







一、ROC曲线与AUC的基础理解
ROC曲线
ROC曲线可以认为越靠上代表分类效果越好,网上的介绍是非常的多,在这里重点是在说明其中的一个应用,下面还会有部分介绍,但是具体没有提及的部分可以网上另外查,不是本文重点。
常用的二分类算法如逻辑回归,往往需要根据业务需求设定一个临界值(用以分开0和1,默认是0.5)。
我们举一个列子来说明这个临界值(Threshold)的作用,假设真实中有250个人信用卡会违约(Negative),250个人信用卡不会违约(Positive)。如下图所示,蓝色代表违约的人群分布,红色代表不违约的人群分布,这个例子中分类的效果还是挺好的,基本把两个人群分布分开了,ROC曲线也在左上角一小部分。图形的X轴代表预测的概率值,我们可以选择一个临界值作为0和1分类的分界点,Y轴代表观察的数量。
假如把临界值设为0.3,则左边星星面积部分可以认为被判断成违约(Negative)的人数是175个(也就是说有75个人错误地分类到不违约中),真实不违约的人100%都预测正确了,在这个例子中X值是0.3,Y值代表有大概50个人的预测概率等于0.3(根据高度瞎猜的)。
假如把临界值设为0.5,则左边划线部分面积代表的违约人数是250个,与真实值一样,但是因为有重叠的部分,250人被分类到违约的人中有大概20个人(根据图形比例瞎猜的)真实是不违约的(Positive)而错误地分类到了违约(Negative),也有大概20个人真实是违约的,但被分类到了不违约中。

上述的例子当然是一个比较理想的分类器,如果我们遇到的分类结果没那么好的时候,ROC曲线包括其临界值该怎么设定呢?
同样还是上面的例子,这时候可以看到整个违约的人群分布右移了(可以理解为坏人聪明了,懂得了伪装自己更接近好人,不会再有那种预测概率只有0.1那么明显的违约人士了,当然也有可能这个第二间银行,用的分类算法较上面的银行弱多了)。这时候两个人群的分布重叠的部分大多了,我们无论把临界值设在哪里都会较上一个产生更多的错误分类。
假如我们秉着“宁可杀错一万,不可放过一人”(有杀错冇放过)的信念把临界值设到0.8,则右边划线面积代表只有50个人(根据图形比例瞎猜的)会被分类到不违约(Positive)中,其余450人都会被归为违约(Negative),真实是不违约而错判的人有200个。
说了这么多我们回到ROC曲线上面去,ROC曲线的Y轴是TPR(True Positive Rate/Sensitivity),TPR=TP/(All Positive),X轴是FPR(False Positive/1-Specificity),FPR=FP/(All Negative)。因此拿第二个例子计算一下,TPR=50/250=0.2,FPR=0/250=0,因此我们取点(0,0.2)如下图ROC曲线所示,代表临界值的点。

AUC
AUC则是另外一个用于评估分类好坏的方法,其与ROC是相关联的(就是代表ROC曲线下面的面积,如下图所示的阴影部分)。分类的效果越好,ROC曲线越靠上,AUC的值越大。AUC值一般是在0.5到1之间浮动,如果AUC小于0.5,代表模型的精准度甚至不如瞎猜(瞎猜是0.5),同理,如果AUC等于1,则表明分类精度达到100%。

假设AUC的值是0.8,我们可以解读为:随机选择一个数据,有80%的机会它的True Positive(真实是正的样本被预测为正)得分会高于False Positive(真实为负的样本被预测为正)。
几点关于ROC和AUC的补充说明:
1. ROC是最常用的用于评估二分类器好坏的方法,它着重于图形化得出直观结论,而AUC则是通过single number总结模型好坏。
2. AUC用在Unbalanced data也完全没有问题
3. ROC在预测概率不是“精确校准”(比如概率不是正常的0~1)的情况下也有用
4. ROC也可以扩展用在多分类器的评估上:假设有3个类别(画三个ROC图)
Class 1 Vs Class 2 & 3
Class 2 Vs Class 1 & 3
Class 3 Vs Class 1 & 2
5. ROC曲线的临界值并没有说那个值是好是坏,更多是根据业务需求定的一个值(瞎举个例子,信用卡部门可能更多关心不违约的用户,尽可能地最大化利润,因此可以接受一个更低的临界值)
6. 上面的例子不代表现实世界案例,现实中更多的是不平衡的分类
7. 上面例子中两个类别的人群都是服从正态分布的,而现实中的分布各种各样
二、进阶理解
ROC和AUC是评价分类器的指标,上面第一个图的ABCD仍然使用,只是需要稍微变换。
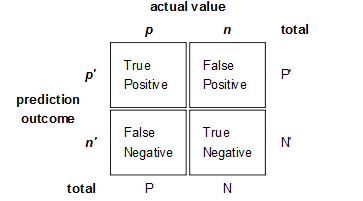
回到ROC上来,ROC的全名叫做Receiver Operating Characteristic。
ROC关注两个指标
True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率
False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率
在ROC 空间中,每个点的横坐标是FPR,纵坐标是TPR,这也就描绘了分类器在TP(真正的正例)和FP(错误的正例)间的trade-off。ROC的主要分析工具是一个画在ROC空间的曲线——ROC curve。我们知道,对于二值分类问题,实例的值往往是连续值,我们通过设定一个阈值,将实例分类到正类或者负类(比如大于阈值划分为正类)。因此我们可以变化阈值,根据不同的阈值进行分类,根据分类结果计算得到ROC空间中相应的点,连接这些点就形成ROC curve。ROC curve经过(0,0)(1,1),实际上(0, 0)和(1, 1)连线形成的ROC curve实际上代表的是一个随机分类器。一般情况下,这个曲线都应该处于(0, 0)和(1, 1)连线的上方。如图所示。

用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。
于是Area Under roc Curve(AUC)就出现了。顾名思义,AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance。
很多大牛对AUC都有自己的认识和理解,这里围绕和AUC的意义是什么,给出一些能帮助自己理解AUC的 大牛们的回答
[1]From 机器学习和统计里面的auc怎么理解?

[2]From 机器学习和统计里面的auc怎么理解?

[3]From 精确率、召回率、F1 值、ROC、AUC 各自的优缺点是什么?

[4]From 多高的AUC才算高?
参考资料:
















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









