







essen源码参考https://github.com/yajiemiao/eesen,这里简单说一下涉及到训练前后向的核心算法源码实现。
以单句训练为准(多句并行类似),用到的变量
| 变量 | 含义 |
|---|---|
| phones_num | 最后一层输出节点个数,对应于|phones|+1 |
| labels_num | 一句话对应的标注扩展blank以后的个数,比如"123"扩展为"b1b2b3b" |
| frames_num | 一句话对应的总的帧数,对应于时间t |
| y k t y_k^t ykt | 最后一层输出 |
| a k t a_k^t akt | softmax层的输入 |
CTC error
ctc.Eval(net_out, targets, &obj_diff);
涉及到的变量的维度:
| 变量 | 维度 |
|---|---|
| net_out | frames_num*phones_num |
| alpha/beta | frames_num*labes_num |
| ctc_error | frames_num*phones_num |
本来可以使用最终的公式求出对 a k t a_k^t akt的error,代码中却分成了两部求解,可能逻辑上能体现出error反向传播的过程,但是实际感觉没有必要。
计算关于 y k t y_k^t ykt的error
ctc_err_.ComputeCtcError(alpha_, beta_, net_out, label_expand_, pzx);
参考[1]给出的公式(15)
计算关于 u k t u_k^t ukt的error
ctc_err_.MulElements(net_out);
CuVector<BaseFloat> row_sum(num_frames, kSetZero);
row_sum.AddColSumMat(1.0, ctc_err_, 0.0);
CuMatrix<BaseFloat> net_out_tmp(net_out);
net_out_tmp.MulRowsVec(row_sum);
diff->CopyFromMat(ctc_err_);
diff->AddMat(-1.0, net_out_tmp);
主要是
y
k
t
y_k^t
ykt对
a
k
t
a_k^t
akt进行求导,推导参考前面的博客,结论如下:
∂
L
∂
a
k
t
=
∑
k
′
∂
L
∂
y
k
′
t
y
k
′
t
δ
k
k
′
−
∑
k
′
∂
L
∂
y
k
′
t
y
k
′
t
y
k
t
\frac{\partial L}{\partial a_k^t}=\sum_{k'}\frac{\partial L}{\partial y_{k'}^t}y_{k'}^t\delta_{kk'}-\sum_{k'}\frac{\partial L}{\partial y_{k'}^t}y_{k'}^ty_k^t
∂akt∂L=k′∑∂yk′t∂Lyk′tδkk′−k′∑∂yk′t∂Lyk′tykt
=
∂
L
∂
y
k
t
y
k
t
−
∑
k
′
∂
L
∂
y
k
′
t
y
k
′
t
y
k
t
=\frac{\partial L}{\partial y_{k}^t}y_{k}^t-\sum_{k'}\frac{\partial L}{\partial y_{k'}^t}y_{k'}^ty_k^t
=∂ykt∂Lykt−k′∑∂yk′t∂Lyk′tykt
注意上式最后一项有一个求和的过程,即将t时刻对应的
y
k
t
y_k^t
ykt的所有节点的error累加。
沿网络反向传播error
| 变量 | 含义 |
|---|---|
| x | 每一层的输入 |
| y | 每一层的输出 |
| d_x | 关于x的error |
| d_y | 关于y的error |
| dim_in | 输入维度 |
| dim_out | 输出维度 |
| W | 每一层对应的参数矩阵 |
error依次经过affine-trans-layer和多层lstm-layer,每一层有两个目的:
- 求d_x: 将error传递到每一层的输入,以往后继续传播
- 求 Δ W \Delta W ΔW: 计算当前层的参数的error,以根据error更新参数
affine layer
| 变量 | 维度 |
|---|---|
| x/d_x | frames_num*dim_in |
| y/d_y | frames_num*dim_out |
| W | dim_out*dim_in |
前向
y = x ∗ W T y=x*W^T y=x∗WT
后向
Δ
W
(
t
)
=
d
_
y
T
∗
x
+
m
o
m
e
n
t
u
m
∗
Δ
W
(
t
−
1
)
\Delta W(t)=d\_y^T*x+momentum*\Delta W(t-1)
ΔW(t)=d_yT∗x+momentum∗ΔW(t−1)
这里参数更新有一个求和的过程,把所有时刻对应的
Δ
W
\Delta W
ΔW进行累加,相当于把所有时间的error数据进行了求和作为最终的error。
lstm layer
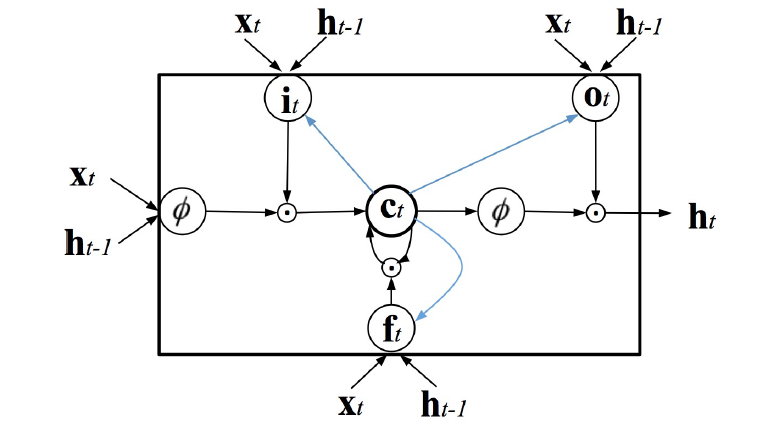
参考[2],eesen采用的lstm单元如上图,但是代码中变量的含义和论文中不一致。
前向
i
t
=
δ
(
x
t
W
i
x
T
+
m
t
−
1
W
i
m
T
+
c
t
−
1
W
i
c
T
+
b
i
)
i_t=\delta(x_tW_{ix}^T+m_{t-1}W_{im}^T+c_{t-1}W_{ic}^T+b_i)
it=δ(xtWixT+mt−1WimT+ct−1WicT+bi)
f
t
=
δ
(
x
t
W
f
x
T
+
m
t
−
1
W
f
m
T
+
c
t
−
1
W
f
c
T
+
b
i
)
f_t=\delta(x_tW_{fx}^T+m_{t-1}W_{fm}^T+c_{t-1}W_{fc}^T+b_i)
ft=δ(xtWfxT+mt−1WfmT+ct−1WfcT+bi)
g
t
=
δ
(
x
t
W
c
x
T
+
m
t
−
1
W
c
m
T
+
b
c
)
g_t=\delta(x_tW_{cx}^T+m_{t-1}W_{cm}^T+b_c)
gt=δ(xtWcxT+mt−1WcmT+bc)
c
t
=
f
t
⊙
c
t
−
1
+
i
t
⊙
g
t
c_t=f_t\odot c_{t-1}+i_t\odot g_t
ct=ft⊙ct−1+it⊙gt
o
t
=
δ
(
x
t
W
o
x
T
+
m
t
−
1
W
o
m
T
+
c
t
W
o
c
T
+
b
o
)
o_t=\delta(x_tW_{ox}^T+m_{t-1}W_{om}^T+c_{t}W_{oc}^T+b_o)
ot=δ(xtWoxT+mt−1WomT+ctWocT+bo)
h
t
=
ϕ
(
c
t
)
h_t=\phi (c_t)
ht=ϕ(ct)
m
t
=
o
t
⊙
h
t
m_t=o_t\odot h_t
mt=ot⊙ht
有两方面的并行
- gifo合并成一个矩阵
- 批量计算输入x(不依赖于t),然后再分帧计算其他变量
后向
D
i
=
∂
L
∂
(
x
t
W
i
x
T
+
m
t
−
1
W
i
m
T
+
c
t
−
1
W
i
c
T
+
b
i
)
D_i=\frac{\partial L}{\partial (x_tW_{ix}^T+m_{t-1}W_{im}^T+c_{t-1}W_{ic}^T+b_i)}
Di=∂(xtWixT+mt−1WimT+ct−1WicT+bi)∂L
D
f
=
∂
L
∂
(
x
t
W
f
x
T
+
m
t
−
1
W
f
m
T
+
c
t
−
1
W
f
c
T
+
b
i
)
D_f=\frac{\partial L}{\partial (x_tW_{fx}^T+m_{t-1}W_{fm}^T+c_{t-1}W_{fc}^T+b_i)}
Df=∂(xtWfxT+mt−1WfmT+ct−1WfcT+bi)∂L
D
g
=
∂
L
∂
(
x
t
W
c
x
T
+
m
t
−
1
W
c
m
T
+
b
c
)
D_g=\frac{\partial L}{\partial (x_tW_{cx}^T+m_{t-1}W_{cm}^T+b_c)}
Dg=∂(xtWcxT+mt−1WcmT+bc)∂L
D
o
=
∂
L
∂
(
x
t
W
o
x
T
+
m
t
−
1
W
o
m
T
+
c
t
W
o
c
T
+
b
o
)
D_o=\frac{\partial L}{\partial (x_tW_{ox}^T+m_{t-1}W_{om}^T+c_{t}W_{oc}^T+b_o)}
Do=∂(xtWoxT+mt−1WomT+ctWocT+bo)∂L
D
c
=
∂
L
∂
(
f
t
⊙
c
t
−
1
+
i
t
⊙
g
t
)
D_c=\frac{\partial L}{\partial (f_t\odot c_{t-1}+i_t\odot g_t)}
Dc=∂(ft⊙ct−1+it⊙gt)∂L
有两个注意点
- m t m_t mt的error除了来自于t时刻的error,还有来至于t+1时刻的 D i D_i Di/ D f D_f Df/ D o D_o Do/ D g D_g Dg
- c t c_t ct的error除了来自于t时刻的error,还有来自于t+1时刻的 D i D_i Di/ D f D_f Df/ D c D_c Dc
参考文献
[1].Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
[2].Essen: End-to-End Speech Recognition Using Deep Rnn Models and WFST-Based Decoding
后面的技术分享转移到微信公众号上面更新了,【欢迎扫码关注交流】
















 1989
1989

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









