







 本文介绍如何使用Python和Selenium库自动化操作,实现京东店铺的每日签到,避免手动操作的繁琐和遗忘。通过设置脚本,抓取网页元素并模拟登录和签到过程,提升效率。
本文介绍如何使用Python和Selenium库自动化操作,实现京东店铺的每日签到,避免手动操作的繁琐和遗忘。通过设置脚本,抓取网页元素并模拟登录和签到过程,提升效率。
对于京东上,自己喜欢的店铺,经常签到会有一些优惠,比如给优惠券或者给店铺会员积分。
但是每天自己手工签到比较麻烦,容易忘。
是不是可以自动化签到?
来试试
1、安装selenium
pip install selenium
2、查看自己的浏览器版本(以chrome为例)
在chrome搜索栏输入:chrome://settings/help
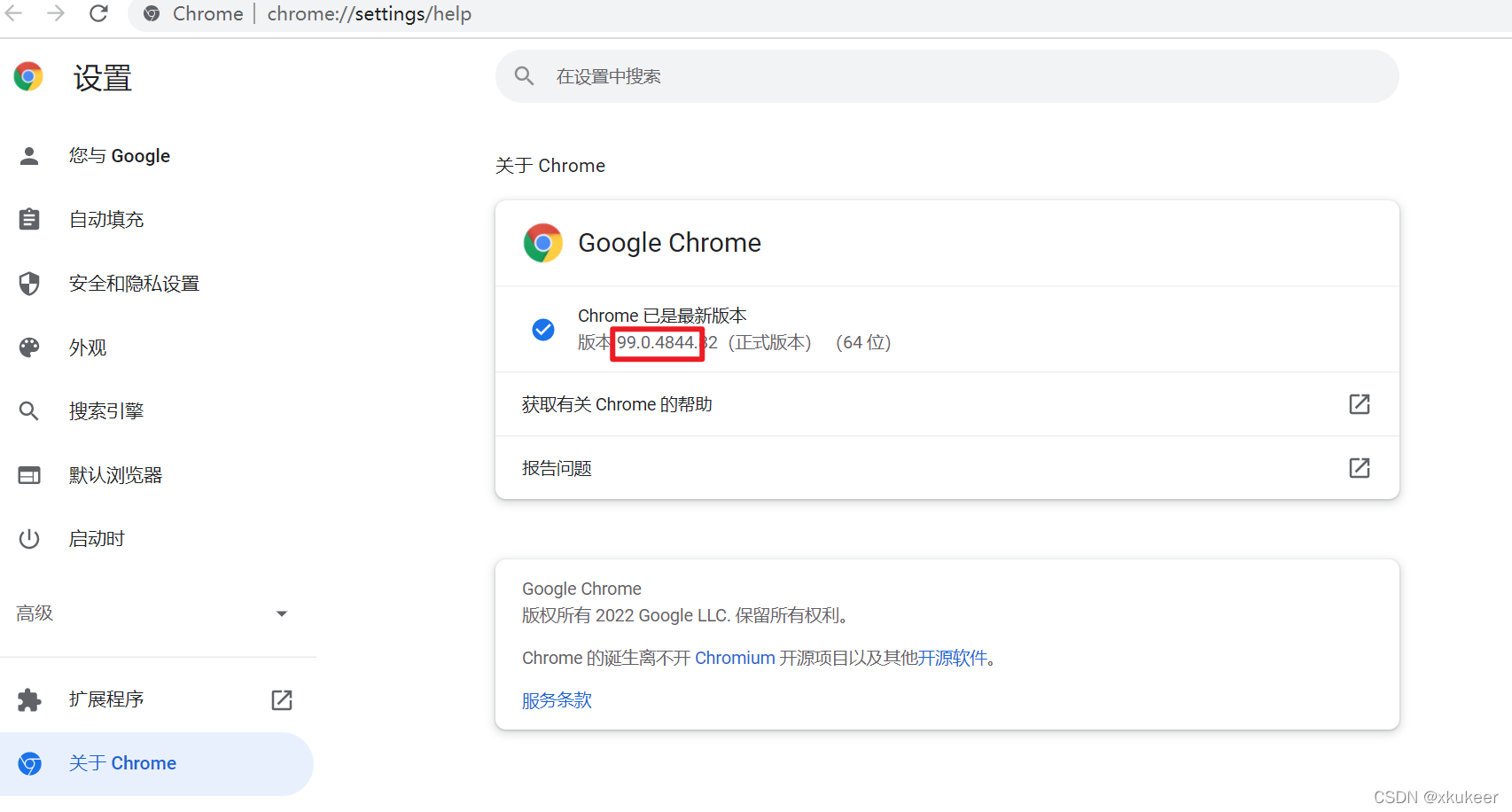
3、按照浏览器版本,在下面的链接中找驱动
http://chromedriver.storage.googleapis.com/index.html
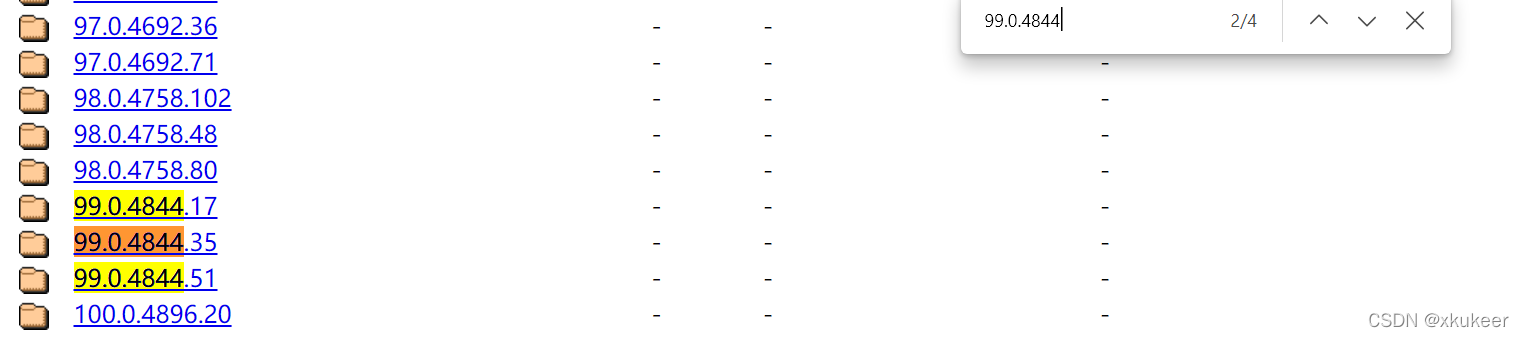
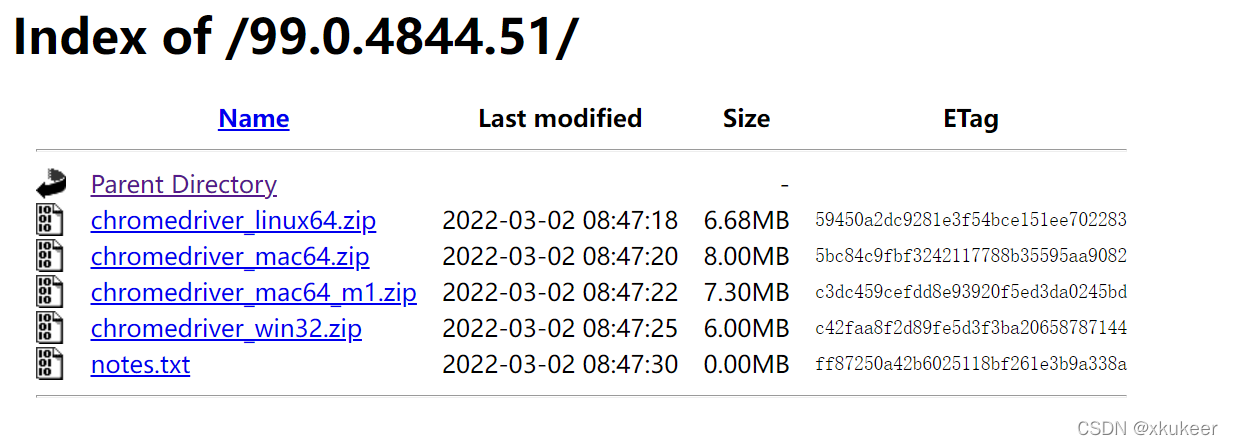
4、按照操作系统找对应版本下载
(这里有点不明白,为啥没win64的。但是win32的也能用)
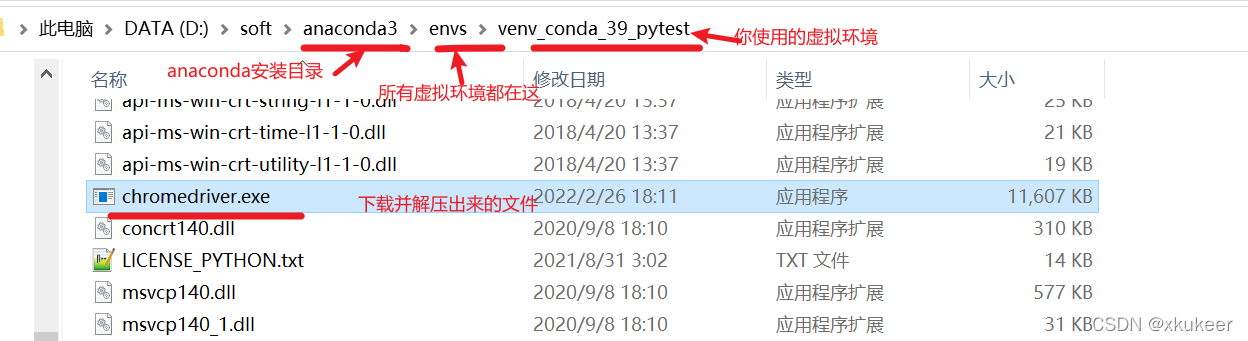
5、下载完成后,解压。把解压出来的文件,放到你的运行环境里。我是用anaconda的虚拟环境,所以就放到虚拟环境目录下。
6、写代码
from selenium import webdriver
wd = webdriver.Chrome()
wd.implicitly_wait(1)
# 店铺界面
wd.get('https://mall.jd.com/index-1000097085.html')
# 上边的那个请登录按钮
please_login = wd.find_element_by_xpath('//*[@id="ttbar-login"]/a[1]')
please_login.click()
# 登录界面的扫码登录和账号登录
zhanghudenglu = wd.find_element_by_xpath('//*[@id="content"]/div[2]/div[1]/div/div[3]/a')
zhanghudenglu.click()
# 用户名密码
input = wd.find_element_by_xpath('//*[@id="loginname"]')
input.send_keys('XXXXXXXXX')
passwd = wd.find_element_by_xpath('//*[@id="nloginpwd"]')
passwd.send_keys('XXXXXXXX')
# 确定登录按钮
button_login = wd.find_element_by_xpath('//*[@id="loginsubmit"]')
button_login.click()
# 签到按钮
try:
qiandao = wd.find_element_by_xpath('/html/body/div[2]/div/div/div[4]/a')
qiandao.click()
except:
print('已签到')
# wd.quit()说明:
Selenium提供了很多种定位DOM元素的方法,这次使用 by_xpath() 这个方法来定位元素
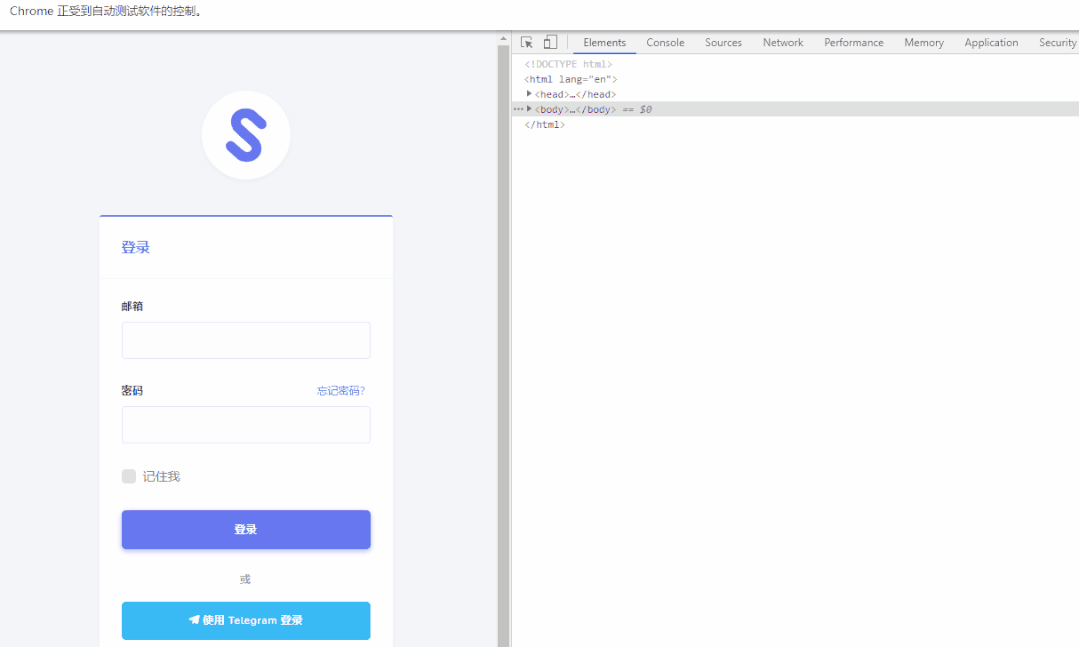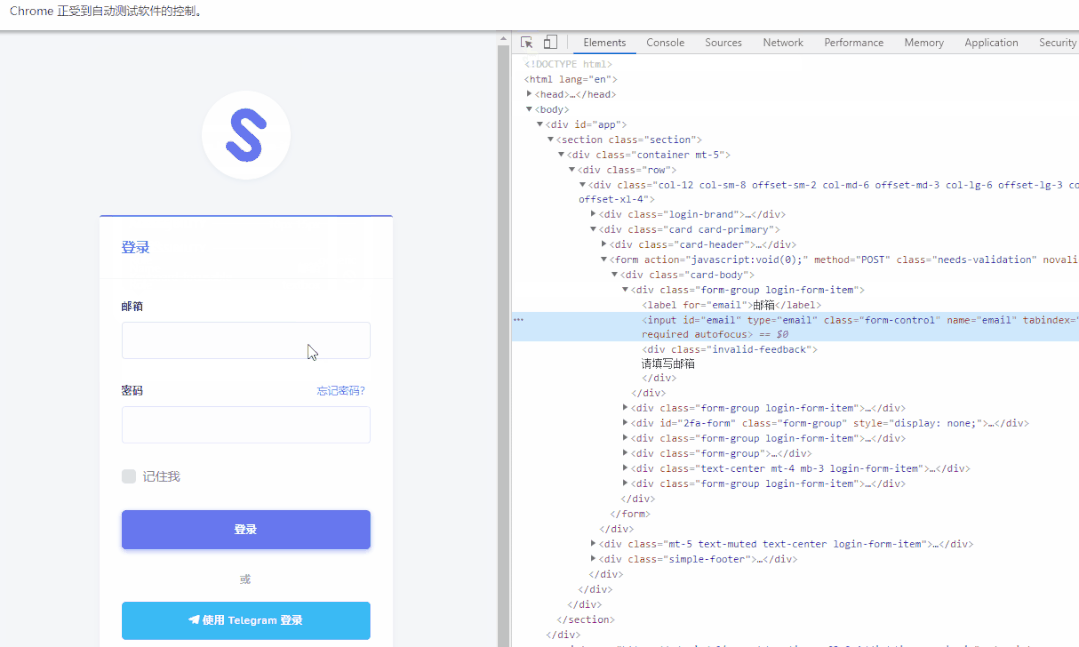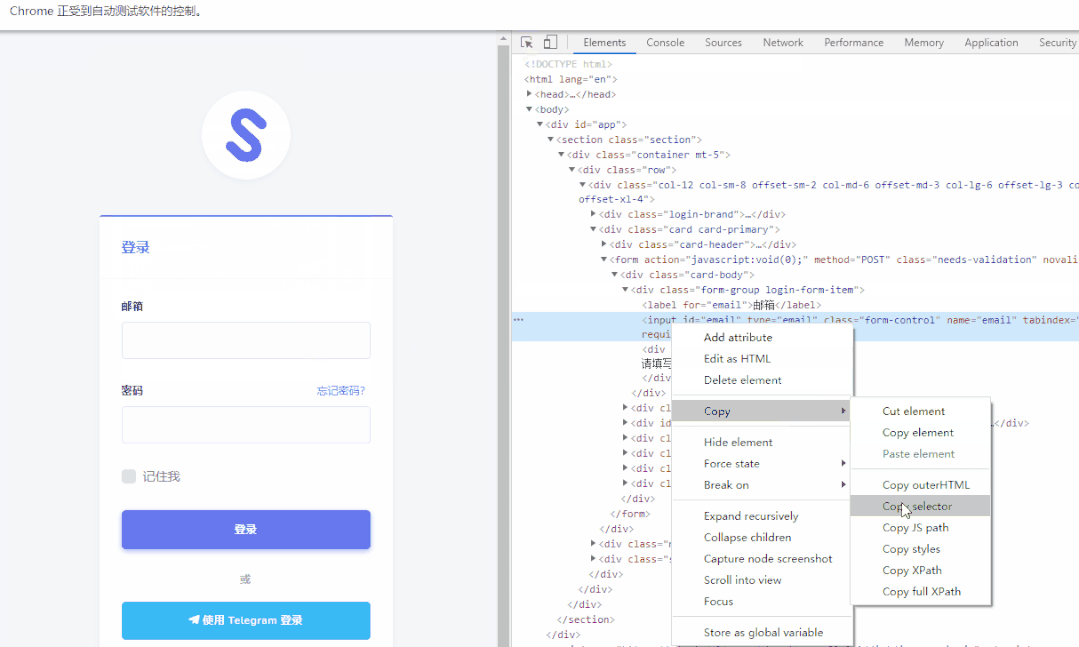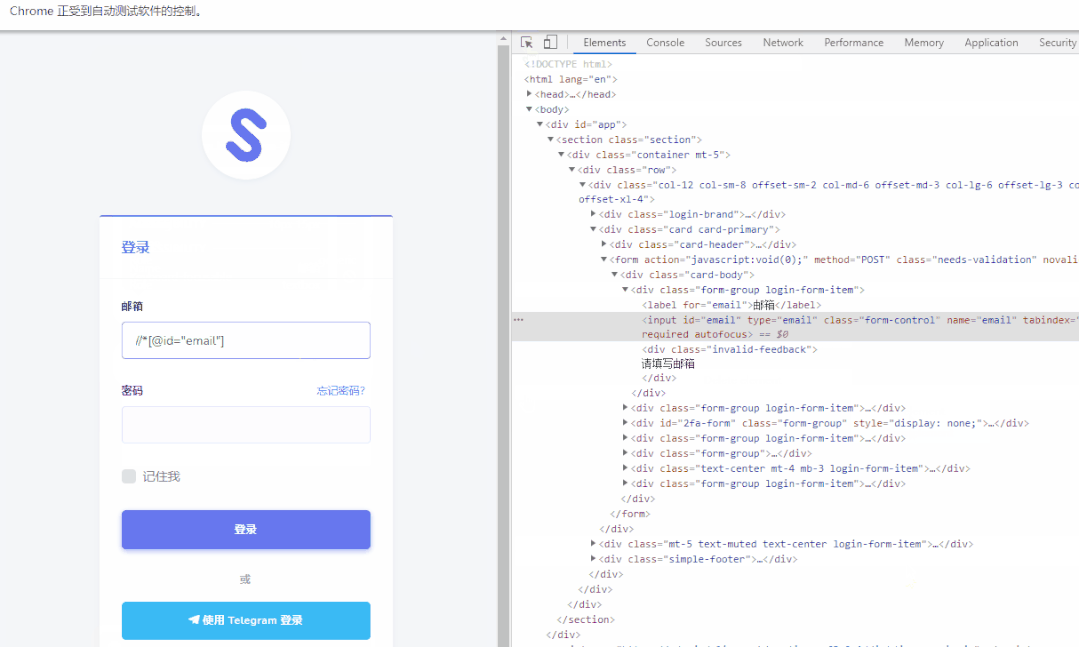
【检查】→【进入开发者模式】点击左上角的图标,再点击你要找的对象,即可得到该对象的信息。点位该对象后,右键copy它的XPath
(下面的图是抄最下边参考里边大佬的图)
7、运行程序
出现问题:拼图验证。这个暂时不会绕过去。还需要继续研究。
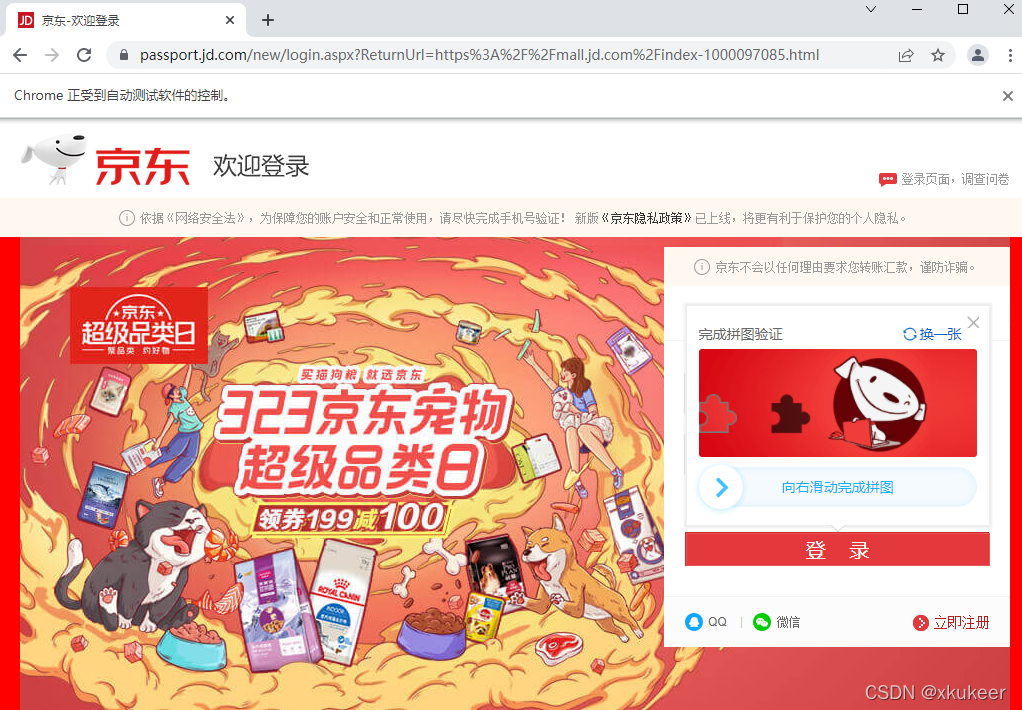
8、运行结果:
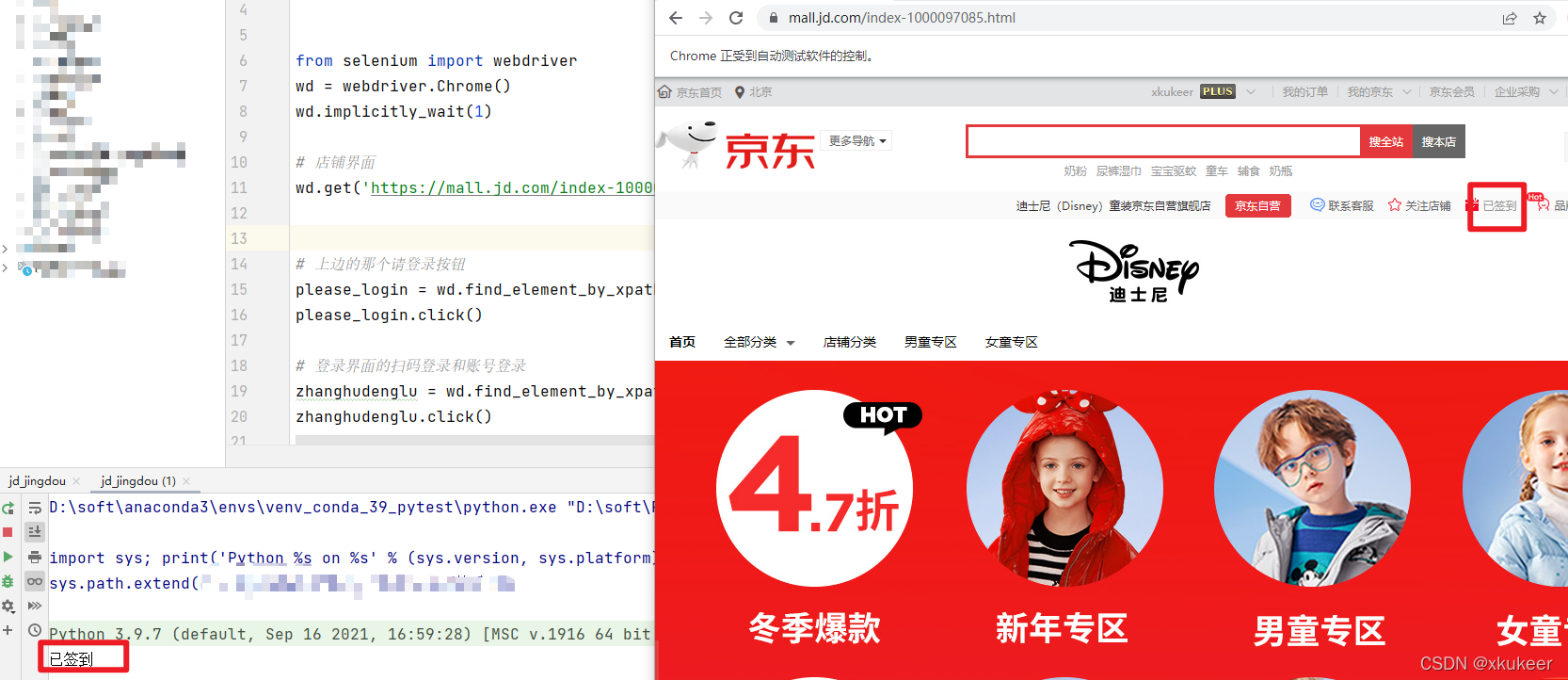
以上。借助自动化可以帮助实现很多实际生活中的事情。多发觉研究。
参考:

















 3064
3064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









