







prometheus 安装
tags: prometheus

1. 背景
TSDB(Time Series Database)时序列数据库,我们可以简单的理解为一个优化后用来处理时间序列数据的软件,并且数据中的数组是由时间进行索引的。
时间序列数据库的特点:
- 大部分时间都是写入操作。
- 写入操作几乎是顺序添加,大多数时候数据到达后都以时间排序。
- 写操作很少写入很久之前的数据,也很少更新数据。大多数情况在数据被采集到数秒或者数分钟后就会被写入数据库。
- 删除操作一般为区块删除,选定开始的历史时间并指定后续的区块。很少单独删除某个时间或者分开的随机时间的数据。
- 基本数据大,一般超过内存大小。一般选取的只是其一小部分且没有规律,缓存几乎不起任何作用。
- 读操作是十分典型的升序或者降序的顺序读。
- 常见的时间序列数据库
TSDB项目 官网
| influxDB | https://influxdata.com/ |
|---|---|
| RRDtool | http://oss.oetiker.ch/rrdtool/ |
| Graphite | http://graphiteapp.org/ |
| OpenTSDB | http://opentsdb.net/ |
| Kdb+ | http://kx.com/ |
| Druid | http://druid.io/ |
| KairosDB | http://kairosdb.github.io/ |
| Prometheus | https://prometheus.io/ |
2 简介
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。
2016年由Google发起Linux基金会旗下的原生云基金会(Cloud Native Computing Foundation), 将Prometheus纳入其下第二大开源项目。Prometheus目前在开源社区相当活跃。
Prometheus和Heapster(Heapster是K8S的一个子项目,用于获取集群的性能数据。)相比功能更完善、更全面。Prometheus性能也足够支撑上万台规模的集群。
3 特点
- 多维度数据模型。
- 灵活的查询语言。
- 不依赖分布式存储,单个服务器节点是自主的。
- 通过基于HTTP的pull方式采集时序数据。
- 可以通过中间网关进行时序列数据推送。
- 通过服务发现或者静态配置来发现目标服务对象。
- 支持多种多样的图表和界面展示,比如Grafana等。
4 组件
Prometheus生态系统由多个组件组成,它们中的一些是可选的。多数Prometheus组件是Go语言写的,这使得这些组件很容易编译和部署。
Prometheus Server:主要负责数据采集和存储,提供PromQL查询语言的支持。客户端SDK:官方提供的客户端类库有go、java、scala、python、ruby,其他还有很多第三方开发的类库,支持nodejs、php、erlang等。Push Gateway:支持临时性Job主动推送指标的中间网关。PromDash:使用Rails开发可视化的Dashboard,用于可视化指标数据。Exporter:Exporter是Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取。Prometheus提供多种类型的Exporter用于采集各种不同服务的运行状态。目前支持的有数据库、硬件、消息中间件、存储系统、HTTP服务器、JMX等。alertmanager: 警告管理器,用来进行报警。prometheus_cli: 命令行工具。其他辅助性工具:多种导出工具,可以支持Prometheus存储数据转化为HAProxy、StatsD、Graphite等工具所需要的数据存储格式。
5 架构
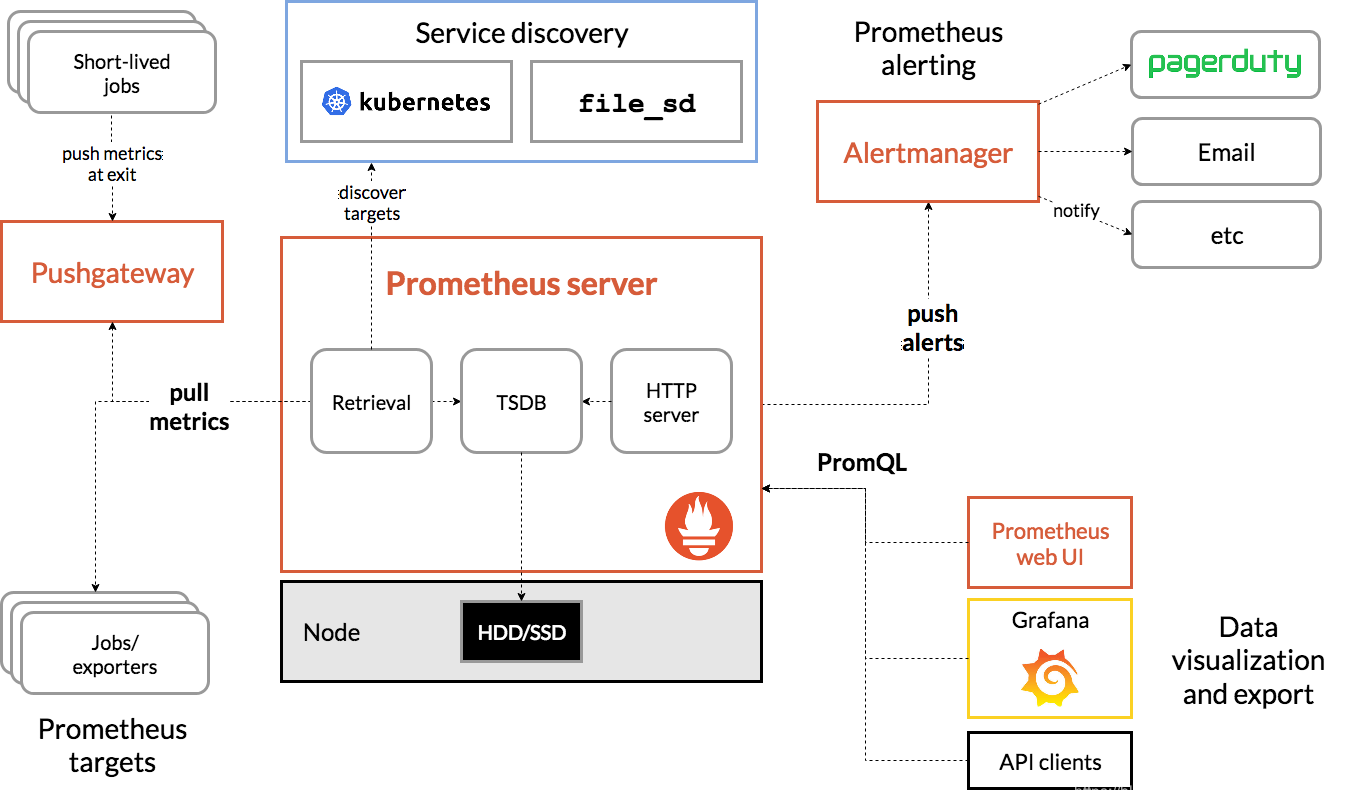
如上图,Prometheus主要由以下部分组成:
- Prometheus Server:用于抓取和存储时间序列化数据
- Exporters:主动拉取数据的插件
- Pushgateway:被动拉取数据的插件
- Altermanager:告警发送模块
- Prometheus web UI:界面化,也包含结合Grafana进行数据展示或告警发送
6 安装
Prometheus基于Golang编写,编译后的软件包,不依赖于任何的第三方依赖。用户只需要下载对应平台的二进制包,解压并且添加基本的配置即可正常启动Prometheus Server。
6.1 二进制包安装
curl -LO https://github.com/prometheus/prometheus/releases/download/v2.38.0/prometheus-2.38.0.linux-amd64.tar.gz
解压,并将Prometheus相关的命令,添加到系统环境变量路径即可:
tar -xzf prometheus-2.38.0.linux-amd64.tar.gz
cd prometheus-2.38.0.linux-amd64
解压后当前目录会包含默认的Prometheus配置文件promethes.yml:
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:9090']
promtheus作为一个时间序列数据库,其采集的数据会以文件的形式存储在本地中,默认的存储路径为data/,因此我们需要先手动创建该目录:
mkdir -p data
用户也可以通过参数--storage.tsdb.path="data/"修改本地数据存储的路径。
启动prometheus服务,其会默认加载当前路径下的prometheus.yaml文件:
./prometheus
正常的情况下,你可以看到以下输出内容:
level=info ts=2018-10-23T14:55:14.499484Z caller=main.go:554 msg="Starting TSDB ..."
level=info ts=2018-10-23T14:55:14.499531Z caller=web.go:397 component=web msg="Start listening for connections" address=0.0.0.0:9090
level=info ts=2018-10-23T14:55:14.507999Z caller=main.go:564 msg="TSDB started"
level=info ts=2018-10-23T14:55:14.508068Z caller=main.go:624 msg="Loading configuration file" filename=prometheus.yml
level=info ts=2018-10-23T14:55:14.509509Z caller=main.go:650 msg="Completed loading of configuration file" filename=prometheus.yml
level=info ts=2018-10-23T14:55:14.509537Z caller=main.go:523 msg="Server is ready to receive web requests."
6.2 docker 安装
所有 Prometheus 服务都可以在 Quay.io或 Docker Hub上作为 Docker 镜像使用。
在 Docker 上运行 Prometheus 就像docker run -p 9090:9090 prom/prometheus. 这将使用示例配置启动 Prometheus,并将其暴露在端口 9090 上。
Prometheus 映像使用卷来存储实际指标。对于生产部署,强烈建议使用 命名卷 来简化 Prometheus 升级数据的管理。
要提供您自己的配置,有几个选项。这里有两个例子。
6.2.1 配置文件prometheus.yml Volumes & bind-mount 挂载
prometheus.yml通过运行以下命令从主机绑定挂载:
docker run \
-p 9090:9090 \
-v /path/to/prometheus.yml:/etc/prometheus/prometheus.yml \
prom/prometheus
或者通过运行绑定挂载包含prometheus.yml到 的目录/etc/prometheus:
docker run \
-p 9090:9090 \
-v /path/to/config:/etc/prometheus \
prom/prometheus
6.2.2 数据存储 /prometheus Volumes 挂载
#测试安装
$ docker run -d -p 9090:9090 --name prometheus docker.io/prom/prometheus:latest
#配置与数据持久存储部署
$ chown -R 65534:65534 /monitor/prometheus/data
$ docker run -d -p 9090:9090 -v /monitor/prometheus/config:/etc/prometheus -v /monitor/prometheus/data:/prometheus --name prometheus docker.io/prom/prometheus:latest
6.2.3 添加自定义参数
#定制版安装
$ chown -R 65534:65534 /monitor/prometheus/data
$ docker run -tid -p 9090:9090 --restart=always -v /monitor/prometheus/config/prometheus:/etc/prometheus:z -v /monitor/prometheus/data:/prometheus:z --name prometheus docker.io/prom/prometheus:latest "--config.file=/etc/prometheus/prometheus.yml" "--storage.tsdb.path=/prometheus" "--web.console.libraries=/usr/share/prometheus/console_libraries" "--web.console.templates=/usr/share/prometheus/consoles" "--storage.tsdb.retention.time=15d" "--storage.tsdb.min-block-duration=6h" "--web.enable-admin-api" "--web.enable-lifecycle"
6.3 Ansible
6.4 Chef
6.5 Puppet
6.6 SaltStack
6.7 Deploy prometheus on Kubernetes
6.7.1 ConfigMaps 管理应用配置
当使用Deployment管理和部署应用程序时,用户可以方便了对应用进行扩容或者缩容,从而产生多个Pod实例。为了能够统一管理这些Pod的配置信息,在Kubernetes中可以使用ConfigMaps资源定义和管理这些配置,并且通过环境变量或者文件系统挂载的方式让容器使用这些配置。
这里将使用ConfigMaps管理Prometheus的配置文件,创建prometheus-config.yml文件,并写入以下内容:
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
data:
prometheus.yml: |
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
使用kubectl命令行工具,在命名空间default创建ConfigMap资源:
kubectl create -f prometheus-config.yml
configmap "prometheus-config" created
6.7.2 Deployment 部署 Prometheus
当ConfigMap资源创建成功后,我们就可以通过Volume挂载的方式,将Prometheus的配置文件挂载到容器中。 这里我们通过Deployment部署Prometheus Server实例,创建prometheus-deployment.yml文件,并写入以下内容:
apiVersion: v1
kind: "Service"
metadata:
name: prometheus
labels:
name: prometheus
spec:
ports:
- name: prometheus
protocol: TCP
port: 9090
targetPort: 9090
selector:
app: prometheus
type: NodePort
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
labels:
name: prometheus
name: prometheus
spec:
replicas: 1
template:
metadata:
labels:
app: prometheus
spec:
containers:
- name: prometheus
image: prom/prometheus:v2.2.1
command:
- "/bin/prometheus"
args:
- "--config.file=/etc/prometheus/prometheus.yml"
ports:
- containerPort: 9090
protocol: TCP
volumeMounts:
- mountPath: "/etc/prometheus"
name: prometheus-config
volumes:
- name: prometheus-config
configMap:
name: prometheus-config
该文件中分别定义了Service和Deployment,Service类型为NodePort,这样我们可以通过虚拟机IP和端口访问到Prometheus实例。为了能够让Prometheus实例使用ConfigMap中管理的配置文件,这里通过volumes声明了一个磁盘卷。并且通过volumeMounts将该磁盘卷挂载到了Prometheus实例的/etc/prometheus目录下。
使用以下命令创建资源,并查看资源的创建情况:
$ kubectl create -f prometheus-deployment.yml
service "prometheus" created
deployment "prometheus" created
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
prometheus-55f655696d-wjqcl 1/1 Running 0 5s
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 131d
prometheus NodePort 10.101.255.236 <none> 9090:32584/TCP 42s
访问
http://<主机地址>:32583

6.8 自定义镜像 prometheus
Dockerfile
FROM prom/prometheus
ADD prometheus.yml /etc/prometheus/
构建并运行
docker build -t my-prometheus .
docker run -p 9090:9090 my-prometheus
7 启动参数
-h, --help:显示帮助信息
--version:显示版本信息
--config.file="prometheus.yml":启动时,指定Prometheus读取配置文件的路径。
--web.listen-address="0.0.0.0:9090" :指定网页打开Prometheus的ip和端口,默认为"0.0.0.0:9090"。
--web.read-timeout=5m:页面读取请求最大超时时间 。
--web.max-connections=512:同时访问Prometheus页面的最大连接数,默认为512。
--web.external-url=<URL>:Prometheus对外提供的url(eg: Prometheus通过反向代理提供服务)。用于生成一个相对和绝对的链接返回给Prometheus本身。如果这个url有路径部分,它将用于Prometheus所有HTTP端点的前缀。如果省略了,则相关的url组件将自动派生(If the URL has a path portion, it will be used to prefix all HTTP endpoints served by Prometheus. If omitted, relevant URL components will be derived automatically)。
--web.route-prefix=<path>:Web端点内部路由的前缀。默认路径:web.external-url。
--web.user-assets=<path>:静态资源路径,可以在/user下找到。
--web.enable-lifecycle:通过HTTP请求启用关闭和重新加载。
--web.enable-admin-api:启用管理控制操作的api端点。(Enables API endpoints for admin control actions)
--web.console.templates="consoles":到控制台模板目录的路径,可以在consoles/目录下找到。
--web.console.libraries="console_libraries":控制台库目录的路径。
--storage.tsdb.path="data/":存储的基本路径。
--storage.tsdb.min-block-duration=2h:在持久化之前数据块的最短保存期。
--storage.tsdb.max-block-duration=<duration>:在持久化之前数据块的最大保存期(默认为保存期的10%)。
--storage.tsdb.retention=15d:存储采样的保存时间。
--storage.tsdb.no-lockfile:不在数据目录中创建lockfile(Do not create lockfile in data directory)。
--alertmanager.notification-queue-capacity=10000:等待报警通知队列的大小。
--alertmanager.timeout=10s:发送警报到Alertmanager的超时时间。
--query.lookback-delta=5m:允许在表达式求值期间检索度量值的delta差值(The delta difference allowed for retrieving metrics during expression evaluations)。
--query.timeout=2m: 一个查询在终止之前可以执行的最长时间(如果超过2min,就会自动kill掉)。
--query.max-concurrency=20:并发执行的最大查询数,默认为20。
--log.level=info: 开启打印日志级别(debug,info,warn,error,fatal)。默认为info。
配置--web.enable-lifecycle后,API可重载配置文件
curl -X POST http://localhost:9090/-/reload
8. 配置
模板
global:
scrape_interval: 15s # 采集间隔15s,默认为1min一次
evaluation_interval: 15s # 计算规则的间隔15s默认为1min一次
scrape_timeout: 10s # 采集超时时间,默认为10s
external_labels: # 当和其他外部系统交互时的标签,如远程存储、联邦集群时
prometheus: monitoring/k8s # 如:prometheus-operator的配置
prometheus_replica: prometheus-k8s-1
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.211.16:9093
rule_files:
- "*rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.211.16:9090']
8.1 全局配置global
global 属于全局的默认配置,它主要包含 4 个属性,
scrape_interval: 拉取 targets 的默认时间间隔。默认每隔15秒
scrape_timeout: 拉取一个 target 的超时时间。默认每隔10秒
evaluation_interval: 执行 rules 的时间间隔。监控的评估频率,默认15秒
external_labels: 为指标增加额外的维度,可用于区分不同的prometheus,在应用中多个
prometheus可以对应一个alertmanager
8.2 rule_files
指定告警策略文件
格式:
rule_files:
- "*rules.yml"
默认情况下Prometheus会每分钟对这些告警规则进行计算,如果用户想定义自己的告警计算周期,则可以通过evaluation_interval来覆盖默认的计算周期。
8.3 scrape_configs配置
scrape_configs 主要用于配置拉取数据节点,每一个拉取配置主要包含以下参数:
job_name:任务名称
honor_labels: 用于解决拉取数据标签有冲突,当设置为 true, 以拉取数据为准,否则以服务配置为准
params:数据拉取访问时带的请求参数
scrape_interval: 拉取时间间隔
scrape_timeout: 拉取超时时间
metrics_path: 拉取节点的 metric 路径
scheme: 拉取数据访问协议
sample_limit: 存储的数据标签个数限制,如果超过限制,该数据将被忽略,不入存储;默认值为0,表示没有限制
relabel_configs: 拉取数据重置标签配置
metric_relabel_configs:metric 重置标签配置
示例:重定义标签,将__address__改为ip
- job_name: 'node-exporter'
static_configs:
- targets:
- '192.168.1.193:9100'
relabel_configs:
- source_labels: [__address__]
regex: (.+):(.+)
target_label: __tmp_ip
replacement: ${1}
- source_labels: [__tmp_ip]
regex: (.*)
target_label: ip
replacement: ${1}
9 告警
9.1 格式
groups:
- name: example
rules:
- alert: HighErrorRate
expr: job:request_latency_seconds:mean5m{job="myjob"} > 0.5
for: 10m
labels:
severity: page
annotations:
summary: High request latency
description: description info
9.2 参数说明
在告警规则文件中,我们可以将一组相关的规则设置定义在一个group下。在每一个group中我们可以定义多个告警规则(rule)。一条告警规则主要由以下几部分组成:
-
alert:告警规则的名称。 -
expr:基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。 -
for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。 -
labels:自定义标签,允许用户指定要附加到告警上的一组附加标签。 -
severity:设置告警级别,例如:正常、告警、错误、严重、紧急等。 -
annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字,内容在告警产生时会一同作为参数发送到Alertmanager。 -
info:内容在告警产生时会一同作为参数发送到Alertmanager -
summary:支持特定的匹配规则,将内容发送Alertmanager -
description:内容在告警产生时会一同作为参数发送到Alertmanager
9.3 模板说明
Prometheus支持模板化label和annotations的中标签的值。
通过
l
a
b
e
l
s
.
<
l
a
b
e
l
n
a
m
e
>
变量可以访问当前告警实例中指定标签的值。
labels.<labelname>变量可以访问当前告警实例中指定标签的值。
labels.<labelname>变量可以访问当前告警实例中指定标签的值。value则可以获取当前PromQL表达式计算的样本值。
# To insert a firing element's label values:
{{ $labels.<labelname> }}
# To insert the numeric expression value of the firing element:
{{ $value }}
示例:
groups:
- name: example
rules:
# Alert for any instance that is unreachable for >5 minutes.
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
10. prometheus metrics
arp 域名解析/proc/net/arp.
bcache缓存 /sys/fs/bcache/.
bonding 绑定
conntrack 链接跟踪模块 /proc/sys/net/netfilter/ present). x
cpu
diskstats磁盘进出进程 disk I/O
edac 错误校检与纠正
entropy 熵
exec 执行程序
filefd 公开文件描述符 /proc/sys/fs/file-nr.
filesystem 文件系统 disk space used.
hwmon 硬件与传感器 /sys/class/hwmon/. x
infiniband 无线带宽技术
ipvs /proc/net/ip_vs and /proc/net/ip_vs_stats.
loadavg 平均负载
mdadm /proc/mdstat (does nothing if no /proc/mdstat present) 设备
meminfo Exposes memory statistics. Darwin, Dragonfly, FreeBSD, Linux, OpenBSD
netdev Exposes network interface statistics such as bytes transferred. Darwin, Dragonfly, FreeBSD, Linux, OpenBSD
netstat Exposes network statistics from /proc/net/netstat. This is the same information as netstat -s. Linux
nfs Exposes NFS client statistics from /proc/net/rpc/nfs. This is the same information as nfsstat -c. Linux
nfsd Exposes NFS kernel server statistics from /proc/net/rpc/nfsd. This is the same information as nfsstat -s. Linux
sockstat Exposes various statistics from /proc/net/sockstat. Linux
stat Exposes various statistics from /proc/stat. This includes boot time, forks and interrupts. Linux
textfile Exposes statistics read from local disk. The --collector.textfile.directory flag must be set. any
time Exposes the current system time. any
timex Exposes selected adjtimex(2) system call stats. Linux
uname Exposes system information as provided by the uname system call. Linux
vmstat Exposes statistics from /proc/vmstat. Linux
wifi Exposes WiFi device and station statistics. Linux
xfs Exposes XFS runtime statistics. Linux (kernel 4.4+)
zfs Exposes ZFS performance statistics. Linux
Disabled by default
Name Description OS
buddyinfo Exposes statistics of memory fragments as reported by /proc/buddyinfo. Linux
devstat Exposes device statistics Dragonfly, FreeBSD
drbd Exposes Distributed Replicated Block Device statistics (to version 8.4) Linux
interrupts Exposes detailed interrupts statistics. Linux, OpenBSD
ksmd Exposes kernel and system statistics from /sys/kernel/mm/ksm. Linux
logind Exposes session counts from logind. Linux
meminfo_numa Exposes memory statistics from /proc/meminfo_numa. Linux
mountstats Exposes filesystem statistics from /proc/self/mountstats. Exposes detailed NFS client statistics. Linux
ntp Exposes local NTP daemon health to check time any
qdisc Exposes queuing discipline statistics Linux
runit Exposes service status from runit. any
supervisord Exposes service status from supervisord. any
systemd Exposes service and system status from systemd. Linux
tcpstat Exposes TCP connection status information from /proc/net/tcp and /proc/net/tcp6. (Warning: the current version has potential performance issues in high load situations.) Linux
11. promtool 工具
11.1 检查metrics
curl -s http://localhost:9090/metrics | promtool check metrics
11.2 检查配置文件
promtool check config /etc/prometheus/prometheus.yml
11.3 检查告警策略文件
promtool check rules /path/to/example.rules.yml
参考:















 6316
6316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











