







相同点:
(1)没有key的时候,replace与insert .. on deplicate udpate相同。
(2)有key的时候,都保留主键值,并且auto_increment自动+1。
不同点
有key的时候,replace是delete老记录,而录入新的记录,所以原有的所有记录会被清除,这个时候,如果replace语句的字段不全的话,有些原有的比如例子中c字段的值会被自动填充为默认值。
而insert .. deplicate update则只执行update标记之后的sql,从表象上来看相当于一个简单的update语句。
但是实际上,根据我推测,如果是简单的update语句,auto_increment不会+1,应该也是先delete,再insert的操作,只是在insert的过程中保留除update后面字段以外的所有字段的值。
所以两者的区别只有一个,insert .. on deplicate udpate保留了所有字段的旧值,再覆盖然后一起insert进去,而replace没有保留旧值,直接删除再insert新值。
从底层执行效率上来讲,replace要比insert .. on deplicate update效率要高,但是在写replace的时候,字段要写全,防止老的字段数据被删除。
例子
创建测试表:
create table test (auto_id int auto_increment primary key, code int, times int, name VARCHAR(10), unique key (code));INSERT INTO `test` (`code`, `times`, `name`) VALUES ('100', 1, 'wo');
常规的insert into只影响了一行。test表的数据:
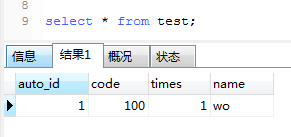
1、 Replace into …
REPLACE into 已经存在的key时:
REPLACE into `test` (`code`, `times`) VALUES ('100', 1);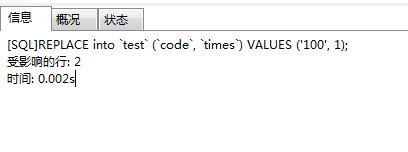
影响了2行。test表的数据:
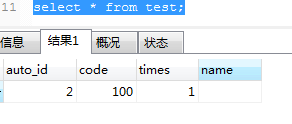
明显, auto_id自增1,name值为空,times则更新为2了。这说明当与key冲突时,replace覆盖相关字段,其它字段填充默认值,可以理解为删除重复key的记录,新插入一条记录,该语句做了 delete + insert 的操作,所以该语句影响了2行。
REPLACE into 不存在的key时:
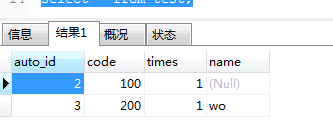
REPLACE into `test` (`code`, `times`, 'name') VALUES (200, 1, '你');
只影响了一行,相当于只做了insert操作。test表数据:
2、 Insert into on duplicate key update
已存在的key:
INSERT INTO `test` (`code`, `times`, `name`) VALUES (200, 2, 'wo') on DUPLICATE key update times = times + 1;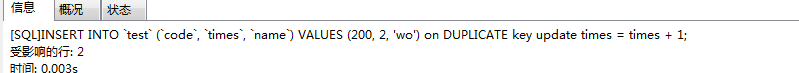
影响了2行。test表的数据:
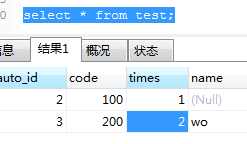
明显,name不变,times则更新为2了。这说明当与key冲突时,replace覆盖相关字段,其它字段保留原有值,可以理解为删除重复key的记录,新插入一条记录,该语句做了 delete + insert 的操作,所以该语句影响了2行。至于auto_id有没有自增,我们看一下他插入一条不存在的key时,看一下auto_id。如果有自增,下一条记录的auto_id为5,否者为4。
不存在的key:
INSERT INTO `test` (`code`, `times`, `name`) VALUES (300, 1, '你') on DUPLICATE key update times = times + 1;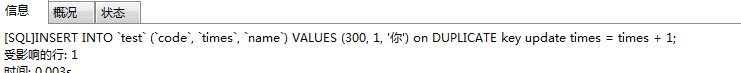
受影响1行。test表数据:
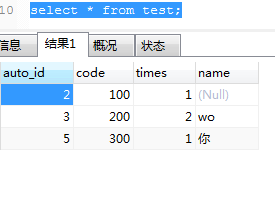
显然,Insert into on duplicate key update已经存在的key时,会自增长key会自增。不存在的key时,相当于只做了insert操作。
根据上面例子可以发现,结论正如我们在开头所列举的相同点和不同点。
MySQL 锁模式
对于普通的INSERT操作,当需要检查duplicate key时,加LOCK_S锁,即共享(S)锁,而对于Replace into 或者 INSERT..ON DUPLICATE操作,则加LOCK_X记录锁,也就是排他(X)锁。
InnoDB 实现了标准行级锁, 他有两种锁, 共享(S)锁和排他(X)锁. 需要看record, gap, next-key锁类型, 参照 xxx
- A shared (S) lock permits the transaction that holds the lock to read a row.
一个共享锁允许事务获取锁来读取一行
An exclusive (X) lock permits the transaction that holds the lock to update or delete a row.
- 一个排他锁允许事务获取锁来更新或删除一行
从字面的意思理解如下:
1、如果事务T1持有对行 r 的 S 锁, 那么另外一个事务T2对行 r 的请求会被马上授权.因此, T1 T2都对r持有一个共享锁。
2、如果一个事务T1持有一个r的X锁, 那么T2对r的任何锁类型都无法被马上授权. 替代的是T2必须等待T1释放他在r上的锁。
意向锁(Intention Locks)
另外, InnoDB支持多重粒度加锁, 这允许行锁和表所共存. 为了让多重粒度锁定具有实用性, 另外一种叫做意向锁的锁会被使用. 意向锁在InnoDB中是表锁, 他表明S或X锁将会在一个事务中对某一行使用. InnoDB有两种意向锁(假设事务T已经请求了表t的一个锁)
- Intention shared (IS): Transaction T intends to set S locks on individual rows in table t.
意向共享锁(IS): 事务T打算设置S锁到表t上
Intention exclusive (IX): Transaction T intends to set X locks on those rows.
- 意向排他锁(IX): 事务T打算设置X锁到行上
意向锁协议如下
- 意向共享锁(IS): 在一个事务获取表t的某行的S锁之前, 他必须获取表t的一个IS锁或更强的锁
- 意向排他锁(IX): 在一个事务获取表t某行的X锁之前, 他必须获取一个t的IX锁
一个锁如果和已经存在的锁兼容, 就可以授权给请求他的事务, 但如果和已存在的锁不兼容则不行.一个事务必须等待直到冲突的锁被释放.如果一个锁请求和一个已经存在的锁冲突, 并且一直不能被授权, 就会造成死锁.
因此, 意向锁并不会阻塞任何事情, 除非是对全表的请求(例如, LOCK TABLES … WRITE). IX和IS锁的主要目的是表示有人正在锁定一行, 或者准备锁定一行.















 1636
1636

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









