







初试Scrapy(三)下—CSDN自动登录获取博客分类列表
接上篇文章—初试Scrapy(三)上—CSDN自动登录获取博客分类列表,这篇文章主要学习下通过Scrapy创建工程,并且实现CSDN自动登录,获取博客分类列表。
一,创建工程
Scrapy框架更新到现在已经很完善,可以直接通过如下命令来创建你的工程:
scrapy startproject Blog_Category这命令会创建一个Blog_Category目录和如下内容:
Blog_Category/
|-- Blog_Category # project's Python module, you'll import your code from here
| |-- __init__.py
| |-- items.py # project items definition file
| |-- pipelines.py # project pipelines file
| |-- settings.py # project settings file
| `-- spiders
| |-- __init__.py
`-- scrapy.cfg # deploy configuration file
二,生成Spider
上面只是创建了工程的整个框架结构,还没有定义的spider,可以通过如下命令来生成自己的Spider:
scrapy genspider csdn csdn.net注意这条命令要在进入到上面创建成功的工程目录下来执行,Scrapy有些命令是在工程内部运行,有些则是全局命令,具体解释可以参考官方文档—commands reference,执行完上面的命令之后,再来看我们整个工程结构如下:
Blog_Category/
|-- Blog_Category
| |-- __init__.py
| |-- items.py
| |-- pipelines.py
| |-- settings.py
| `-- spiders
| |-- csdn.py
| |-- __init__.py
`-- scrapy.cfg可以发现spiders目录下面比上面多出一个文件—csdn.py,这就是我们的Spider文件,对网页内容的抓取就是通过这个文件来实现。可以简单看到这个文件内容如下:
# -*- coding: utf-8 -*-
import scrapy
class CsdnSpider(scrapy.Spider):
name = "csdn"
allowed_domains = ["csdn.net"]
start_urls = ['http://csdn.net/']
def parse(self, response):
pass其中name就是我们上面执行命令事传入的第一个参数,就是我们Spider的名字,这个名字要保证不要跟其他工程中Spider的名字雷同,上面执行命令传入的第二参数为被定义为allowed_domains,甚至后面的start_urls也是有这个参数延伸而来,后续这l两个字段都是可以手动在修改的。其中name字段也是可以修改,但是就会有其他位置也要牵连着修改,个人不建议修改。
三,完善功能代码
Scrapy架构该生成的代码都完成,接下来就该完善功能代码,基于上一篇文章的基础,这篇文章实现起来也比较简单,我们的spdier的代码(csdn.py文件)如下:
# -*- coding: utf-8 -*-
import scrapy
from Blog_Category.items import BlogCategoryItem
# from scrapy.shell import inspect_response
class CsdnSpider(scrapy.Spider):
name = "csdn"
allowed_domains = ["csdn.net"]
def start_requests(self):
return [scrapy.Request("http://passport.csdn.net/account/login", callback=self.__post_login)]
@staticmethod
def __get_key_value(response, keystr):
# '用来得到关键字段的值'
# '或者通过css选取器可以如下'
# return response.css('input[name="lt"] ::attr(value)').extract_first()
# '或者通过xpath可以如下'
return response.xpath(u'//input[@name=\"{0}\"]/@value'.format(keystr)).extract_first()
def __post_login(self, response):
# '通过post登陆'
post_data = {
'username': getattr(self, 'username', None),
'password': getattr(self, 'password', None),
'lt': CsdnSpider.__get_key_value(response, 'lt'),
'execution': CsdnSpider.__get_key_value(response, 'execution'),
'_eventId': 'submit',
}
return [scrapy.FormRequest.from_response(response, formdata=post_data, callback=self.__check_login_status)]
def __check_login_status(self, response):
# '用来检测是否登陆成功'
# 'jspath = response.css('script ::attr(src)').extract_first()'
jspath = response.xpath('//script/@src').extract_first()
# 'if succeed '
if jspath == '/content/loginbox/loginapi.js':
# 'redirect to the last url'
return [scrapy.Request("http://write.blog.csdn.net/category", headers=response.headers,
callback=self.parse)]
else:
# error_mess = response.xpath('//div[@class="error-mess"]/span[@id="error-message"]/text()').extract_first()
error_mess = response.css('div[class=error-mess] span[id=error-message]::text').extract_first()
if error_mess:
raise scrapy.exceptions.CloseSpider(error_mess)
else:
raise scrapy.exceptions.CloseSpider(u'服务器错误 HTTP Error 500: Internal Server Error')
def parse(self, response):
# for tdleft in response.xpath('//tbody[@id="lstBody"]/tr'):
for tdleft in response.css('tbody[id=lstBody] tr'):
# yield {
# # 'category', tdleft.xpath('td[@class="tdleft"]/span/text()').extract_first()
# 'category': tdleft.css('td[class=tdleft] span::text').extract_first(),
# # number': tdleft.xpath('td/a[@class="red"]/text()').extract_first(),
# 'number': tdleft.css('td a[class=red]::text').extract_first(),
# }
yield BlogCategoryItem({
# 'category', tdleft.xpath('td[@class="tdleft"]/span/text()').extract_first()
'category': tdleft.css('td[class=tdleft] span::text').extract_first(),
# number': tdleft.xpath('td/a[@class="red"]/text()').extract_first(),
'number': tdleft.css('td a[class=red]::text').extract_first(),
})
Scrapy对Html的解析有自己一套机制,速度比较快,也比较容易使用,这里不做过多解释,可以自行参看官方文档—Selectors,其对css和xpath两种都支持,代码中通过注释我把通过css和xpath解析的代码都给出,测试过可用。
这里也要考虑伪装user-agent的问题,在网上找到一个基于Scrapy的生成随机user agent的库—scrapy-fake-useragent,可以通过sudo pip install scrapy-fake-useragent命令来安装,代码中使用时需要以Scrapy中间件的形式来激活,其修改配置文件(settings.py)如下:
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
# 'Blog_Category.middlewares.MyCustomDownloaderMiddleware': 543,
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'scrapy_fake_useragent.middleware.RandomUserAgentMiddleware': 400,
}上面代码中BlogCategoryItem即为我们通过Blog_Category.items.py文件定义的我们要抓取之后数据保存的格式,其实现很简单:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class BlogCategoryItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
category = scrapy.Field()
number = scrapy.Field()我们就定义了category和number两个字段,scrapy.Item的具体实现有点类似Python中的dict类型,具体细节可参看官方文档—Items。
之后就是我们的Blog_Category/pipelines.py文件,文件内容如下:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import re
import scrapy
from Blog_Category.items import BlogCategoryItem
# import logging
# import inspect
class BlogCategoryPipeline(object):
def process_item(self, item, spider):
# frame = inspect.currentframe()
# logging.log(logging.DEBUG, "### FUNC {0} line {1}###".format(__name__, frame.f_lineno))
# logging.log(logging.DEBUG, "### item {0} ###".format(item))
category = item.get('category', None)
# logging.log(logging.DEBUG, "### category {0} ###".format(category.encode('utf-8')))
if category and re.search(u'^Qt', category):
raise scrapy.exceptions.DropItem("Drop item startwiths 'Qt' : %s" % item)
return item这个管道文件主要是对抓取的数据进行一步处理,比如有些无效的数据,或者重复的数据,我代码中只是简单的做了一个测试,把我抓取的数据中以Qt开头的那条数据给丢弃,这个文件也可以用来实现保存自己抓取的数据,如数据库中,具体实现可以参考官方文档—Item Pipeline。
要激活使用这个管道文件,需要修改配置文件—settings.py:
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'Blog_Category.pipelines.BlogCategoryPipeline': 300,
}其他文件没做修改,整个工程放在CSDN上:Scrapy实现CSDN自动登录获取博客分类列表,有需要的可以去下载,如有错误希望指正。
最后运行情况如下:
scrapy crawl csdn -a username=aaaaaaaa -a password=bbbbbbb -s FEED_EXPORT_ENCODING=utf-8 -o category.json用户名,密码都是通过参数形式传入,生成的category.json内容如下:
[james_xie@james-desk Blog_Category]$ cat category.json
[
{"category": "C/C++学习", "number": "6"},
{"category": "Gstreamer学习", "number": "1"},
{"category": "计算机网络通信", "number": "2"},
{"category": "交叉编译环境的建立", "number": "3"},
{"category": "shell脚本学习", "number": "2"},
{"category": "Android学习", "number": "4"},
{"category": "Python学习", "number": "4"}
][james_xie@james-desk Blog_Category]$ 和我网站上访问博客列表结果对比:
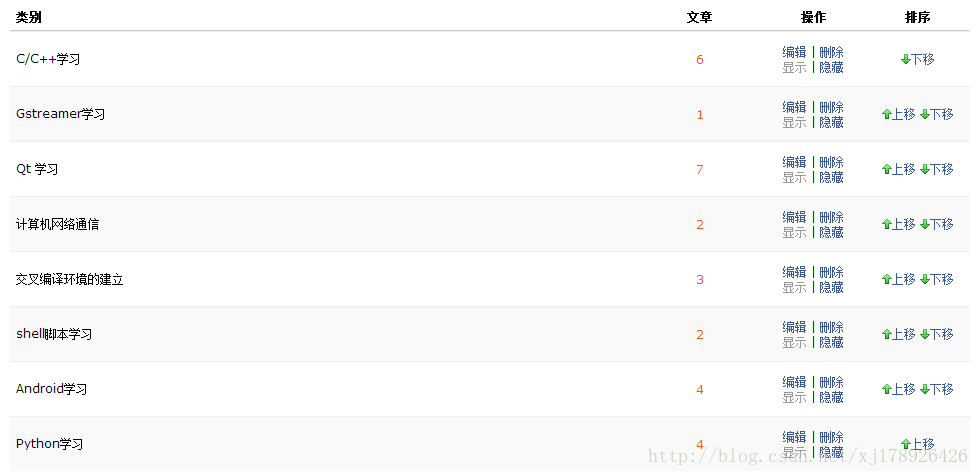
可以看到结果没有问题,其中Qt学习这一项已经被我在上面代码中处理去掉。
四,调试技巧
在写程序过程中,难免需要调试,在抓取网页的内容时,我们需要确认抓取的内容是否准确,下面是我这简短的学习中总结的一些比较实用的技巧,大家如果有什么跟好的方式调试希望给我提出。
1,Scrapy shell使用
关于这个的使用还是直接看官方文档—Scrapy shell,我蹩脚的英文翻译出来自己都看不下去。通过Scrapy shell来调试主要有两种方式:1)使用Scrapy shell会话,2)在Spider代码中调用。通过我的使用过程来分别介绍下这两种方式。
1)使用Scrapy shell会话
如上面代码中,我需要抓取CSDN登录界面POST的form表中两个关键字段lt和execution的值,下面是通过浏览器截取的一段CSDN登录界面—-http://passport.csdn.net/account/login 中form表单的html代码:
<form id="fm1" action="/account/login;jsessionid=81A8B8A74543DBA04ACCA783FBB9CD98.tomcat2" method="post">
<input id="username" name="username" tabindex="1" placeholder="输入用户名/邮箱/手机号" value="aaaaaaaaaaaa" class="user-name" type="text" value=""/>
<input id="password" name="password" tabindex="2" placeholder="输入密码" class="pass-word" type="password" value="" autocomplete="off"/>
<div class="error-mess" style="display:none;">
<span class="error-icon"></span><span id="error-message"></span>
</div>
<div class="row forget-password">
<span class="col-xs-6 col-sm-6 col-md-6 col-lg-6">
<input type="checkbox" name="rememberMe" id="rememberMe" value="true" class="auto-login" tabindex="4"/>
<label for="rememberMe">下次自动登录</label>
</span>
<span class="col-xs-6 col-sm-6 col-md-6 col-lg-6 forget tracking-ad" data-mod="popu_26">
<a href="/account/fpwd?action=forgotpassword&service=http%3A%2F%2Fwww.csdn.net%2F" tabindex="5">忘记密码</a>
</span>
</div>
<!-- 该参数可以理解成每个需要登录的用户都有一个流水号。只有有了webflow发放的有效的流水号,用户才可以说明是已经进入了webflow流程。否则,没有流水号的情况下,webflow会认为用户还没有进入webflow流程,从而会重新进入一次webflow流程,从而会重新出现登录界面。 -->
<input type="hidden" name="lt" value="LT-823177-1Rj9dEncAssnLsGoP2WzsZXhtgUScJ" />
<input type="hidden" name="execution" value="e1s1" />
<input type="hidden" name="_eventId" value="submit" />
<input class="logging" accesskey="l" value="登 录" tabindex="6" type="button" />
</form>其中这两个字段就是我们需要获取的:
<!-- 该参数可以理解成每个需要登录的用户都有一个流水号。只有有了webflow发放的有效的流水号,用户才可以说明是已经进入了webflow流程。否则,没有流水号的情况下,webflow会认为用户还没有进入webflow流程,从而会重新进入一次webflow流程,从而会重新出现登录界面。 -->
<input type="hidden" name="lt" value="LT-823177-1Rj9dEncAssnLsGoP2WzsZXhtgUScJ" />
<input type="hidden" name="execution" value="e1s1" /> 这个时候我们就可以通过Scrapy shell会话直接调试我们抓取的值是否正确,如下所示:
[james_xie@james-desk PycharmProjects]$ scrapy shell http://passport.csdn.net/account/login --nolog
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x2c78b50>
[s] item {}
[s] request <GET http://passport.csdn.net/account/login>
[s] response <200 http://passport.csdn.net/account/login>
[s] settings <scrapy.settings.Settings object at 0x2c78a50>
[s] spider <DefaultSpider 'default' at 0x308d6d0>
[s] Useful shortcuts:
[s] shelp() Shell help (print this help)
[s] fetch(req_or_url) Fetch request (or URL) and update local objects
[s] view(response) View response in a browser
>>> print(response.xpath(u'//input[@name="lt"]/@value').extract_first())
LT-822877-kHmLDXeDUjVuY99Io9BHai1mXL3CEk
>>> print(response.xpath(u'//input[@name="execution"]/@value').extract_first())
e1s1
>>> 这样就比较直白快速,不用运行程序。
2)在Spider代码中调用
上面那种方式虽然直白,简单,但是有些特殊情况没办法使用,比如我们获取博客分类列表的时候,需要登录之后才可以,这个时候我们可以在Spider代码中调用来进入Scrapy shell会话中。例如我们的Spider代码中,在登录完成之后,进入我们要解析的最后页面时,这个时候就可以在代码中调用来进入Scrapy shell会话。如下:
# -*- coding: utf-8 -*-
import scrapy
from Blog_Category.items import BlogCategoryItem
class CsdnSpider(scrapy.Spider):
name = "csdn"
allowed_domains = ["csdn.net"]
def start_requests(self):
return [scrapy.Request("http://passport.csdn.net/account/login", callback=self.__post_login)]
@staticmethod
def __get_key_value(response, keystr):
# '用来得到关键字段的值'
# '或者通过css选取器可以如下'
# return response.css('input[name="lt"] ::attr(value)').extract_first()
# '或者通过xpath可以如下'
return response.xpath(u'//input[@name=\"{0}\"]/@value'.format(keystr)).extract_first()
def __post_login(self, response):
# '通过post登陆'
post_data = {
'username': getattr(self, 'username', None),
'password': getattr(self, 'password', None),
'lt': CsdnSpider.__get_key_value(response, 'lt'),
'execution': CsdnSpider.__get_key_value(response, 'execution'),
'_eventId': 'submit',
}
return [scrapy.FormRequest.from_response(response, formdata=post_data, callback=self.__check_login_status)]
def __check_login_status(self, response):
# '用来检测是否登陆成功'
# 'jspath = response.css('script ::attr(src)').extract_first()'
jspath = response.xpath('//script/@src').extract_first()
# 'if succeed '
if jspath == '/content/loginbox/loginapi.js':
# 'redirect to the last url'
return [scrapy.Request("http://write.blog.csdn.net/category", headers=response.headers,
callback=self.parse)]
else:
# error_mess = response.xpath('//div[@class="error-mess"]/span[@id="error-message"]/text()').extract_first()
error_mess = response.css('div[class=error-mess] span[id=error-message]::text').extract_first()
if error_mess:
raise scrapy.exceptions.CloseSpider(error_mess)
else:
raise scrapy.exceptions.CloseSpider(u'服务器错误 HTTP Error 500: Internal Server Error')
def parse(self, response):
from scrapy.shell import inspect_response
inspect_response(response, self)上面的parse函数中,通过如下两句话既可以进入Scrapy shell会话模式:
from scrapy.shell import inspect_response
inspect_response(response, self)这样调试登录之后的界面就比较方便,如果对html的结果不是特别清楚,也可以通过view(response)命令让当前的页面在浏览器中显示,通过浏览器来查看html的源码结构。
2,logging使用
也可以通过logging库进行打印调试,打印你需要显示的内容:
import logging
logging.warning("This is a warning")更多具体的细节可以参考官方文档—Logging
3,打印当前函数名以及行号
自己比较好奇怎么像c语言那样在Python中打印当前函数名和当前行号:
import logging
import inspect
frame = inspect.currentframe()
logging.log(logging.DEBUG, "### FUNC {0} line {1}###".format(__name__, frame.f_lineno))五,总结
这次通过一个简单的例子,两种不同方式对比实现,对Scrapy的创建工程有了一个比较深入的认识,下面一篇文章会深入分析下Scrapy框架中的Spider Middleware,并且自己实现一个。














 1854
1854











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









