







1. VC的编码我们大致可以分为两类:文件编码和内存编码。
文件编码(用UntraEdit可以看到里面的编码)即源代码文件的编码,gbk,UTF-8等。
内存编码即源代码编译成为二进制文件的时候采用的编码。
2. 在此我要说的是内存编码;内存编码在VC中只有3个选项:
(1)Not Set
(2)Use Multi-Byte Character Set
(3)Use Unicode Character Set。
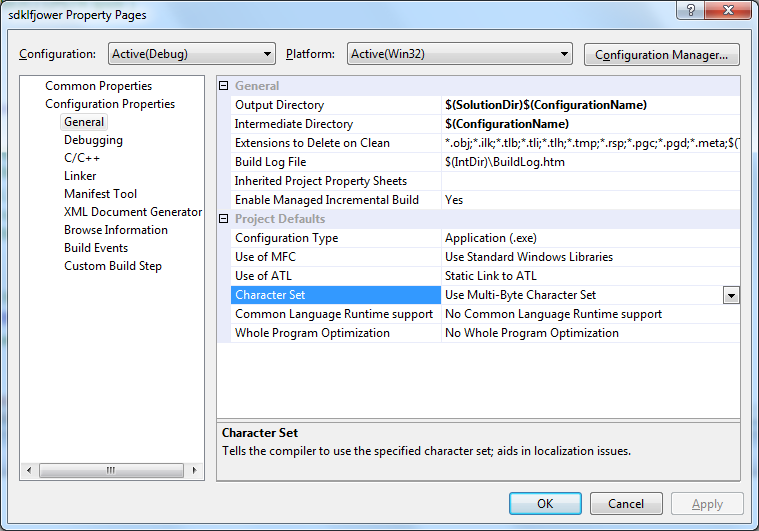
3. Multi-Byte Character Set(MBCS)
多字节字符集,字符的大小是可变的;一个MBCS编码包含一些一个字节长的字符,而另一些字符大于一个字节的长度。
一个MBCS编码包含一些一个字节长的字符,而另一些字符大于一个字节的长度。用在Windows里的MBCS包含两种字符类型,单字节字符(single-byte characters)和双字节字符(double-byte characters)。由于Windows里使用的多字节字符绝大部分是两个字节长,所以MBCS常被用DBCS(double-byte character set or DBCS)代替。
在DBCS编码模式中,一些特定的值被保留用来表明他们是双字节字符的一部分。例如,在Shift-JIS编码中(一个常用的日文编码模式),0x81-0x9f之间和 0xe0-oxfc之间的值表示"这是一个双字节字符,下一个子节是这个字符的一部分。"这样的值被称作"leading bytes",他们都大于0x7f。跟随在一个leading byte子节后面的字节被称作"trail byte"。在DBCS中,trail byte可以是任意非0值。像SBCS一样,DBCS字符串的结束标志也是一个单字节表示的0。
Unicode是一种所有的字符都使用两个字节编码的编码模式。Unicode字符有时也被称作宽字符(Wide Character),因为它比单子节字符宽(使用了更多的存储空间)。注意,Unicode不能被看作MBCS。MBCS的独特之处在于它的字符使用不同长度的字节编码。Unicode字符串使用两个字节表示的0作为它的结束标志。
5. 参考
(1)http://blog.csdn.net/jackiezhw/article/details/3901685
(2)http://blog.csdn.net/jackiezhw/article/details/3901685















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









