







目录
假设下面是我们爬取到的页面代码(此代码结构简单,内容单一,便于练习):
因为该例子中标签名为li的标签不止一个,所以可以用for循环便利取出:
一、urllib包
Get请求
目的:访问该网址

添加header
目的:更改请求头,防止爬虫被拦截
参考博客:https://blog.csdn.net/sagegrass/article/details/125402636

如何获取自己的user-agent视频演示:
Google如何获取自己的user-agent
注:https表示安全模式,http是非安全模式
from urllib import request
# 通过request对象发起一个请求,并获取服务器的响应
# resp=request.urlopen('http://www.baidu.com')
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'}
# 将url和headers绑定,并返回request
req=request.Request(url="http://www.baidu.com",headers=headers)
# 通过req对象发起请求,并获取服务器的响应
resp=request.urlopen(req)
print(type(resp))
# 读取响应中的代码
print(resp.read().decode())下载
目的:下载文档、图片均可
 爬取百度某图片:
爬取百度某图片:
from urllib import request
url="https://gimg2.baidu.com/image_search/src=http%3A%2F%2Fwww.tk-edu.com%2Fdata%2Fupload%2Fimage%2F202004%2Fb69c3adebed5d31218fec4aab82c6cd4.jpg&refer=http%3A%2F%2Fwww.tk-edu.com&app=2002&size=f9999,10000&q=a80&n=0&g=0n&fmt=auto?sec=1672805313&t=d3e98494c117fd93b8b93a565abe7178"
# 保存在桌面上并命名为python.png
request.urlretrieve(url=url,filename="C:\\Users\\11597\\Desktop\\python.png")结果如下:
注意:要爬取图片时应该将此图片点开(单击鼠标右键-->在菜单栏中选择“在新标签页中打开图像”),在点开的网页中的网址才是对应该图片本身的网址信息
Urllib.parse
注:仅做了解

在百度搜索图片时输入的是“python图片”,该字样会在浏览器的地址栏上显示出来:![]()
但如果将浏览器的地址复制到pycharm中,搜索时输入的中文字符就会变成转义格式:

二、requests包
get请求
如果仅仅只是用此语句运行:

结果:
会发现不再是像最开始爬baidu网页那般显示很长一大段而是显示几句代码行。
原因:没有加header,不具备合法的请求,被网页拦截

修改补充:
import requests
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'}
resp=requests.get("https://www.baidu.com",headers=headers)
print(resp.text) 结果如下:
post请求

保存
代码演示:
import requests
headers={'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'}
resp=requests.get("https://www.baidu.com",headers=headers)
print(resp.text)
# 可迭代的结果
iter=resp.iter_content()
# 将可迭代的结果写入到文件,写:w+,后面的write(str(line))需要加字符串标识
with open("C:\\Users\\11597\\Desktop\\11597\\demo.html",mode="w+") as file:
for line in iter:
file.write(line)结果如下:

三、爬虫库-Beautiful Soup
定义

可以通过content或者text获取文本,‘html.parser’是转换器,‘lxml’是工作上常用的转换器

标准选择器


假设下面是我们爬取到的页面代码(此代码结构简单,内容单一,便于练习):
# '''三引号会保留文档的原格式
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''1.find_all:
代码实现,查找标签h4的内容:
from bs4 import BeautifulSoup
# 通过request对象爬取的页面
html='''
<div class="panel">
<div class="panel-heading">
<h4>Hello</h4>
</div>
<div class="panel-body">
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>
<ul class="list list-small" id="list-2">
<li class="element">Foo</li>
<li class="element">Bar</li>
</ul>
</div>
</div>
'''
# 对html文档进行解析,转为BeautifulSoup对象
bs=BeautifulSoup(html,"html.parser")
# find_all查找指定标签(标签名,属性,内容)
tags=bs.find_all(name="h4")
# 输出tags的类型
print(type(tags))
# tags有可能拿到的是多个标签名为“h4”的标签,所以指定为[0]是只拿到第一个
print(tags[0].text)
结果如下所示:

查找标签名为li的第一个标签内容:
# find_all查找指定标签(标签名,属性,内容)
tags=bs.find_all(name="li")
# 输出tags的类型
print(type(tags))
# tags有可能拿到的是多个标签名为“h4”的标签,所以指定为[0]是只拿到第一个
print(tags[0].text)结果如下:

因为该例子中标签名为li的标签不止一个,所以可以用for循环便利取出:
# find_all查找指定标签(标签名,属性,内容)
tags=bs.find_all(name="li")
# 输出tags的类型
print(type(tags))
# 获取所有选中标签中的文本
for tag in tags:
# 获取标签中的文本
print(tag.text)结果如下:

也可以通过属性名和属性值来查找标签名li的标签内容:
# find_all查找指定标签(标签名,属性,内容)
tags=bs.find_all(name="li",attrs={"class":"element"})
# 输出tags的类型
print(type(tags))
# 获取所有选中标签中的文本
for tag in tags:
# 获取标签中的文本
print(tag.text)2.find
还可以根据内容去查找,find表示只找出第一个:
# 根据规则查找标签,如果有多个,只保留第一个
res=bs.find(string="Bar")
# 获取匹配标签的name属性
print(res)标签名ul查找标签和查找标签内容的区别:
<ul class="list" id="list-1" name="elements">
<li class="element">Foo</li>
<li class="element">Bar</li>
<li class="element">Jay</li>
</ul>查找标签:
# 根据规则查找标签,如果有多个,只保留第一个
res=bs.find(name="ul",attrs={"id":"list-1"})
# 输出标签
print(res)结果如下:

查找标签内容:
# 根据规则查找标签,如果有多个,只保留第一个
res=bs.find(name="ul",attrs={"id":"list-1"})
# 输出标签的内容
print(res.text)结果如下:

3.get
获取name的属性:
# 根据规则查找标签,如果有多个,只保留第一个
res=bs.find(name="ul")
# 获取匹配标签ul的name的属性值
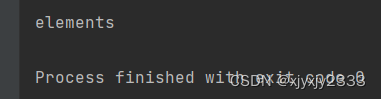
print(res.get("name"))结果如下:
未完待续……















 1780
1780











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









