







1. 原理示意图


2.伪分布式 安装步骤:
1.准备Linux环境
1.0点击VMware快捷方式,右键打开文件所在位置 -> 双击vmnetcfg.exe -> VMnet1 host-only ->修改subnet ip 设置网段:192.168.1.0 子网掩码:255.255.255.0 -> apply -> ok
回到windows --> 打开网络和共享中心 -> 更改适配器设置 -> 右键VMnet1 -> 属性 -> 双击IPv4 -> 设置windows的IP:192.168.1.100 子网掩码:255.255.255.0 -> 点击确定
在虚拟软件上 --My Computer -> 选中虚拟机 -> 右键 -> settings -> network adapter -> host only -> ok
1.1修改主机名
vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=itcast ###
1.2修改IP
两种方式:
第一种:通过Linux图形界面进行修改(强烈推荐)
进入Linux图形界面 -> 右键点击右上方的两个小电脑 -> 点击Edit connections -> 选中当前网络System eth0 -> 点击edit按钮 -> 选择IPv4 -> method选择为manual -> 点击add按钮 -> 添加IP:192.168.1.101 子网掩码:255.255.255.0 网关:192.168.1.1 -> apply
第二种:修改配置文件方式(屌丝程序猿专用)
vim /etc/sysconfig/network-scripts/ifcfg-eth0
DEVICE="eth0"
BOOTPROTO="static" ###
HWADDR="00:0C:29:3C:BF:E7"
IPV6INIT="yes"
NM_CONTROLLED="yes"
ONBOOT="yes"
TYPE="Ethernet"
UUID="ce22eeca-ecde-4536-8cc2-ef0dc36d4a8c"
IPADDR="192.168.1.101" ###
NETMASK="255.255.255.0" ###
GATEWAY="192.168.1.1" ###
1.3修改主机名和IP的映射关系
vim /etc/hosts
192.168.1.101 itcast
1.4关闭防火墙
#查看防火墙状态
service iptables status
#关闭防火墙
service iptables stop
#查看防火墙开机启动状态
chkconfig iptables --list
#关闭防火墙开机启动
chkconfig iptables off
1.5重启Linux
reboot
2.安装JDK
2.1上传alt+p 后出现sftp窗口,然后put d:\xxx\yy\ll\jdk-7u_65-i585.tar.gz
2.2解压jdk
#创建文件夹
mkdir /home/hadoop/app
#解压
tar -zxvf jdk-7u55-linux-i586.tar.gz -C /home/hadoop/app
2.3将java添加到环境变量中
vim /etc/profile
#在文件最后添加
export JAVA_HOME=/home/hadoop/app/jdk-7u_65-i585
export PATH=$PATH:$JAVA_HOME/bin
#刷新配置
source /etc/profile
3.安装hadoop2.4.1
先上传hadoop的安装包到服务器上去/home/hadoop/
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
伪分布式需要修改5个配置文件
3.1配置hadoop
第一个:hadoop-env.sh
vim hadoop-env.sh
#第27行
export JAVA_HOME=/usr/java/jdk1.7.0_65
export HADOOP_OPTS="-Djava.library.path=$HADOOP_PREFIX/lib:$HADOOP_PREFIX/lib/native"
第二个:core-site.xml
<!-- 指定HADOOP所使用的文件系统schema(URI),HDFS的老大(NameNode)的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://weekend-1206-01:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.4.1/tmp</value>
</property>
第三个:hdfs-site.xml hdfs-default.xml (3)
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
第四个:mapred-site.xml (mv mapred-site.xml.template mapred-site.xml)
mv mapred-site.xml.template mapred-site.xml
vim mapred-site.xml
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
第五个:yarn-site.xml
<!-- 指定YARN的老大(ResourceManager)的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>weekend-1206-01</value>
</property>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
3.2将hadoop添加到环境变量
vim /etc/proflie
export JAVA_HOME=/usr/java/jdk1.7.0_65
export HADOOP_HOME=/itcast/hadoop-2.4.1
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
source /etc/profile
错误: hadoop “util.NativeCodeLoader: Unable to load native-hadoop library for your platform”
首先下载hadoop-native-64-2.4.0.tar:
http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.4.0.tar
如果你是hadoop2.6的可以下载下面这个:
http://dl.bintray.com/sequenceiq/sequenceiq-bin/hadoop-native-64-2.6.0.tar
下载完以后,解压到hadoop的native目录下,覆盖原有文件即可。
3.3格式化namenode(是对namenode进行初始化)
hdfs namenode -format (hadoop namenode -format)
3.4启动hadoop
先启动HDFS
sbin/start-dfs.sh
再启动YARN
sbin/start-yarn.sh
3.5验证是否启动成功
使用jps命令验证
27408 NameNode
28218 Jps
27643 SecondaryNameNode
28066 NodeManager
27803 ResourceManager
27512 DataNode
http://192.168.1.101:50070 (HDFS管理界面)
http://192.168.1.101:8088 (MR管理界面)
4.配置ssh免登陆
#生成ssh免登陆密钥
#进入到我的home目录
cd ~/.ssh
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上
ssh-copy-id localhost
3. hdfs shell
1.0查看帮助
hadoop fs -help <cmd>
1.1上传
hadoop fs -put <linux上文件> <hdfs上的路径>
1.2查看文件内容
hadoop fs -cat <hdfs上的路径>
1.3查看文件列表
hadoop fs -ls /
1.4下载文件
hadoop fs -get <hdfs上的路径> <linux上文件>http://download.csdn.net/detail/xj626852095/9631682
4. namenode 和 secondnamenode
NameNode是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件。
fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中。
NameNode的工作特点:
Namenode始终在内存中保存metedata,用于处理“读请求”
到有“写请求”到来时,namenode会首先写editlog到磁盘,即向edits文件中写日志,成功返回后,才会修改内存,并且向客户端返回
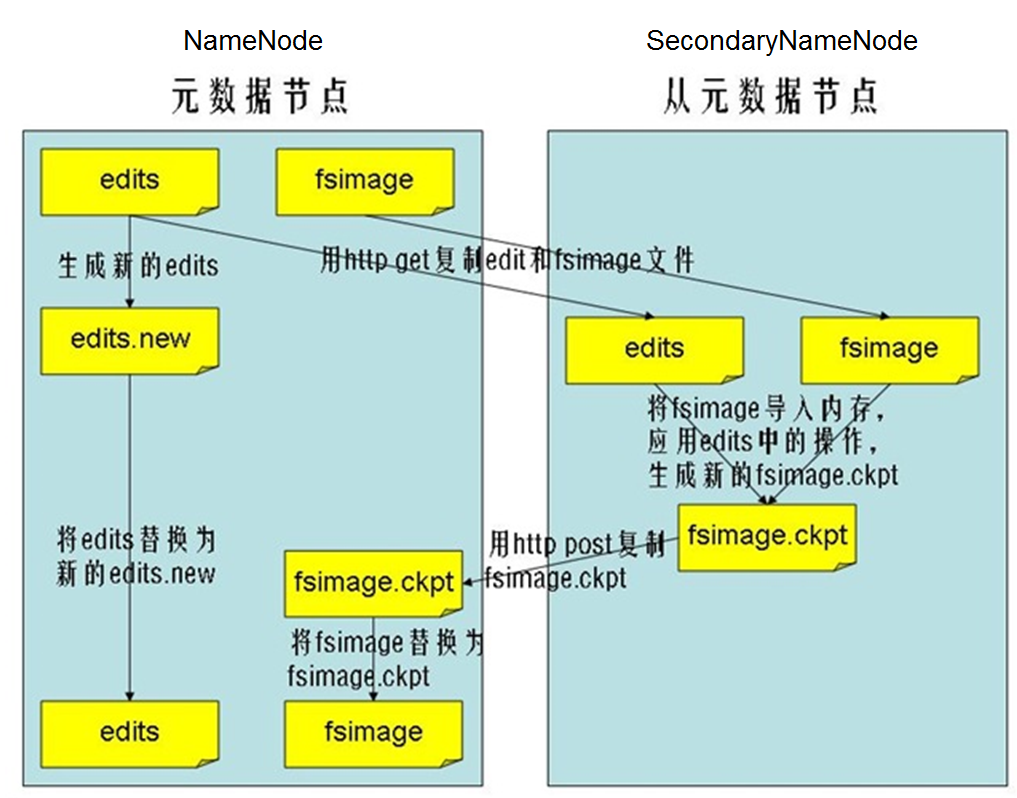
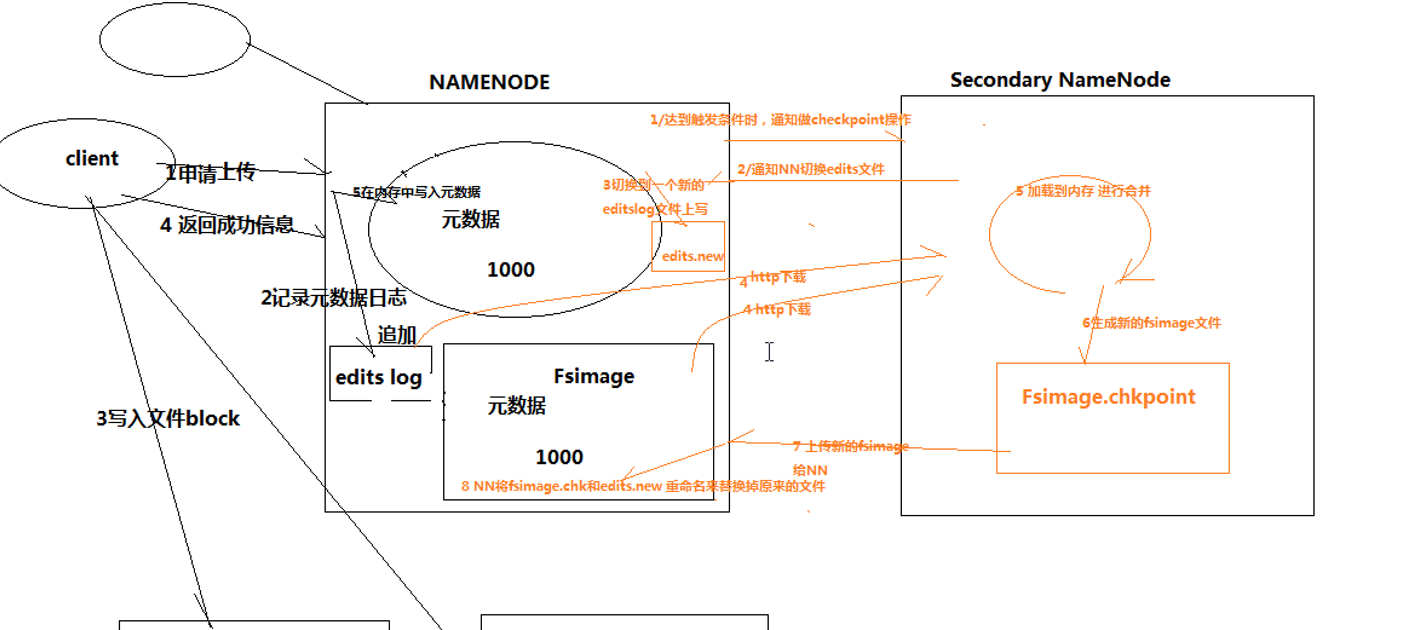
Hadoop会维护一个fsimage文件,也就是namenode中metedata的镜像,但是fsimage不会随时与namenode内存中的metedata保持一致,而是每隔一段时间通过合并edits文件来更新内容。Secondary namenode就是用来合并fsimage和edits文件来更新NameNode的metedata的。
SecondaryNameNode:
HA的一个解决方案。但不支持热备。配置即可。
执行过程:从NameNode上下载元数据信息(fsimage,edits),然后把二者合并,生成新的fsimage,在本地保存,并将其推送到NameNode,替换旧的fsimage.
默认在安装在NameNode节点上,但这样...不安全!
secondary namenode的工作流程:
1.secondary通知namenode切换edits文件
2.secondary从namenode获得fsimage和edits(通过http)
3.secondary将fsimage载入内存,然后开始合并edits
4.secondary将新的fsimage发回给namenode
5.namenode用新的fsimage替换旧的fsimage
什么时候checkpiont:
fs.checkpoint.period 指定两次checkpoint的最大时间间隔,默认3600秒。
fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔。默认大小是64M。
5. java api 操作hdfs
windows下开发hadoop代码需要配置hadoop环境已经,并设置 HADOOP_HOME变量,
还需要替换hadoop安装环境的包
http://download.csdn.net/detail/xj626852095/9633241
package com.kevin.hadoopdemo;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test;
public class HdfsDemo {
private FileSystem fs = null;
private String BASE_DIR= "hdfs://192.168.1.108:9000/";
@Before
public void getFs() throws IOException{
//get a configuration object
Configuration conf = new Configuration();
//to set a parameter, figure out the filesystem is hdfs
conf.set("fs.defaultFS", BASE_DIR);
conf.set("dfs.replication","1");
//get a instance of HDFS FileSystem Client
fs = FileSystem.get(conf);
}
@Test
public void testUpload() throws IOException{
//open a outputstream of the dest file
Path destFile = new Path(BASE_DIR+"1.txt");
FSDataOutputStream os = fs.create(destFile);
//open a inputstream of the local source file
FileInputStream is = new FileInputStream("F:/temp/1.txt");
//write the bytes in "is" to "os"
IOUtils.copy(is, os);
}
@Test
public void testCopyLocal() throws Exception{
fs.copyFromLocalFile(new Path("F:/temp/top500.htm"), new Path("/top500.html"));
}
@Test
public void testDownload() throws Exception{
FSDataInputStream is = fs.open(new Path( BASE_DIR + "1.txt" ));
FileOutputStream os = new FileOutputStream("F:/temp/1_down.txt");
IOUtils.copy(is, os);
}
@Test
public void testRmfile() throws IllegalArgumentException, IOException {
boolean res = fs.delete(new Path("/top500.html"), true);
System.out.println(res?"delete is successfully :)":"it is failed :(");
}
@Test
public void testMkdir() throws IllegalArgumentException, IOException{
fs.mkdirs(new Path("/aa/bb"));
}
@Test
public void testRename() throws IllegalArgumentException, IOException{
fs.rename(new Path("/1.txt"), new Path("/1_copy.txt"));
}
@Test
public void testListFiles() throws FileNotFoundException, IllegalArgumentException, IOException{
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
while(listFiles.hasNext()){
LocatedFileStatus file = listFiles.next();
System.out.println(file.getPath().getName());
}
System.out.println("--------------------------------------------");
FileStatus[] status = fs.listStatus(new Path("/"));
for(FileStatus file: status){
System.out.println(file.getPath().getName() + " " + (file.isDirectory()?"d":"f"));
}
}
}

















 5808
5808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









