域(例如狼的腿)中的非自然像素移动。
几何表示

上图显示了几何分类器在两个视频上的定性分析结果。每个视频都展示了采样的5帧RGB图像(第一行)、度量深度可视化(第二行)和相应的渐变CAM结果(第三行)。第一个视频来域内测试集中SVD生成的视频,第二个视频来自我们的跨域测试集中Sora生成的视频。
对于第一个视频,视频中两个角色遮挡关系的突然变化会导致某些区域(例如,距离较远的人的头部、距离较近的人的肘部和行李)的帧之间的度量深度估计结果出现不自然的变化。渐变CAM捕捉到了这些异常变化,并识别出相应的区域。在第二个视频中,场景不同区域中的个体尺度变化很大,导致具有较大尺度个体的区域中的帧之间的单目度量深度估计发生变化。渐变CAM突出显示了发生这种异常和突然变化的区域。
实验
集成专家模型
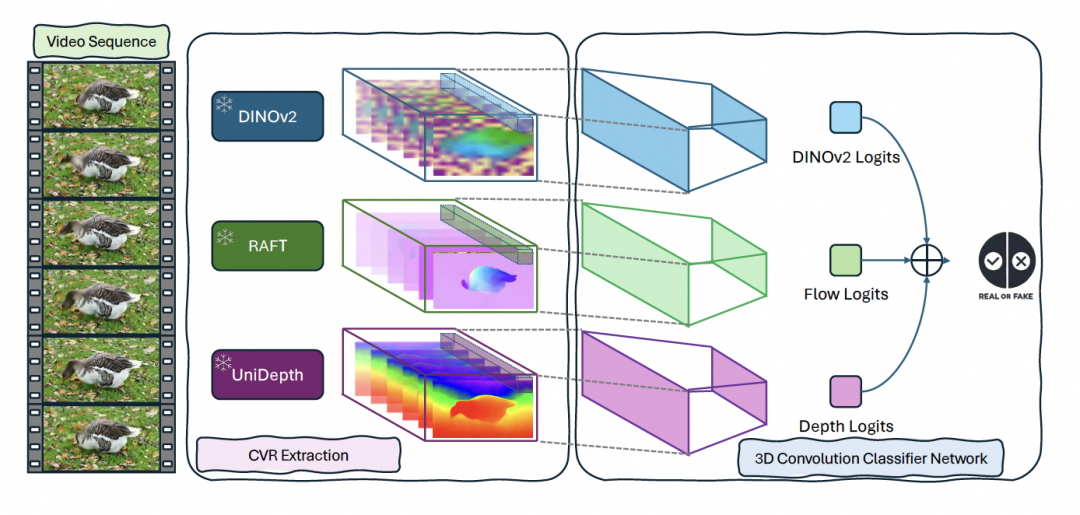
尽管基于单一输入模态的3D卷积网络检测器在领域内设置下表现良好,但在跨领域设置中,即当测试视频由与训练不同的AI模型生成时,检测准确率hhu有所下降。这表明单一检测模型在捕捉AI生成视频的共同特征方面存在局限性。
因此,本文在上述三种表示的基础上,提出了一种集成专家模型,旨在通过将外观、运动和几何三个专家模型集成到一个模型中来提高跨领域AI生成视频检测的性能。每个专家模型分别针对视频的一个方面进行评估,生成表示其对视频真实性的置信度的logits。然后,通过加权组合这些logits来获得最终的logits,其中每个模态的权重α分别对应外观、运动和几何。
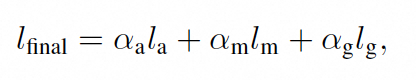
实验结果
本文发现现有方法在跨领域设置中的检测性能几乎等同于随机猜测,准确率仅为50%。这表明现有方法难以捕捉AI生成视频中的共同特征,如外观、运动和几何。相比之下,集成专家模型由于其在外观、运动和几何分类器上的综合效果以及集成策略的有效性,在跨领域检测中的表现显著优于现有工作,准确率提高了30%以上。
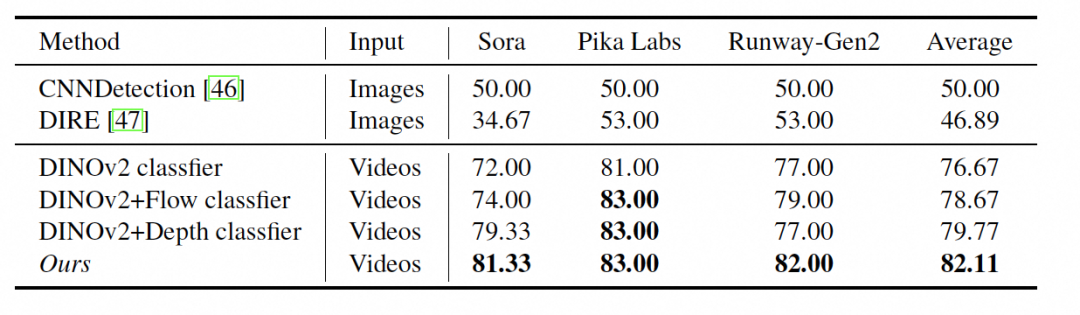
消融研究进一步评估了集成模型中每个分类器的贡献。研究发现,仅使用RGB输入和DINOv2特征的分类器已经在跨领域假视频检测中取得了不错的性能。当集成了外观和运动分类器后,性能在所有测试模型上一致提高了2%。此外,几何分类器的加入进一步提高准确率2%到8%。这些实验表明,尽管DINOv2特征在RGB输入中已经包含了一定的运动和几何信息,但独立的运动和几何模态对于鲁棒的假视频检测仍然是必要的。
最终,当所有三个分类器被集成到一起时,集成专家模型的准确性得到了进一步的提升,证明了该模型能够有效地结合每个模型的优势,有效检测包括最新一代视频生成模型Sora在内的AI生成视频,实现了AI生成视频检测的最新技术水平。
未来与展望
本文通过定性分析发现,AI生成的视频在外观上具有不一致性和扭曲,运动模式不真实,并存在违反现实世界规则的几何线索,这与我们先前读到的其他关于AI视频的分析文章是基本一致的。此外,本文还发现,即使是简单的3D CNN检测器也能在领域内设置中轻易识破AI生成的视频,因此本文进一步提供了一套基于集成专家模型的定量检测方案。训练有素的检测器能够以70%的准确率泛化到检测最先进AI模型所生成的视频,这也表明AI生成视频对比现实视频的差距在不同模型之间是存在一定共性的。
当然,本文作者也指出,由于当前视频生成模型的限制,他们的检测模型在利用长期信息进行假视频检测方面存在挑战。这强调了未来视频生成模型发展的一个重要方向,即提高生成视频的长度和质量,以更好地模拟真实世界。同时,这也为深度伪造检测技术的发展提供了新的动力,以确保我们能够跟上技术进步的步伐,更好地辨别数字内容的真实性和可信度。




















 573
573

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









