







公众号看到的文章,感觉不错,适合练手。所以就自己做了一遍。
废话不多说开整。

目的:手头有一份《学校名称.xlsx》的表格。想要这些学校的英文名称、描述、简称
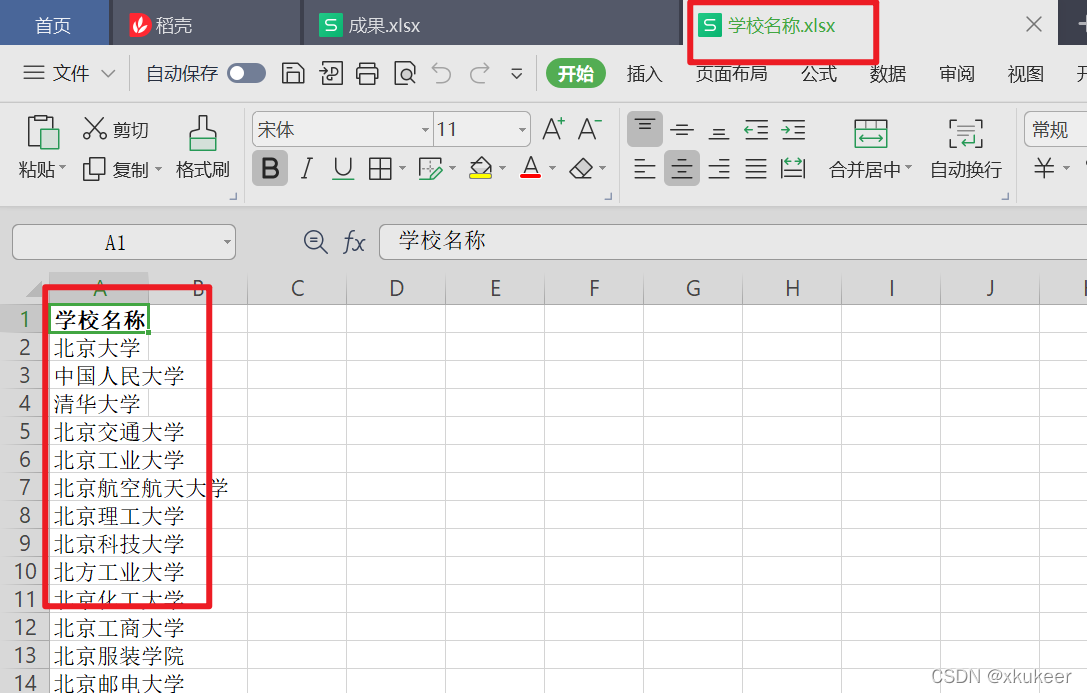
学校名称.xlsx
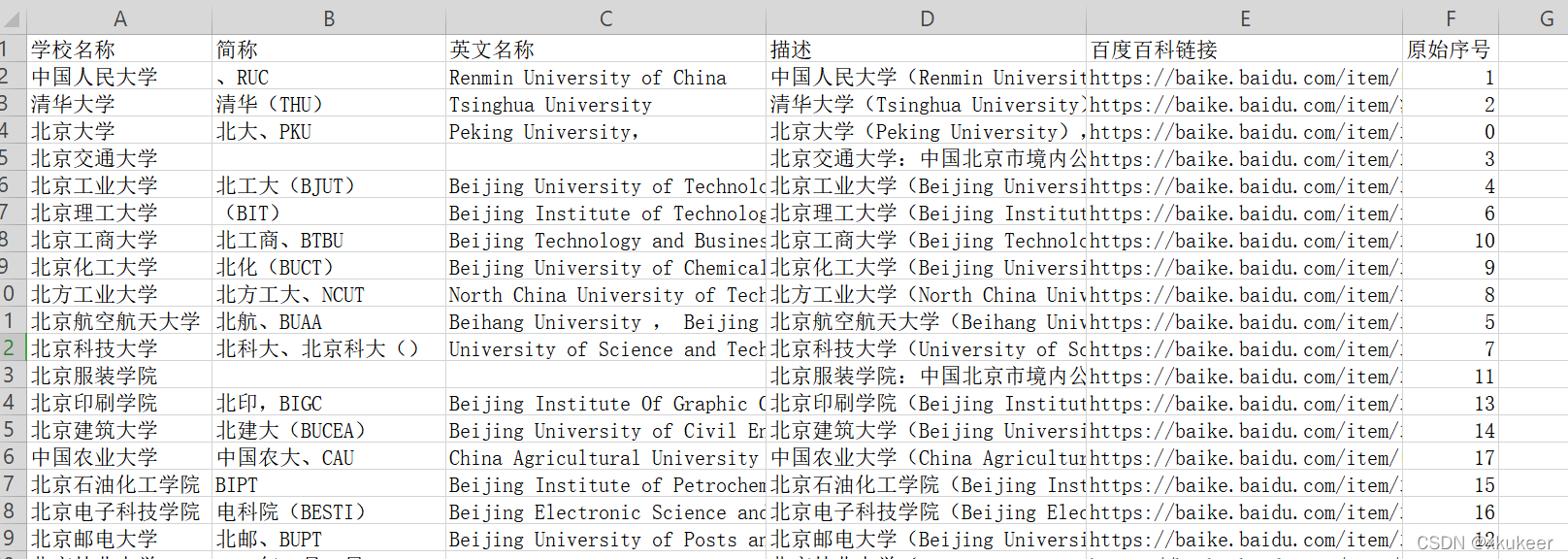
最终成果
步骤1:分析
所需要的学校信息,一般在百度百科里都有。所以先看看百度百科的数据能不能满足我们的要求。
先抽样找一个学校到百度百科看看情况
拿北京大学来说:英文名称、描述、简称
都可以在这一个界面中获取到。
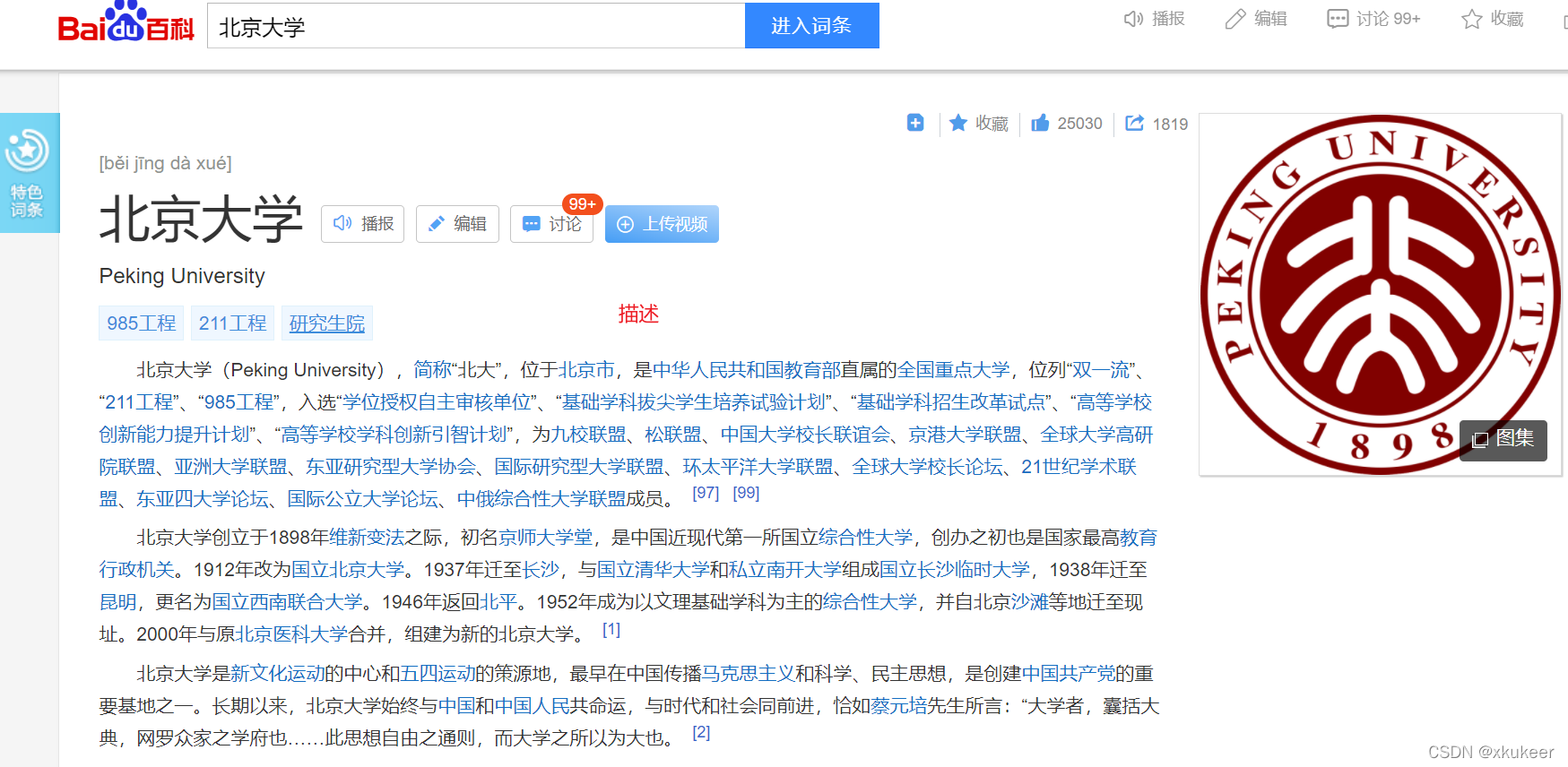
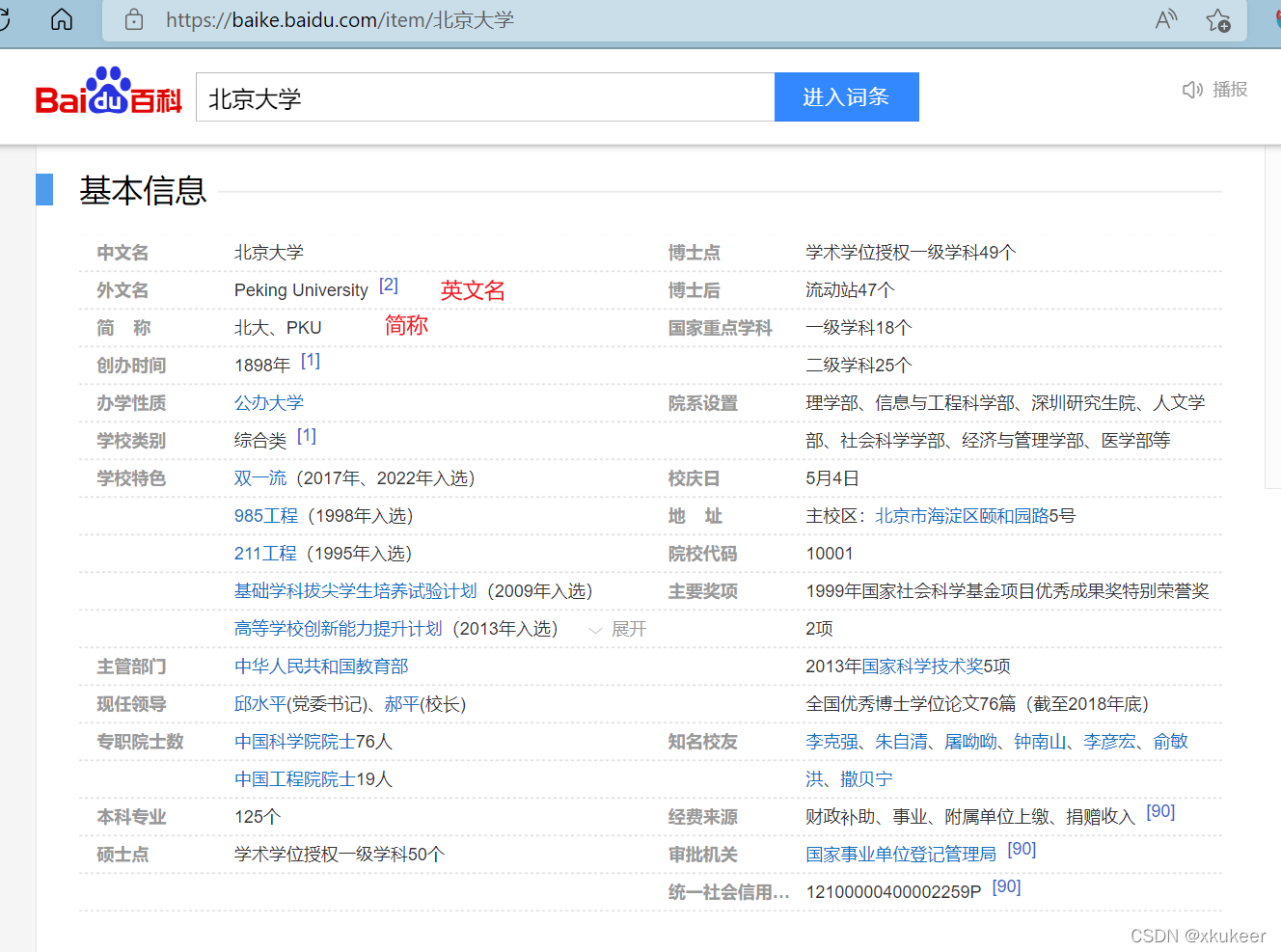
然后所有的信息,在页面源码中也能看得到。所以理论上我们把这个页面的信息爬下来之后,做简单的处理就行了。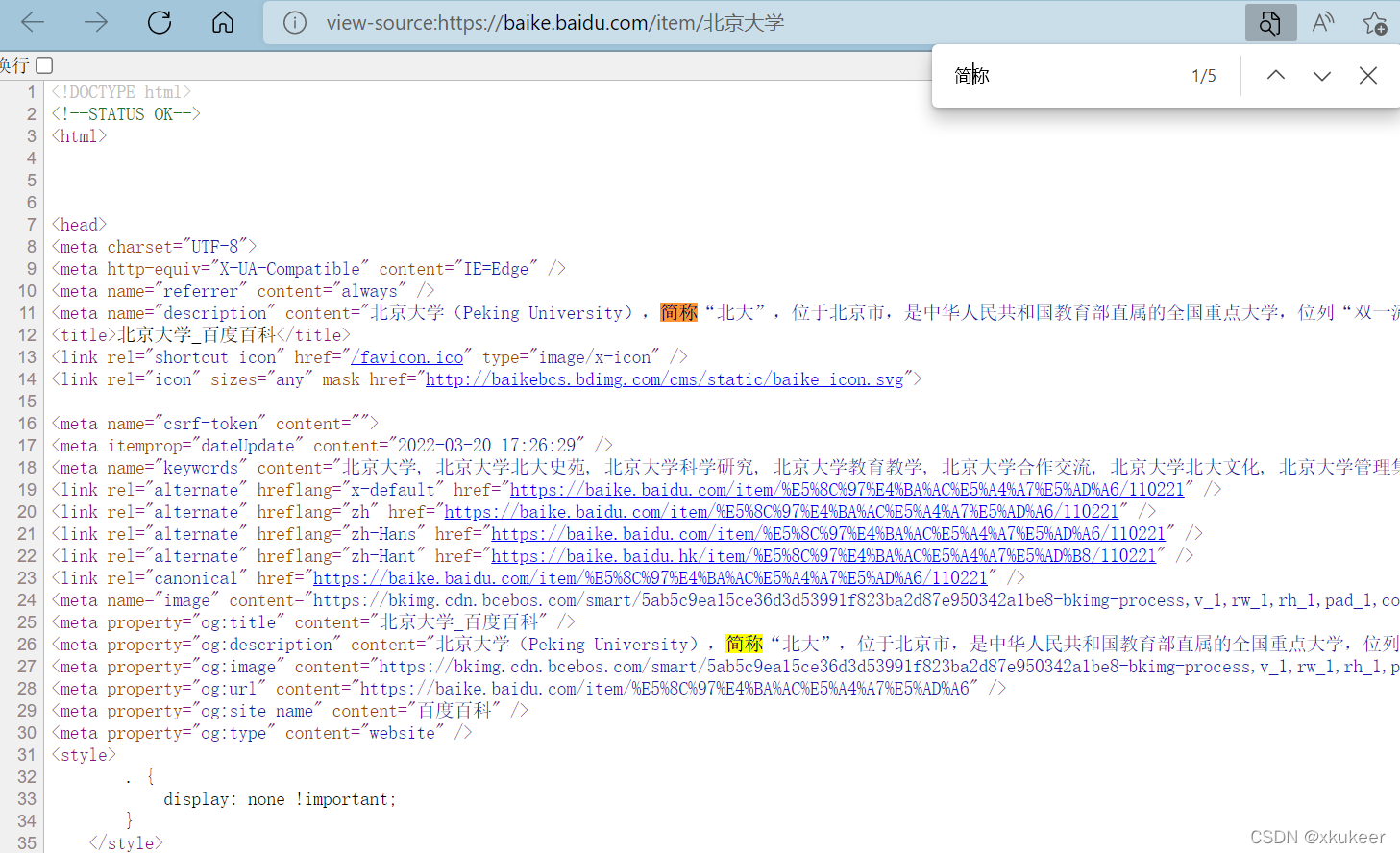
步骤2:写代码
1、需要用到的技术和包
import requests
import pandas as pd
from random import choice
from lxml import etree
import openpyxl
import logging
from concurrent.futures import ThreadPoolExecutor
from time import sleep
from random import random说明:
requests,python爬虫必备。这里用来发送get请求并接受返回结果
pandas,数据分析的基础,必备。这里用于把Excel表格的学校名称,用pandas读取之后转成list,并组成百度百科网址的一部分。
random,
random方法,生成伪随机数。跟time一起使用。让程序随机睡眠几秒,避免CPU一直被占用导致电脑发热、死机以及避免百度封ip
choice方法,随机一个。这里用于随机选择一个http的头信息。
lxml,解析网页返回数据用(返回数据是一堆网页代码。很多无用的,得解析到需要的英文名、简称、描述)
openpyxl,写入表格用的
logging,记录日志
concurrent.futures,Python多线程。我们要爬取3000左右的数据,单线程执行会很慢,用多线程会快很多
time,用sleep方法,让代码休眠。
2、写一个爬取数据的函数
def get_data(item):
try:
# 记录一下它原本的序号
sort_num = items.index(item)
# 随机生成请求头
headers = {
'User-Agent':choice(user_agent)
}
# 构造的url
url = f'https://baike.baidu.com/item/{item}'
# 发送请求 获取响应
rep = requests.get(url, headers=headers)
sleep(random())
# Xpath解析提取数据
html = etree.HTML(rep.text)
description = ''.join(html.xpath('/html/head/meta[4]/@content'))
# 外文名
en_name = ','.join(html.xpath('//dl[@class="basicInfo-block basicInfo-left"]/dd[2]/text()')).strip()
# 中文简称 有的话 是在dd[3]标签下
simple_name = ''.join(html.xpath('//dl[@class="basicInfo-block basicInfo-left"]/dd[3]/text()')).strip()
sheet.append([item, simple_name, en_name, description, url, sort_num])
logging.info([item, simple_name, en_name, description, url, sort_num])
except Exception as e:
logging.info(e.args)
pass3、写一个多线程的函数,并保存爬取并解析后的数据到文件。
# 函数调用 开多线程
def run():
with ThreadPoolExecutor(max_workers=5) as executor:
executor.map(get_data, items)
wb.save('成果.xlsx')
print('===================== 数据成功下载完成 ======================')说明:
map(function, iterable, ...)
会根据提供的函数对指定序列做映射。
第一个参数 function 以参数序列中的每一个元素调用 function 函数,返回包含每次 function 函数返回值的新列表。
直白点说,就是map(a,b),a是函数,b是序列。把b一个一个的传入a去执行。有点循环的意思。
这个例子里的b就是从表格里获取的学校名称的list列表。有3000个左右,所以这个run()函数执行的话,得执行3000次
4、执行多线程函数
run()5、运行效果(不会做动图,所以这个动图是抄的大佬的图)

6、最后得到一个成果.xlsx文件
说明:
以上代码需要都抄到一个py文件里执行。
上面单独拆出来,主要是为了讲解。
最后:
感慨一句:年轻时辜负时光,会在你后续的人生中会加倍的来坑你。
以前上学的时候偷懒,HTML相关的知识基本没学。现在关于元素定位看起来太费劲了。
最最后:
公众号里一句高赞评论:学姐拿着成果.xlsx给男朋友说:“你看,舔狗还是好用吧”
参考:















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









