








文本匹配工具
RuleFinder 文本匹配工具是一个用于快速编写匹配规则,提取文本的工具。
源码地址: https://github.com/xmxoxo/RuleFinder
当前版本号:0.1.12
update: 2020/6/12
本工具包括:类库,规则编辑器,批量提取器。
RuleLib.py 类库,可自行引用到项目中使用;
RuleEditor.py 规则编辑器,基于flask的WEB应用,可在浏览器中编辑规则;
RulePicker.py 规则提取器,可加载规则后从批量文件中提取匹配结果;
工具有什么用?
在做NLP的前期文本处理工作时,需要对文本进行人工的分析,使用一些关键词或者句式等来匹配查找文本;甚至在一些简单的模型与处理中,也需要使用文本匹配的方式来对文本进行匹配处理,当然我们可以写很多正则表达式,但正则表达式太过复杂,普通情况下不会用到,而且正则表达式多了也不方便管理,于是产生了这个小工具。
文本匹配工具,使用简便的匹配规则来对文本进行匹配。工具提供了基于WEB的规则编辑器,可快速编辑规则,验证规则的匹配结果。
案例:按规则提取句子分类
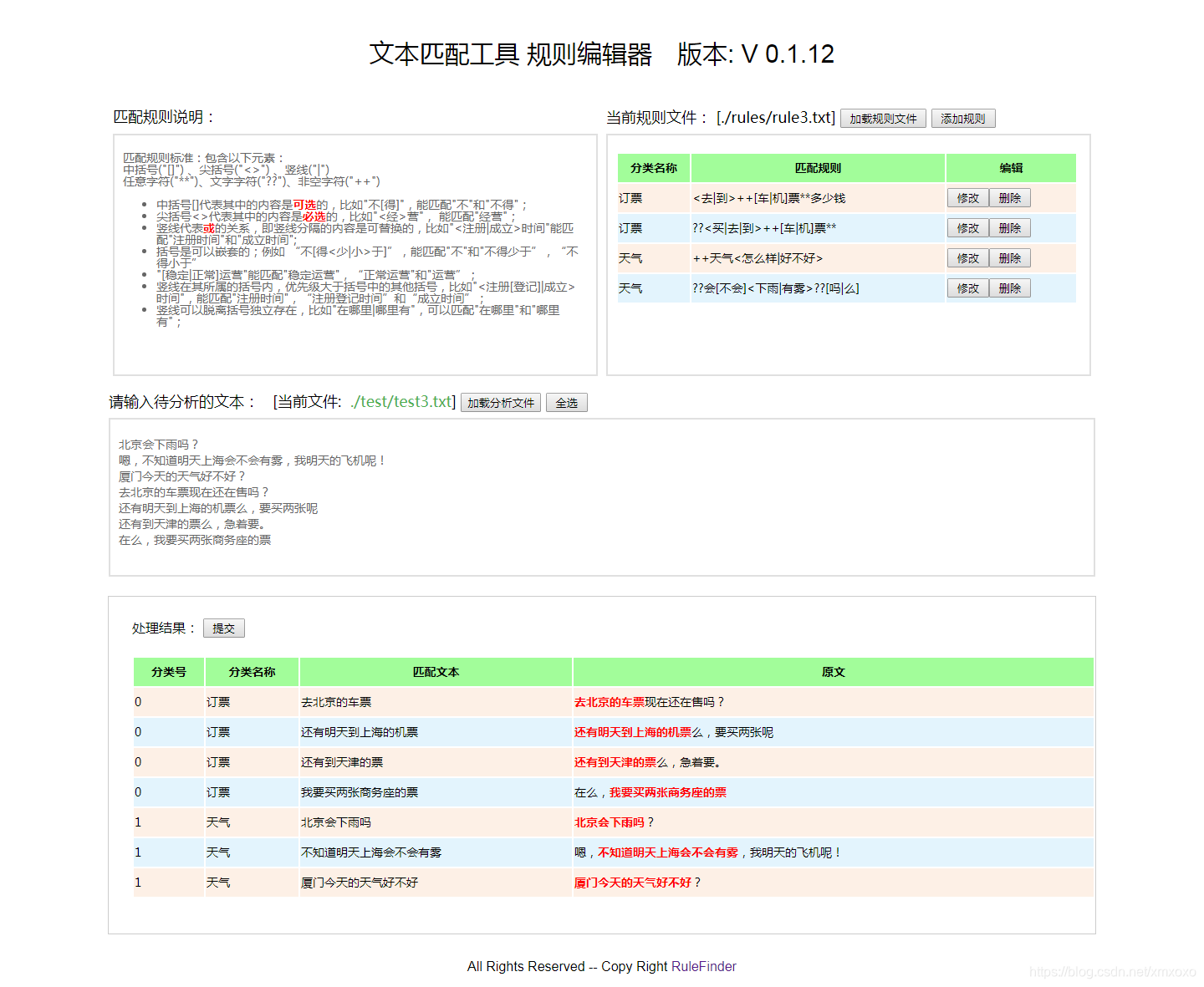
运行以下命令即可启动案例:
pip install -r requirements.txt
python RuleEditor.py -rule_file ./rules/rule3.txt -test_file ./test/test3.txt
然后在浏览器中访问:http://127.0.0.1:8910
匹配规则
匹配规则包含以下元素:
- 中括号("[]") : 代表其中的内容是可选
- 尖括号("<>") : 代表其中的内容是必选
- 竖线("|") : 代表或的关系;
- 任意字符("**"): 匹配任意的字符;
- 文字字符("??"):匹配汉字字符,区间为:[\u4E00-\u9FA5]
- 非空字符("++"):匹配一个以上非空字符,非空字符正则为:
"(?:[^ ,;;。‘’"“”]+?)"
匹配规则与正则相似,规则如下:
-
中括号[]: 代表其中的内容是可选的,比如:
“不[得]”,能匹配 “不"和"不得”;
-
尖括号<>: 代表其中的内容是必选的,比如:
“<经>营”, 能匹配 “经营”
-
竖线("|"):代表或的关系,即竖线分隔的内容是可替换的,比如:
“<注册|成立>时间” 能匹配 “注册时间” 和 “成立时间”
-
括号(): 是可以嵌套的;例如:
“不[得<少|小>于]” 能匹配: “不”,"不得少于”,“不得小于”
“[稳定|正常]运营” 能匹配: “稳定运营”,“正常运营”,“运营”
-
竖线在其所属的括号内,优先级大于括号中的其他括号,比如
“<注册[登记]|成立>时间” 能匹配: “注册时间”,“注册登记时间”,“成立时间”
-
竖线可以脱离括号独立存在,比如:
“在哪里|哪里有” 可以匹配: “在哪里"和"哪里有”
更新日志
v 0.1.12
- 增加了加载数据文件的功能;
- 各个客户端之间的规则文件及数据分析相互独立,不会干扰。可打开不同浏览器看效果;
v 0.1.10
- 可加载规则文件;
- 可对规则进行增,删,改;
使用案例
- 安装依赖包
pip install -r requirements.txt
- ** 启动规则编辑器 **
运行以下命令,使用默认参数启动启动规则编辑器:
python RuleEditor.py
详细参数可见:
python RuleEditor.py -h
默认启动时监听0.0.0.0:8910 端口
默认加载规则文件为:./rules/rule.txt
默认加载数据文件为: ./test/test.txt
- 访问规则编辑器
使用浏览器打开以下地址访问规则编辑器:http://127.0.0.1:8910
浏览器界面如下:

在浏览器界面中可以完成:
- 规则文件加载;
- 规则文件新建;
- 规则添加、删除、编辑;
- 对数据文件测试当前规则文件所有规则;
- 使用规则提取器
完成规则编辑后,可以使用规则提取器,对整个目录下的文件批量提取结果。
运行以下命令可运行demo:
python RulePicker.py -rule ./rules/rule.txt
运行示例如下:
13:36:55.38|F:>python RulePicker.py -rule ./rules/rule.txt
正在批量处理,请稍候...
正在匹配文件:./test/test.txt
正在匹配文件:./test/test1.txt
正在匹配文件:./test/test2.txt
保存结果:./output/result_20200611134436.csv
匹配用时: 0.03秒
匹配结果共3个文件:
=====文件:test 匹配:5条=====
=====文件:test1 匹配:1条=====
=====文件:test2 匹配:2条=====
详细参数运行以下命令查看:
python RulePicker.py -h
参数如下:
12:01:36.57|F:>RulePicker.py -h
usage: RulePicker.py [-h] -rule RULE [-data DATA] [-output OUTPUT]
RulePicker v_0.1.10 by xmxoxo
optional arguments:
-h, --help show this help message and exit
-rule RULE rule file
-data DATA data file path, default: ./test/
-output OUTPUT output path, default: ./output/

















 1014
1014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









