







性能测试
性能测试
公司最近新开通了一项业务,随着新系统的上线日期日益临近系统的性能需求也逐渐提上了日程,于是趁着事情逼到头上的动力,把之前落下的知识恶补了一番。由于大部分内容都是取经自刘老师(顺便做个广告,有想学习测试知识的同学可以联系我,介绍刘老师给你们认识,绝对物超所值!!),所以虽然是自己一个字一个字打出来的,但也已不能算做原创,就归类于转载了。
本文主要分为两大部分,第一部分是性能测试从概念、到需求、到实行、到结果分析的全流程;第二部分是对于一些必用命令的详细解析,也是转发于别的博主,做了一下重新编辑。
很多内容都是浅尝辄止,算是入门系列吧,深入挖掘的话还需要很多知识,提醒自己继续努力学习!
基本概念
-
定义:性能测试是针对系统的性能指标,建立性能测试模型,制定性能测试方案,制定监控策略,在场景条件之下执行性能场景,分析判断性能瓶颈并调优,最终得出性能结果来评估系统的性能指标是否满足既定值
-
1个虚拟用户就是一个线程,但这一个线程1s 内可以有多个请求,即多个 tps
常用系统监控命令
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IWAMixD4-1590740598837)(media/15873520228307/15892839081244.jpg)]](https://img-blog.csdnimg.cn/20200529171831599.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hqaWFuMzIxMjM=,size_16,color_FFFFFF,t_70)
如何计算性能指标(上游数据)
-
由业务方提供运营数据,如活跃用户数等
-
通过日志平台分析
-
性能测试报告:
- 性能需求指标:时间指标、容量指标、资源利用率指标
- 性能模型:业务模型、监控模型
- 性能方案:测试环境、测试数据、测试模型、性能指标、压力策略、准入准出、进度风险
- 性能监控:系统架构、系统监控、中间件监控、缓存监控、队列监控、负载均衡监控、熔断限流、链路监控…
- 性能场景执行:基准场景、容量场景、稳定性场景
- 性能报告/结果:场景结果整理、监控结果整理、性能整体分析、性能结论、优化建议、运维建议
-
主要监控的资源:系统资源(内存、CPU、磁盘 IO、网络)、数据库、tomcat 等 web 服务器、缓存、队列、jvm
性能指标
| 简写 | 英文全称 | 简介 |
|---|---|---|
| RT | Response Time | 响应时间,通常我们说的响应时间,都是包括了 Request Time 和 Response Time ☆☆☆☆☆ |
| HPS | Hits Per Second | 每秒点击数(不重要) |
| TPS | Transactions Per Second | 每秒事务数 ☆☆☆☆☆ |
| QPS | Queries Per Second | 在 MySQL 中指每秒 SQL 数 |
| RPS | Requests Per Second | 每秒请求数 |
| PV | Page View | 页面浏览量 |
| UV | Unique Visitor | 独立访问者 |
| Throughput | ≈ TPS | 吞吐量,代表系统处理事务的能力,可以描述系统承受了多少压力 ☆☆☆☆☆ |
| IOPS | Input/Output Operations Per Second | 通常描述磁盘 |
业务指标
例:峰值100万用户在线
场景1业务比例:业务1 20%、业务2 30% ……
场景2业务比例:业务1 5%、业务2 30% ……
技术指标
-
时间指标:接口响应时间、业务响应时间
-
容量指标:接口容量、业务容量
-
资源利用率指标:操作系统、JVM
性能测试场景关心的指标
TPS、响应时间、线程数(线程的增长趋势)
如何计算TPS
- Jmeter等工具定义的如何计算TPS:
单位时间内成功发送的请求数(事务数) / 单位时长
例:2分钟内,所有的线程发了1000个请求(成功的),那么TPS即:1000/120=8.3
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qmvR57DO-1590740598841)(media/15873520228307/15873904409124.jpg)]](https://img-blog.csdnimg.cn/20200529171805829.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hqaWFuMzIxMjM=,size_16,color_FFFFFF,t_70)
- 目标TPS = 线程数 / 平均响应时间
例:10个线程,平均响应时间是0.2s,那么TPS应该是多少?
平均时间是0.2s,那么1个线程1s内的处理事务数为1/0.2s=5个,则10个线程是10×5=50,TPS就是50
- 根据TPS、响应时间,如何计算线程数?
例:目标TPS是100,响应时间是0.5s
响应时间是0.5s,那么就是1s可以发送2个请求,所以100/2=50个线程数
- 线程数 ≠ 用户数 ≠ 并发数
- 综上所述,响应时间是必须的关键参数,决定了可以发出了多大的TPS,性能测试中设置延时就是为了稳定的控制TPS,如设置jmeter中的调度器–启动延时,或者逻辑控制器中其他组件
如何根据活跃用户数、在线用户数计算TPS
- 假如在线用户10000,但这10000个用户并不会同时产生压力,那么按照业内标准,并发度约为3%~5%,即每秒产生500个业务请求(500TPS)。假如响应时间是100ms,那么并发线程数需要50。但因为响应时间并不是一个恒定值,随着压力的上升,响应时间会随之上升,所以应该关注趋势的变化,而不是某个时间点的值(除非是某个特殊点时突然上升或下降)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dNbigHXj-1590740598842)(media/15873520228307/15875394377656.jpg)] - 性能衰减的标志就是响应时间上升,TPS下降
性能监控–CPU部分
-
用到的工具:
-
本地/服务器的探测器,监控系统信息
-
使用Prometheus对探测到的信息进行监控
-
使用grafana进行美化展示,或者展示Jmeter的压测结果
-
使用influxDB存储jmeter的压测结果(influxDB:时序型数据库)
-
-
性能监控数据分析
-
资源利用率饱和后,TPS不会马上衰减
-
大部分情况下响应时间不会出现陡增,更可能会提前增长
-
有的控制较好的系统不会出现TPS下降,到达瓶颈后会维持TPS,或者由于响应时间本身较短,看不到TPS明星的下降
-
最优并发数通常不可信,谨慎起见应该提前
-
用户增长了不代表压力一定会线性增长,资源也不一定就持续往上涨
-
加压策略
-
同时加压
-
指定间隔时间加压
-
梯度加压策略
例如使用30TPS压测2分钟,再使用40TPS压测2分钟,再使用50TPS加压。
需要注意的是在梯度加压过程中,需要连续的进行,不能中断
具体实施过程
1. 确定业务场景模型
-
比如确定登陆—查询—添加购物车等操作场景
-
确定用户数据,如10000在线用户数,那么按照5%的并发度计算,得到500TPS,而单登陆接口的TPS约为50
-
实施单交易基准测试,确定平均基准响应时间
使用1线程,运行5分钟,得到平均响应时间
按照上面的业务模型(单登陆接口 TPS 50),假如平均响应时间是0.2s,那么可以得到最优线程数为10(是理想值,实际比10小)。
2. 确定单交易容量
-
目的:根据三条曲线(TPS、响应时间、线程数)确定最大TPS、最优响应时间、最大响应时间(TPS衰减前的最大响应时间,非E)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qSvHuy5b-1590740598843)(media/15873520228307/15880553979651.jpg)]](https://img-blog.csdnimg.cn/20200529171742174.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hqaWFuMzIxMjM=,size_16,color_FFFFFF,t_70)
A:最优响应时间
B:业务指标点、业务响应时间点
C:最大TPS下的响应时间
D:业务可以接受的最大响应时间,系统资源利用率最大化
最大化
E:最大响应时间,错误(超时)之前的最大时间 -
为什么确定这些指标点?评估系统整体动态情况
3. 混合场景测试
-
业务组合场景:
-
首页—登陆
-
登陆—首页
-
页面—登陆—首页
-
-
分别对不同场景进行测试,均要确定最大TPS、最优响应时间、最大响应时间
-
混合场景的容量测试要比单基准测试的结果略低,如更小的TPS、更大的响应时间
4. 其他场景
-
稳定性测试:长时间压测的情况下,是否发现有性能衰减的情况
-
异常场景测试:如突然增大TPS后的处理情况
稳定性测试
- 注意内容
-
贴近业务场景
-
梯度加压,假如进行10小时测试,可以考虑20分钟内线程数加满,之后的要保持TPS稳定测试
-
关注业务量累计
-
TPS一定要稳定,不能产生大的波动,具体多少TPS,需要团队内达成共识
-
实际项目分析
业务场景
| 业务序号 | 业务名称 |
|---|---|
| 01 | 登录 |
| 02 | 退出 |
| 03 | 购票 |
| 04 | 兑奖查询 |
| 05 | 兑奖 |
在线用户数10000,并发度5%,TPS=500
| 场景序号 | 场景分类 | 业务 | 说明 |
|---|---|---|---|
| 1 | 基准场景 | 业务1 | 单交易基准(平均响应时间)、单交易容量(TPS) |
| 2 | 基准场景 | 业务2 | 单交易基准(平均响应时间)、单交易容量(TPS) |
| 3 | 基准场景 | 业务3 | 单交易基准(平均响应时间)、单交易容量(TPS) |
| 4 | 基准场景 | 业务4 | 单交易基准(平均响应时间)、单交易容量(TPS) |
| 5 | 基准场景 | 业务5 | 单交易基准(平均响应时间)、单交易容量(TPS) |
| 6 | 容量测试 | 业务模型1 | 登陆 —> 退出 |
| 7 | 容量场景 | 业务模型2 | 登录 —> 购票 —> 退出 |
| 8 | 容量场景 | 业务模型3 | 登陆 —> 兑奖 —> 退出 |
| 9 | 稳定性场景 | 业务模型1 | |
| 10 | 稳定性场景 | 业务模型2 | |
| 11 | 异常场景 | 业务模型1: 操作1 操作2 操作3 | 操作:如宕机等情况 |
| 12 | 异常场景 | 业务模型2 操作1 操作2 操作3 | |
| 13 | 异常场景 | 业务场景3 操作1 操作2 操作3 |
基准场景(以普通日为例)
| 业务序号 | 业务名称 | 比例 | TPS |
|---|---|---|---|
| 01 | 登录 | 1.5% | 8 |
| 02 | 退出 | 1% | 5 |
| 03 | 购票 | 60% | 300 |
| 04 | 兑奖查询 | 21.8% | 109 |
| 05 | 兑奖 | 8.7% | 44 |
实际
- 全链路监控:skywalking
https://blog.csdn.net/coolcoffee168/article/details/91441942?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-5
https://www.cnblogs.com/swave/p/11347711.html
https://www.jianshu.com/p/2fd56627a3cf
性能分析
Linux知识
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qLF4a1uL-1590740598844)(media/15873520228307/15889289905971.jpg)]](https://img-blog.csdnimg.cn/20200529171725760.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hqaWFuMzIxMjM=,size_16,color_FFFFFF,t_70)
需要监控的资源
- CPU
-
进程在系统中的状态:
-
运行态(runnable/running):占有处理器正在运行
-
等待态(blocked 阻塞态):不具备运行条件,正在等待某个事件的完成
-
就绪态(Ready):具备运行条件,等待系统分配处理器以便运行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-74Q3MQ7J-1590740598845)(media/15873520228307/15889318175348.jpg)]
-
-
需要监控的指标
- CPU利用率(CPU Utilization):Utilization = work_time / total_time
-
load average与CPU占用率的关系
-
平均负载低、CPU占用率高:需要排查CPU占用高的进程是什么,原因是什么
-
平均负载低、CPU占用率低:正常,不是繁忙状态
-
平均负载高、CPU占用率高:计算密集型,任务繁重,有可能有问题,需要排查具体占用的任务
-
平均负载高、CPU占用率低:需要排查iOwait、网络开销等其他问题,问题原因和CPU无关
-
-
| CPU参数 | 描述 | 备注 |
|---|---|---|
| us | 用户使用的CPU,非Linux进程 | |
| sy | 系统CPU占用 | |
| id | 空闲CPU | |
| wa | IO等待,CPU在等待iO读写占用的时间,此时进程不可中断状态 | ★★ 如果TPS上不去,整体CPU占用不高,但wa很高 说明瓶颈在iO读写方面 |
| hi | 硬中断,如果该值较高,说明硬件可能出现问题 | |
| si | 软中断,上下文切换如果过于频繁,会导致CPU在寄存器和运行队列直接频繁切换 更多的时间消耗在了线程切换,而不是真正的工作 原因:任务调度、软硬件中断 | |
| st | steal time,其他宿主机在占用当前主机的CPU | 如果云主机该值较高说明是公用CPU |
| load average | 系统平均负载,分别为1分钟,5分钟,15分钟之内等待CPU运行的进程数 | ★★ |
| Task参数 | 描述 | 备注 |
|---|---|---|
| total | 总进程 | |
| sleeping | 等待进程 | |
| stopped | 停止进程 | |
| zombie | 僵尸进程 | 需要关注,如果较多也会影响系统性能 |
-
Linux服务器中小型压力测试工具
-
安装
yum install stress -
使用方法:
-t --timeout N 指定运行N秒后停止
-c 产生n个进程 每个进程都反复不停的计算随机数的平方根,模拟计算密集型任务
-i 产生n个进程 每个进程反复调用sync(),sync()用于将内存上的内容写到硬盘上,模拟iO密集型任务- 实例:
# 启用5个进程进行计算,执行180秒 stress -t 180 -i 5 # 启用5个进程进行写内容,执行180秒 stress -t 180 -c 5
-
具体原因分析
-
通过上述方法监测CPU信息后,大概判断出问题方向
-
跟踪CPU占用信息,继续追踪有问题的pid
# 查询<pid>的具体信息,每秒刷新1次
pidstat -p <pid> 1
# 继续追踪有问题的进程的子进程
top -Hp <pid>
-
获取到有问题的进程号后,继续追踪jvm栈信息
-
jstack 方式
[root@apollo-test-env ~]# top [root@apollo-test-env ~]# ps -mp 9066 -o THREAD,tid,time USER %CPU PRI SCNT WCHAN USER SYSTEM TID TIME root 0.8 - - - - - - 03:31:01 root 0.0 19 - futex_ - - 9066 00:00:00 root 0.0 19 - futex_ - - 9067 00:00:01 root 0.0 19 - futex_ - - 9068 00:00:33 root 0.0 19 - futex_ - - 9069 00:00:33 # 转为16进制 [root@apollo-test-env ~]# printf "%x\n" 9066 236a # jstack <pid> |grep <tid(16进制)> -A 30 [root@apollo-test-env ~]# jstack 9066 |grep 236a -A 30 -
使用 jvisualvm+jmx 工具,是jdk自带的可视化监控工具
-
Arthas
-
github下载
wget https://alibaba.github.io/arthas/arthas-boot.jar
-
-
证据链追踪过程
-
首先使用20线程进行压测,发现最大到20TPS之后就无法继续提升
-
使用top命令查询,结论:CPU占用95%、wa=0、us=93%、sy=2%、load average 5~8,且持续增加、si、cs正常
-
使用vmstat命令,r 堆积很高,b=0
-
上述过程得出结论:是属于计算密集型任务导致的CPU占用率高的问题
-
继续使用命令
top -Hp <pid>发现子进程的平均占用就很高 -
使用arthas工具,追踪上一步占用高的子进程pid到jvm栈以及具体代码行数
-
性能监控–内存部分
-
内存定义
-
操作系统在使用物理内存之前,需要进行分页(pages),将内存分为一页一页的,这就是虚拟内存(VMM虚拟内存管理器)的概念。
-
虚拟内存段划分为固定大小的单元,这种单元叫做页,缺省值页面大小为4096(4kb)字节
-
SWAP(交换分区):当物理内存用完后,会将磁盘空间(SWAP分区)虚拟成内存来使用。访问速度远慢于实际内存的访问速度,尽量避免使用该部分
-
常用命令:
[root@ecs-x-medium-2-linux-20200220101336 ~]# sysctl -a |grep swappiness # 表示系统swap分区的权重,当内存使用率达到(100%-vm.swappiness)时,就会发生swap vm.swappiness = 0 # 表示当内存使用小于 vm.min_free_kbytes 时会发生swap [root@ecs-x-medium-2-linux-20200220101336 ~]# sysctl -a |grep vm.min_free vm.min_free_kbytes = 45056 # 关闭swap swapoff -a
-
-
Buffer(缓冲区):当应用程序需要写数据到磁盘时,耗时会比较长,系统会将这些数据暂时保存在内存中,程序继续执行其他操作
-
cache(缓存区)
-
available值,才是真是可用内存,计算了free以及buffers、cache中不用的内存
-
-
内存问题分析
-
使用命令dmesg可以查看到系统的日志记录
-
当出现内存泄露或因其他原因导致物理内存不够用的时候,操作系统就会调用OOM Killer,这个进程会强制杀死消耗内存大的应用。这个过程是不商量的,所以如果在内存监控图中发下如下情况,即可能出现了这种情况,使用
dmesg命令进行查询
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SNPfJ7bp-1590740598846)(media/15873520228307/15893610349872.jpg)]](https://img-blog.csdnimg.cn/20200529171604575.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hqaWFuMzIxMjM=,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-lZW59U4O-1590740598847)(media/15873520228307/15894364214615.jpg)]](https://img-blog.csdnimg.cn/202005291716124.png)
[763946.339749] Out of memory: Kill process 5870 (vim) score 383 or sacrifice child [763946.340717] Killed process 5870 (vim) total-vm:6564716kB, anon-rss:6415572kB, file-rss:140kB, shmem-rss:0kB -
获得如上述进程号后(process 5870)后,可以通过arthas或者jstack等工具继续分析该进程的堆内存信息
-
性能监控–网络部分
三次握手过程分析(建立链接)
-
tcp建立链接的三次握手,需要关注的是半连接队列、accept队列(全连接队列)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yPEAUhzt-1590740598847)(media/15873520228307/15895277394117.jpg)]](https://img-blog.csdnimg.cn/20200529171538891.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hqaWFuMzIxMjM=,size_16,color_FFFFFF,t_70)
-
如上图所示,如果在半连接队列、全连接队列过程中即发生问题,那么就未进入到接收发送数据的步骤,所以需要监控半连接、全连接溢出问题,SYN丢包
-
查询半连接使用命令:
[root@apollo-test-env ~]# netstat -s |grep -i listen # 发生了 348877 次监听队列溢出问题(全连接连接队列溢出) 348877 times the listen queue of a socket overflowed # 发生了 349226 次的监听丢包问题 349226 SYNs to LISTEN sockets dropped- 所以如果在压测过程中,发现SYNs值在上涨,那么说明半连接队列溢出
-
半连接参数:
-
代码中的backlog:比如ServerSocket(int port, int backlog)中的backlog。它就是半连接的队列长度,如果它不够了,就会丢掉syn包了
-
操作系统的内核参数net.ipv4.tcp_max_syn_backlog
-
-
查询全连接队列溢出使用命令:
[root@apollo-test-env ~]# netstat -s |grep -i overflow 348877 times the listen queue of a socket overflowed TCPTimeWaitOverflow: 264563
四次挥手过程分析(断开链接)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NCoCE13z-1590740598848)(media/15873520228307/15895326768820.jpg)]](https://img-blog.csdnimg.cn/20200529171502886.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hqaWFuMzIxMjM=,size_16,color_FFFFFF,t_70)
- 在四次挥手过程中,需要关注的问题点:TIME_WAIT
-
在链接断开后,端口不会立刻被释放,而是处于 TIME_WAIT 状态,具体等待时间(默认60s)可以查看:
[root@apollo-test-env ~]# cat /proc/sys/net/ipv4/tcp_fin_timeout
-
60
```
- TIME_WAIT 一般不需要修改,只有当端口不够用(最大65535)的时候需要修改该值,让占用的端口尽快释放掉。所以,当性能测试过程中发现TPS无法提高、响应时间很短,且其他原因都已经排查过后,可以考虑适当改小 TIME_WAIT 值
具体方案
-
监控命令
netstat | more[root@apollo-test-env ~]# netstat|more Active Internet connections (w/o servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 0 apollo-test-env:20880 apollo-test-env:36206 ESTABLISHED tcp 0 0 apollo-test-:scp-config 172.17.202.75:58896 ESTABLISHED tcp 0 0 apollo-test-env:47832 test.influencer.c:https TIME_WAIT tcp 0 0 apollo-test-env:36920 apollo-test-env:mysql ESTABLISHED tcp 0 0 localhost:59542 localhost:XmlIpcRegSvc ESTABLISHED tcp 0 0 apollo-test-en:eforward 47.56.231.2:59156 ESTABLISHED tcp 0 0 apollo-test-env:59170 apollo-test-env:mysql ESTABLISHED tcp 0 0 apollo-test-env:20883 apollo-test-env:48844 ESTABLISHED tcp 0 0 apollo-test-en:eforward 182.48.99.226:15607 ESTABLISHED tcp 0 0 apollo-test-env:60904 apollo-test-env:6379 ESTABLISHED tcp 0 0 apollo-test-env:18085 172.17.202.75:58426 TIME_WAIT tcp 0 1 apollo-test-env:54192 192.168.8.147:20880 SYN_SENT -
命令结果的字段含义:
-
Proto:协议,有tcp、udp
-
Recv-Q:接收队列
-
Send-Q:发送队列
-
Local Address:本地地址
-
Foreign Address:远端地址
-
State:连接状态
-
-
问题分析
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yhr1r8ln-1590740598848)(media/15873520228307/15895374411496.jpg)]](https://img-blog.csdnimg.cn/20200529171057104.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hqaWFuMzIxMjM=,size_16,color_FFFFFF,t_70)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PwJED8XO-1590740598849)(media/15873520228307/15895374468273.jpg)]](https://img-blog.csdnimg.cn/20200529171445517.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3hqaWFuMzIxMjM=,size_16,color_FFFFFF,t_70)
-
网络问题使用的详细命令
[root@apollo-test-env ~]# netstat -naep|more Active Internet connections (servers and established) Proto Recv-Q Send-Q Local Address Foreign Address State User Inode PID/Program name tcp 0 0 0.0.0.0:2088 0.0.0.0:* LISTEN 0 579207238 32743/java tcp 0 0 0.0.0.0:2089 0.0.0.0:* LISTEN 0 579207381 32743/java tcp 0 0 0.0.0.0:873 0.0.0.0:* LISTEN 0 23478620 23929/rsync tcp 0 0 0.0.0.0:8009 0.0.0.0:* LISTEN 0 68056 7541/java tcp 0 0 0.0.0.0:2090 0.0.0.0:* LISTEN 0 579207346 32743/java tcp 0 0 0.0.0.0:34412 0.0.0.0:* LISTEN 0 636103083 9066/java tcp 0 0 0.0.0.0:22222 0.0.0.0:* LISTEN 0 781137647 6362/java tcp 0 0 0.0.0.0:36590 0.0.0.0:* LISTEN 0 636102319 9066/java tcp 0 0 0.0.0.0:9998 0.0.0.0:* LISTEN 0 514706982 29197/java tcp 0 0 0.0.0.0:29999 0.0.0.0:* LISTEN 0 131257416 18281/java tcp 0 0 0.0.0.0:9999 0.0.0.0:* LISTEN 0 68055 7541/java tcp 0 0 0.0.0.0:20880 0.0.0.0:* LISTEN 0 758252129 15915/java tcp 0 0 0.0.0.0:20881 0.0.0.0:* LISTEN 0 781138256 6362/java tcp 0 0 0.0.0.0:10001 0.0.0.0:* LISTEN 0 758254791 15915/java-
netstat -naep 命令详解:
-a:显示所有选项,默认不显示Listen相关
-t:(tcp)仅显示tcp相关选项
-u:(udp)仅显示udp相关选项
-n:拒绝显示别名,能显示数字的全部转化成数字
-l:仅列出有在Listen的服务状态
-p:显示建立相关链接的程序名
-r:显示路由信息,路由表
-e:显示扩展信息,例如uid等
-s:按各个协议进行统计
-c:每隔一个固定时间,执行该命令 -
iftop命令:
- 安装:
yum install iftop
- 安装:
-
ifstat命令
-
-
如何计算带宽
-
定义:
100M宽带代表每秒可以发送100m比特位数据(100Mbps)
1个字节是8位(1字节=8比特(1B=8bit或者1B=8b);1字节/秒=8比特/秒(1B/s=8bps)),那么100M代表每秒可以发送100/8=12.5m数据 -
举例:假如有1000m宽带,每个请求40kb,不考虑其他瓶颈的话,TPS可以达到多少?
计算:1000m宽带,每秒可以发送125m数据,125*1024=128000 kb,128000/40=3200,所以TPS可以为3200(理论值)
-
和
iftop命令结合:- 假如5m带宽,计算得到5/8=625kb/s,所以每秒可以发送或接收625kb数据,通过iftop命令查看每秒的数据,如果接近625,说明带宽可能存着瓶颈
-
补充内容
top命令输出解释以及load average 详解
原文地址
load average获取方式
- top
- uptime
20:34:40 up 241 days, 23:46, 1 user, load average: 0.03, 0.11, 0.13
- w
20:34:30 up 241 days, 23:46, 1 user, load average: 0.03, 0.12, 0.13
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 182.48.99.226 20:14 6.00s 0.02s 0.00s w
- cat /proc/loadavg
0.08 0.14 0.14 1/2081 6999
前三个数字是1、5、15分钟内的平均进程数。后面的 1/2081 分子是正在运行的进程数,分母是进程总数;另一个是最近运行的进程ID号。
什么是load average
定义
在特定时间间隔内运行队列中(在CPU上运行或者等待运行多少进程)的平均进程数。
解释
我们可以这样认为,就是正在运行的进程 + 准备好等待运行的进程 在特定时间内(1分钟,5分钟,15分钟)的平均进程数
进程可运行状态时,它处在一个运行队列run queue中,与其他可运行进程争夺CPU时间。 系统的load是指正在运行running one和准备好运行runnable one的进程的总数。比如现在系统有2个正在运行的进程,3个可运行进程,那么系统的load就是5,load average就是一定时间内的load数量均值`
比喻
把CPU比喻成一条(单核)马路,进程任务比喻成马路上跑着的汽车,Load则表示马路的繁忙程度:
-
Load小于1:表示完全不堵车,汽车在马路上跑得游刃有余:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GXS3epTt-1590742974453)(media/15889411765970/15889418222943.jpg)]](https://img-blog.csdnimg.cn/20200529170910814.png)
-
Load等于1:马路已经没有额外的资源跑更多的汽车了:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vDwfGB3E-1590742974455)(media/15889411765970/15889418568433.jpg)]](https://img-blog.csdnimg.cn/20200529170920480.png)
-
Load大于1:汽车都堵着等待进入马路:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zjHyInHd-1590742974457)(media/15889411765970/15889418745808.jpg)]](https://img-blog.csdnimg.cn/20200529170929342.png)
-
如果有两个CPU,则表示有两条马路,此时即使Load大于1也不代表有汽车在等待:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IwpLwAdz-1590742974458)(media/15889411765970/15889418929835.jpg)]](https://img-blog.csdnimg.cn/20200529170936816.png)
什么样的load average值得警惕(单核)
-
Load < 0.7时:系统很闲,马路上没什么车,可以考虑多部署一些服务
-
0.7 < Load < 1时:系统状态不错,马路可以轻松应对
-
Load == 1时:系统马上要处理不多来了,赶紧找一下原因
-
Load > 5时:马路已经非常繁忙了,进入马路的每辆汽车都要无法很快的运行
多核CPU如何计算
多核CPU的话,满负荷状态的数字为 “1.00 * CPU核数”,即双核CPU为2.00,四核CPU为4.00
三个Load值要先看哪一个
结合具体情况具体分析:
-
1分钟Load>5,5分钟Load<1,15分钟Load<1:短期内繁忙,中长期空闲,初步判断是一个“抖动”,或者是“拥塞前兆”
-
1分钟Load>5,5分钟Load>1,15分钟Load<1:短期内繁忙,中期内紧张,很可能是一个“拥塞的开始”
-
1分钟Load>5,5分钟Load>5,15分钟Load>5:短中长期都繁忙,系统“正在拥塞”
-
1分钟Load<1,5分钟Load>1,15分钟Load>5:短期内空闲,中长期繁忙,不用紧张,系统“拥塞正在好转”
CPU利用率和Load Average的区别
-
CPU利用率在过去常常被我们这些外行认为是判断机器是否已经到了满负荷的一个标准,看到50%-60%的使用率就认为机器就已经压到了临界了。CPU利用率,顾名思义就是对于CPU的使用状况,这是对一个时间段内CPU使用状况的统计,通过这个指标可以看出在某一个时间段内CPU被占用的情况,如果被占用时间很高,那么就需要考虑CPU是否已经处于超负荷运作,长期超负荷运作对于机器本身来说是一种损害,因此必须将CPU的利用率控制在一定的比例下,以保证机器的正常运作。
-
Load Average是CPU的Load,它所包含的信息不是CPU的使用率状况,而是在一段时间内CPU正在处理以及等待CPU处理的进程数之和的统计信息,也就是CPU使用队列的长度的统计信息。
Linux下区分物理CPU、逻辑CPU和CPU核数
原文地址
概念
-
物理CPU:
实际Server中插槽上的CPU个数。物理cpu数量,可以数不重复的 physical id 有几个 -
逻辑CPU:
/proc/cpuinfo 这个文件用来存储cpu硬件信息,一般情况,我们认为一颗cpu可以有多核,加上intel的超线程技术(HT), 可以在逻辑上再分一倍数量的cpu core出来
逻辑CPU数量 = 物理cpu数量 x cpu cores 这个规格值 x 2(如果支持并开启HT)
ps:Linux下top查看的CPU也是逻辑CPU个数 -
CPU核数:
一块CPU上面能处理数据的芯片组的数量、比如现在的i5 760,是双核心四线程的CPU、而 i5 2250 是四核心四线程的CPU。
一般来说,物理CPU个数×每颗核数=逻辑CPU的个数,如果不相等的话,则表示服务器的CPU支持超线程技术
查看CPU基本信息
- 可以查看/proc/cpuinfo文件
cat /proc/cpuinfo
- 基本信息
vendor id:如果处理器为英特尔处理器,则字符串是 GenuineIntel。
processor:包括这一逻辑处理器的唯一标识符。
physical id:包括每个物理封装的唯一标识符。
core id:保存每个内核的唯一标识符。
siblings:列出了位于相同物理封装中的逻辑处理器的数量。
cpu cores:包含位于相同物理封装中的内核数量。
-
拥有相同 physical id 的所有逻辑处理器共享同一个物理插座,每个 physical id 代表一个唯一的物理封装。
-
Siblings 表示位于这一物理封装上的逻辑处理器的数量,它们可能支持也可能不支持超线程(HT)技术。
-
每个 core id 均代表一个唯一的处理器内核,所有带有相同 core id 的逻辑处理器均位于同一个处理器内核上。简单的说:“siblings”指的是一个物理CPU有几个逻辑 CPU,”cpu cores“指的是一个物理CPU有几个核。
-
如果有一个以上逻辑处理器拥有相同的 core id 和 physical id,则说明系统支持超线程(HT)技术。
-
如果有两个或两个以上的逻辑处理器拥有相同的 physical id,但是 core id不同,则说明这是一个多内核处理器。cpu cores条目也可以表示是否支持多内核。
实例
- 查看物理CPU个数
[root@apollo-test-env ~]# cat /proc/cpuinfo |grep "physical id"|sort |uniq|wc -l
1
- 查看逻辑CPU个数
[root@apollo-test-env ~]# cat /proc/cpuinfo |grep "processor"|wc -l
4
- 查看CPU是几核
[root@apollo-test-env ~]# cat /proc/cpuinfo |grep "cores"|uniq
cpu cores : 2
- 直接获得CPU核心数 (该命令即可全部算出多少核)
[root@apollo-test-env ~]# grep 'model name' /proc/cpuinfo | wc -l
4
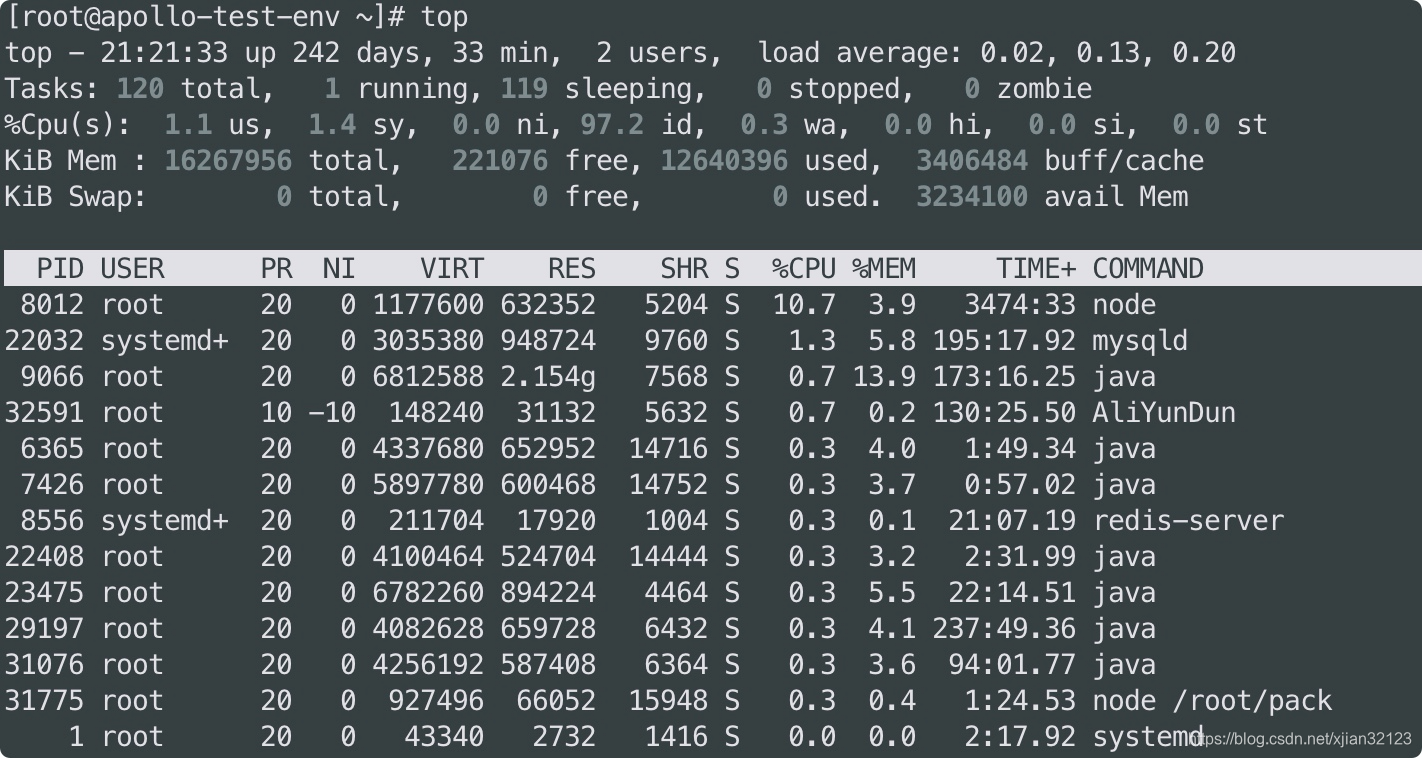
top 命令详解
-
21:21为当前系统运行时间
-
up 系统运行时间为242天33分钟
-
user 当前登录用户数
-
load average 0.00 0.00 0.00 系统负载,任务队列不同时间段平均长度,分别为1分钟,5分钟,15分钟前到现在
-
Tasks
-
120 total, 当前进程总数
-
1 running 正在运行的进程数
-
119 sleeping 睡眠的进程数
-
0 stop 停止的进程数
-
0zombie 僵尸进程数
-
-
Cpu(s)
-
1.1%us:用户空间占用CPU百分比
-
1.4%sy:内核空间占用CPU百分比
-
0.0%ni:用户进程空间内改变过优先级的进程占用CPU百分比
-
97.2%id 空闲CPU
-
0.3%wa 等待输入输出(iO读写)的CPU时间百分比
-
0.0%hi 硬中断
-
0.0%si 软中断
-
0.0%st 实时
-
-
KiB Mem
-
16267956 total:内存总容量
-
221076 free:使用的物理内存总量
-
12640396 used:空闲内存总量
-
3406484 buff/cache:用做内核缓存的内存量
Cache:高速缓存,是位于CPU与主内存间的一种容量较小但速度很高的存储器。由于CPU的速度远高于主内存,CPU直接从内存中存取数据要等待一定时间周期,Cache中保存着CPU刚用过或循环使用的一部分数据,当CPU再次使用该部分数据时可从Cache中直接调用,这样就减少了CPU的等待时间,提高了系统的效率。Cache又分为一级Cache(L1 Cache)和二级Cache(L2 Cache),L1 Cache集成在CPU内部,L2 Cache早期一般是焊在主板上,现在也都集成在CPU内部,常见的容量有256KB或512KB L2 Cache。
Buffer:缓冲区,一个用于存储速度不同步的设备或优先级不同的设备之间传输数据的区域。通过缓冲区,可以使进程之间的相互等待变少,从而使从速度慢的设备读入数据时,速度快的设备的操作进程不发生间断。
-
-
linux内存计算方法
-
多数的linux系统在free命令后会发现free(剩余)的内存很少,而自己又没有开过多的程序或服务。linux的内存管理机制是,内核会把剩余的内存申请为cached,而cached不属于free范畴。当系统运行时间较久,会发现cached很大,对于有频繁文件读写操作的系统,这种现象会更加明显。
-
直观的看,此时free的内存会非常小,但并不代表可用的内存小,当一个程序需要申请较大的内存时,如果free的内存不够,内核会把部分cached的内存回收,回收的内存再分配给应用程序。所以对于linux系统,可用于分配的内存不只是free的内存,还包括cached的内存(其实还包括buffers)。即:
可用内存 = free的内存+cached的内存+buffers的内存
- 所以,真正的内存利用率 = 可用内存 / 总内存(注意此处 可用内存 由上述公式计算而来,其实这个计算结果在free命令回显中已有,即回显结果中“available 3285492”)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PEcWFhK3-1590742974461)(media/15889411765970/15889457739717.jpg)]
-
-
KiB Swap
-
0 total:交换分区总量
-
0 free:使用的交换分区总量
-
0 used:空闲的交换分区总量
-
3234100 avail Mem:缓冲的交换区总量
-
-
进程部分
-
PID:进程ID
-
USER:真实用户名称
-
PR:优先级
-
NI:Nice值,负值表示高优先级,正值表示低优先级
-
VIRT:进程使用的虚拟内存总量,单位kb VIRT=SWAP+RES
-
RES:进程使用的、未被换出的物理内存大小,单位kb RES=CODE+DATA
-
SHR:共享内存大小,单位kb
-
S:进程状态 D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程
-
%CPU:上次更新到现在的CPU时间占用百分比
-
%MEM:进程使用的物理内存百分比
-
TIME+:进程使用的CPU时间总计,单位1/100秒
-
COMMAND:命令名/命令行 进程名称
-
其他系统查询命令
vmstat
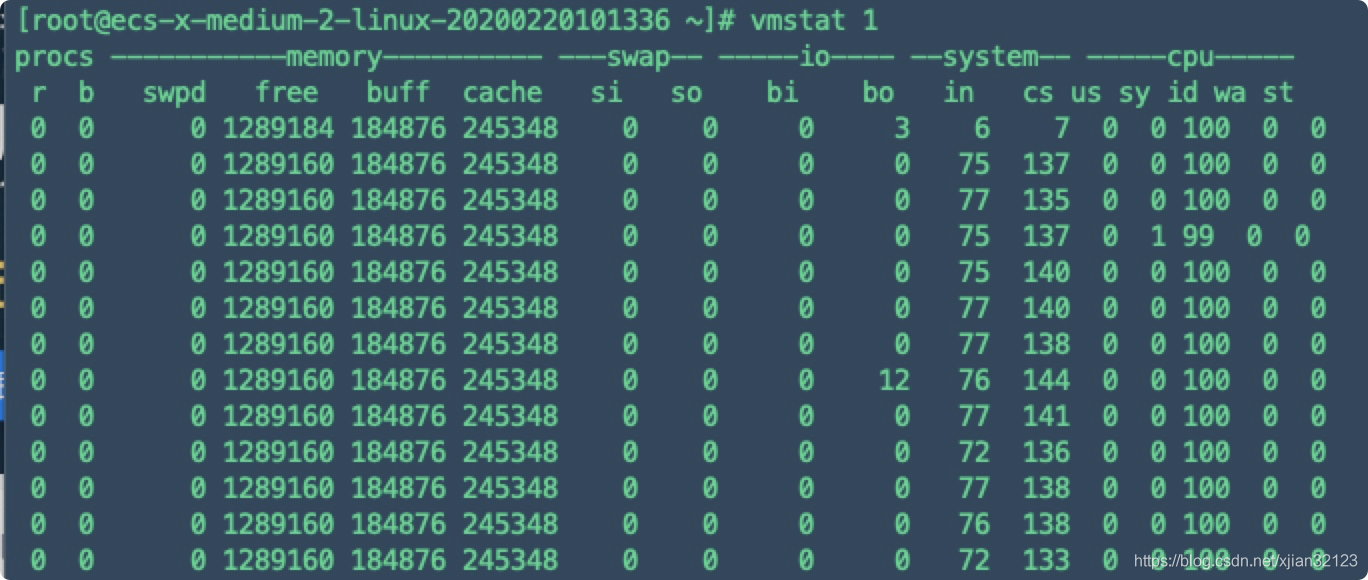
- vmstat使用
# 每两秒刷新一次,刷新100次
vmstat 2 100
# 每秒刷新一次,一直刷新
vmstat 1
-
procs
-
r:列表示运行和等待cpu时间片的进程数,如果长期大于1,说明cpu不足,需要增加cpu
-
b:列表示在等待资源的进程数,比如正在等待I/O、或者内存交换等
-
-
memory
-
swpd:切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
-
free:当前的空闲页面列表中内存数量(k表示)
-
buff:作为buffer cache的内存数量,一般对块设备的读写才需要缓冲。
-
cache: 作为page cache的内存数量,一般作为文件系统的cache,如果cache较大,说明用到cache的文件较多,如果此时IO中bi比较小,说明文件系统效率比较好。
-
-
swap
-
si:由内存进入内存交换区数量。
-
so:由内存交换区进入内存数量。
-
-
io
-
bi:从块设备读入数据的总量(读磁盘)(每秒kb)
-
bo:块设备写入数据的总量(写磁盘)(每秒kb)
-
这里我们设置的bi+bo参考值为1000,如果超过1000,而且wa值较大应该考虑均衡磁盘负载,可以结合iostat输出来分析。
-
-
system
-
in:表示在某一时间间隔中观测到的每秒设备中断数。
-
cs:表示每秒产生的上下文切换次数,如当 cs 比磁盘 I/O 和网络信息包速率高得多,都应进行进一步调查。
-
-
cpu
-
cpu:表示cpu的使用状态
-
us:显示了用户方式下所花费 CPU 时间的百分比。us的值比较高时,说明用户进程消耗的cpu时间多,但是如果长期大于50%,需要考虑优化用户的程序。
-
sy:列显示了内核进程所花费的cpu时间的百分比。这里us + sy的参考值为80%,如果us+sy 大于 80%说明可能存在CPU不足。
-
wa:列显示了IO等待所占用的CPU时间的百分比。这里wa的参考值为30%,如果wa超过30%,说明IO等待严重,这可能是磁盘大量随机访问造成的,也可能磁盘或者磁盘访问控制器的带宽瓶颈造成的(主要是块操作)。
-
id:列显示了cpu处在空闲状态的时间百分比
-
iostat
每隔2秒统计一次磁盘IO信息,直到按Ctrl+C终止程序,第一次输出的磁盘IO负载状况提供了关于自从系统启动以来的统计信息。随后的每一次输出则是每个间隔之间的平均IO负载状况。
d:选项表示统计磁盘信息
k:表示以每秒KB的形式显示
t:要求打印出时间信息
2:表示每隔2秒输出一次
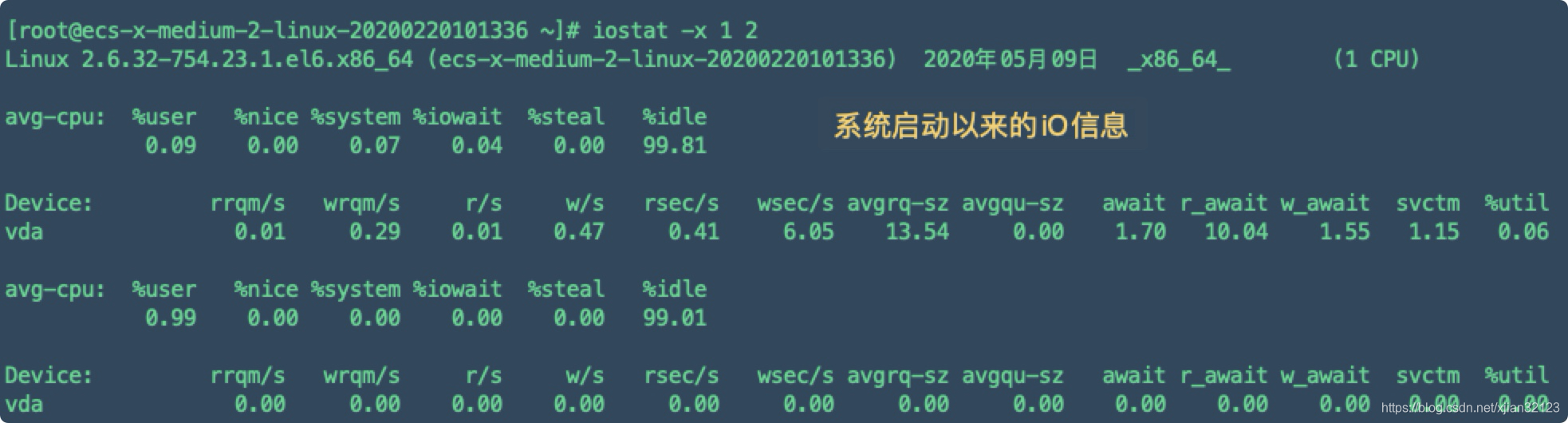
- 安装命令(centOS)
yum install sysstat
- 命令详解
iostat -x 1 2意思是时间间隔为1秒,刷屏信息显示2次-
rrqm/s:每秒进行merge(合并)的读操作数目
-
wrqm/s:每秒进行 merge 的写操作数目。即 delta(wmerge)/s
-
r/s:每秒完成的读 I/O 设备次数。即 delta(rio)/s
-
w/s: 每秒完成的写 I/O 设备次数。即 delta(wio)/s
-
rsec/s: 每秒读扇区数。即 delta(rsect)/s
-
wsec/s: 每秒写扇区数。即 delta(wsect)/s
-
avgrq-sz:平均每次设备I/O操作的数据大小 (扇区)。delta(rsect+wsect)/delta(rio+wio)
-
avgqu-sz:平均I/O队列长度。即 delta(aveq)/s/1000 (因为aveq的单位为毫秒)。
-
await: 平均每次设备I/O操作的等待时间 (毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
-
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。即 delta(use)/delta(rio+wio)
-
%util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即
-
delta(use)/s/1000 (因为use的单位为毫秒)
-
如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
-
%idle(空闲)小于70% IO压力就较大了,一般读取速度有较多的wait。同时可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)
-














 553
553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









