







一、例题
- 给定n个正整数 ai,请你输出这些数的乘积的约数之和,答案对 1e9+7 取模
- 第一行包含整数n
- 接下来n行,每行包含一个整数
- 输出一个整数,表示所给正整数的乘积的约数之和,答案需对 1e9+7 取模
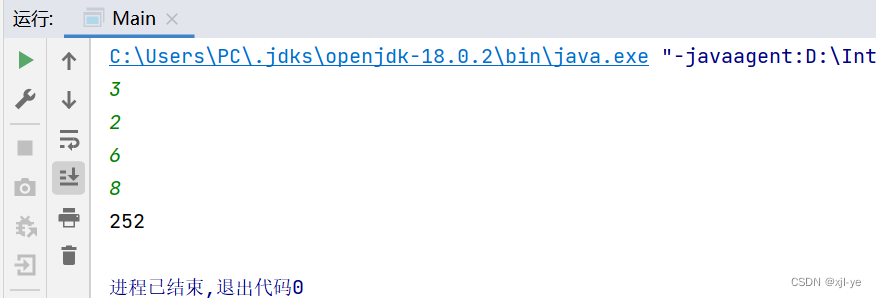
样例输入:
3
2
6
8
样例输出:
252
二、原理与分析
(1)求约数之和的公式
p为底数,a为指数
(p1^0+p1^1+p1^2+...+p1^ak)*(p2^0+p2^1+p2^2+...+p2^ak)*...*(pk^0+pk^1+pk^2+...+pk^ak)
(2)公式推理
- 此公式按照乘法分配率展开后是一堆乘积+一堆乘积+一堆乘积的形式
- 每一堆乘积就对应一种约数,相加即为约数之和
(3)总体思路
(1)依次将输入的每一个数字分解质因数,并将其底数与指数存放在HashMap中
(2)然后对每一个底数与指数进行分解计算
- 循环到一对底数p与指数a
- 要求
p1^0+p1^1+p1^2+...+p1^a
- 则需要循环a次
- 令求和的t初始值为1,每循环一次 *p+1
初始: t=1
第一趟: t=p+1
第二趟: t=(p+1)*p+1=p^2*p+1
执行a次可得到 p^a+p^(a-1)+...+p^2+p+1
- 有多少对底数与指数就将上述的过程再执行多少趟趟,就可得出所需求约数之和的式子
- 例如:
2*6*8= 96 = (2^5)*(3^1)
然后对每一个进行分解计算
(2^0+2^1+2^2+2^3+2^4+2^5)*(3^0+3^1)=252
(4)小知识
- int范围内的整数,约数个数最多的大概是1500个,有时可以用来快速验证答案
(5)HashMap
- 由于每一个p1和b1都是一一对应的,即底数和指数时一一对应的,我们可以用HashMap来存储
- 因此需要了解Map集合的相关知识:
Map集合是一种双列集合,每个元素包含两个数据。
Map集合的每个元素的格式:key=value(键值对元素)。
Map集合也被称为”键值对集合“
键和值一一对应,一个键对应一个值,整个集合的特点是由键决定的
HashMap:元素按照键是无序,不重复,无索引,值不做要求。(与Map体系一致)
getOrDefault(key, default):如果存在key, 则返回其对应的value, 否则返回给定的默认值
更加详细的关于HashMap的原理与使用可以看我的另一篇博客
暑期JAVA学习(13)Map集合体系
三、代码与注释
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
//题目:
//给定n个正整数 ai,请你输出这些数的乘积的约数之和,答案对 1e9+7 取模
//第一行包含整数 n
//接下来 n 行,每行包含一个整数 ai
//输出一个整数,表示所给正整数的乘积的约数之和,答案需对 1e9+7 取模
//求约数之和的公式:(p1^0+p1^1+p1^2+...+p1^ak)*(p2^0+p2^1+p2^2+...+p2^ak)*...*(pk^0+pk^1+pk^2+...+pk^ak)
//此公式按照乘法分配率展开后是一堆乘积+一堆乘积+一堆乘积的形式
//每一堆乘积就对应一种约数
//总体思路:
//(1)依次将输入的每一个数字分解质因数,并将其底数与指数存放在HashMap中
//(2)然后对每一个底数与指数进行分解计算
// 循环到一对底数p与指数a
// 要求p1^0+p1^1+p1^2+...+p1^a
// 循环a次
// 令求和的t初始值为1,每循环一次 *p+1
// 初始: t=1
// 第一趟: t=p+1
// 第二趟: t=(p+1)*p+1=p^2*p+1
// 执行a次可得到 p^a+p^(a-1)+...+p^2+p+1
// 有多少对底数与指数就将上述的过程再执行多少趟趟,就可得出所需求约数之和的式子
//例如:
//2*6*8= 96 = (2^5)*(3^1)
//然后对每一个进行分解计算
//(2^0+2^1+2^2+2^3+2^4+2^5)*(3^0+3^1)=252
public class Main {
public static long mod = 1000000007;
//定义一个HashMap来对应存储所有项的底数与指数,一一对应,方便使用
public static HashMap<Integer, Integer> primes = new HashMap<>();
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();//一共有n个正整数
//将所有的数分解质因数,并存放在primes中
//遍历每一个输入的整数,总共遍历n次
while (n-- > 0){
int x = sc.nextInt();
//每个合数都可以写成几个质数相乘的形式,这几个质数就都叫做这个合数的质因数
//此处用到的就是分解质因数的算法
//用i遍历x的底数,若i为x的底数(即x%i==0),就把i对应的指数加一,即把map的value值加一
//例如8=2^3,那么map中key为2的value值就一共会加3
for (int i = 2; i <= x/i; i++) {
while (x % i == 0){
x = x/i;
//getOrDefault(key, default)如果存在key, 则返回其对应的value, 否则返回给定的默认值
primes.put(i, primes.getOrDefault(i, 0) + 1);//这一句用getOrDefault是防止NullPointerException
}
}
//如果说x被所有小于根号x的质数因子除完后,还大于1,说明剩下的一定是那个大于根号x的质因子,直接输出即可 (例如11,43这样的数)
//证明:一个数x中最多包含一个大于根号x的质数因子,很好证明,如果有两个大于根号x的质数因子那么这俩相乘就大于x了,反证法成立
if (x > 1){
primes.put(x, primes.getOrDefault(x, 0) + 1);
}
}
//result存储最终结果
long result = 1;
//遍历Map
//Map.entrySet() 这个方法返回的是一个Set<Map.Entry<K,V>>
//Map.Entry 是Map中的一个接口,他的用途是表示一个映射项(里面有Key和Value)
//而Set<Map.Entry<K,V>>表示一个映射项的Set。Map.Entry里有相应的getKey和getValue方法
for (Map.Entry<Integer,Integer> i : primes.entrySet()) {
long t = 1;
int p = i.getKey();//p是底数
int a = i.getValue();//a是次方
while (a-- > 0){
t = (t*p+1)%mod;
}
result = result * t % mod;
}
System.out.println(result);
}
}
纯代码
import java.util.HashMap;
import java.util.Map;
import java.util.Scanner;
public class Main {
public static long mod = 1000000007;
public static HashMap<Integer, Integer> primes = new HashMap<>();
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
while (n-- > 0){
int x = sc.nextInt();
for (int i = 2; i <= x/i; i++) {
while (x % i == 0){
x = x/i;
primes.put(i, primes.getOrDefault(i, 0) + 1);
}
}
if (x > 1){
primes.put(x, primes.getOrDefault(x, 0) + 1);
}
}
long result = 1;
for (Map.Entry<Integer,Integer> i : primes.entrySet()) {
long t = 1;
int p = i.getKey();//p是底数
int a = i.getValue();//a是指数
while (a-- > 0){
t = (t*p+1)%mod;
}
result = result * t % mod;
}
System.out.println(result);
}
}

















 1178
1178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











