






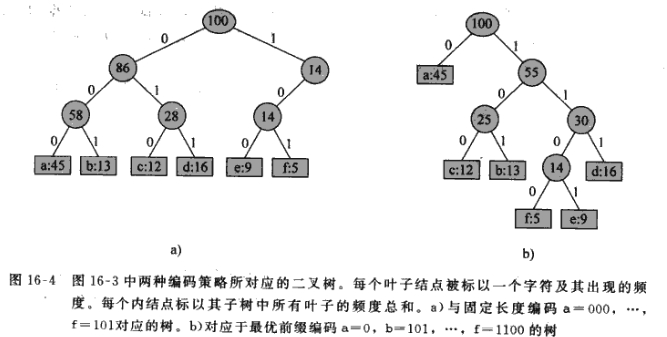
赫夫曼使用的编码是前缀码,即没有任何码字是其他码字的前缀。
编码鼠的结构是,可以用二叉树表示,其叶节点是给的的字符,字符的二进制编码用从跟结点到该字符的叶节点的简单路径表示,0即为向左走,1即为向右走,编码树并不是二叉搜索树,因为叶结点并没有排序,内结点不包含字符关键字。
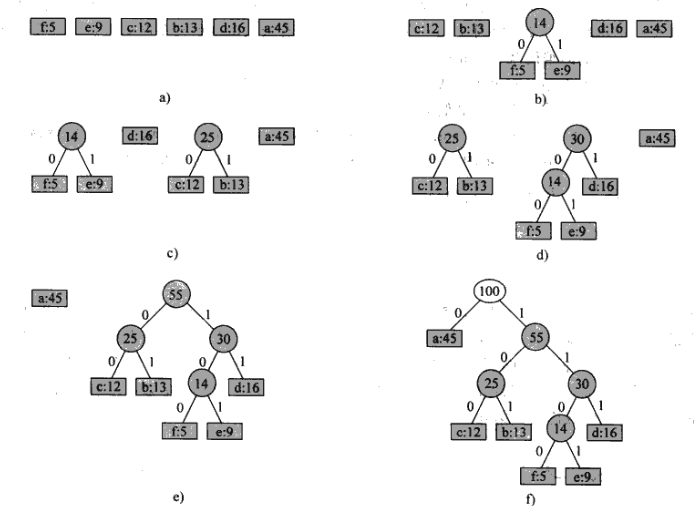
最优编码方案总是对应一棵“满”二叉树(书上这么写,但有点不对, 满二叉树是所有非叶子节点都有两个孩子结点,且所有叶节点在同一层上,但赫夫曼数的叶子节点并不一定在同一层上,一般都不在),即每个非叶子节点都有两个孩子结点。例如下面这棵树:
构造赫夫曼树借助最小堆,使结点按照结点的频率进行排序,用堆排序构成小顶堆,每次取出最小的两个频率,组合成一个新的频率并再次进入堆,形成新的小顶堆。如果有n个结点,共需要进行n-1次合并。
一下为代码:
#include <iostream>
#include <queue>
using namespace std;
//结点结构
struct huffmanTreeNode
{
int freq;
huffmanTreeNode *left;
huffmanTreeNode *right;
};
//用仿函数自定义排序准则,建立小顶堆
class phuffmanTreeNodeSort
{
public:
bool operator()(const huffmanTreeNode *htn1, const huffmanTreeNode *htn2)
{
return htn1->freq > htn2->freq;
}
};
const int n = 6;
huffmanTreeNode *huffman(huffmanTreeNode **arr)
{
typedef priority_queue<huffmanTreeNode *, vector<huffmanTreeNode *>, phuffmanTreeNodeSort> huffmanPq;
huffmanPq pq(arr, arr+n); //建立小顶堆,按照频率建立
//每次两个最小的结点合并成一个结点,并且重新插入堆,共需要n-1次合并
for (int i = 1; i <= n-1; i++)
{
huffmanTreeNode *newNode = new huffmanTreeNode;
newNode->left = pq.top();
pq.pop();
newNode->right = pq.top();
pq.pop();
newNode->freq = newNode->left->freq + newNode->right->freq;
pq.push(newNode);
}
return pq.top();
}
int main()
{
huffmanTreeNode *arr[n];
cout << "请输入六个频率:" << endl;
for (int i = 0; i < n; i++)
{
int freq;
huffmanTreeNode *node = new huffmanTreeNode;
node->left = NULL;
node->right = NULL;
cin >> freq;
node->freq = freq;
arr[i] = node;
}
cout << "哈夫曼树的根节点的频率:" << huffman(arr)->freq << endl;
system("pause");
return 0;
}
时间分析:huffman中建堆的过程花费时间为O(n), for循环共执行n-1次,每次都要重新调整堆一次,需要O(lgn)时间,所有循环总共花费On(lgn),所以总的运行时间是
O(nlgn)
运行结果为:
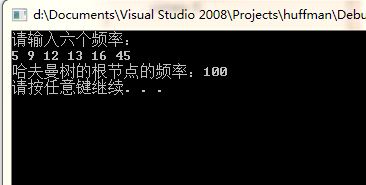















 983
983

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









