







转自 http://blog.csdn.net/shagoo/article/details/5974643
一致性哈希算法来源于 P2P 网络的路由算法,目前主流的 P2P 软件就是利用我们所熟知的 DHT (Distributed Hash Table,分布式哈希表) 来定位整个分布式网络的信息,另外此算法在目前火热的云计算领域也将占有极其重要的位置。可以说散列函数在当代计算机和网络系统中所起的重要作用大家应该都有目共睹了,特别是在目前这个分布式应用爆炸的时代,这个方面的知识只会越来越引起人们的重视,本文重在从 Memcached 这个流行的分布式应用的场景中来对一致性哈希散列的几个主流算法做一些比较和分析。
[背景信息]
对于 Memcached 来说,本身是集中式的缓存系统,要搞多节点分布,只能通过客户端实现。Memcached 的分布算法一般有两种选择:
1、根据 hash(key) 的结果,模连接数的余数决定存储到哪个节点,也就是 hash(key) % sessions.size(),这个算法简单快速,表现良好。然而这个算法有个缺点,就是在memcached节点增加或者删除的时候,原有的缓存数据将大规模失效,命中率大受影响,如果节点数多,缓存数据多,重建缓存的代价太高,因此有了第二个算法。
2、Consistent Hashing,一致性哈希算法,他的查找节点过程如下:首先求出 Memcached 服务器(节点)的哈希值,并将其配置到 0~232 的圆(continuum)上。然后用同样的方法求出存储数据的键的哈希值,并映射到圆上。然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过 232 仍然找不到服务器,就会保存到第一台 Memcached 服务器上。
下图就是一致性哈希算法算法的示意图,比如我们现在有 4 台服务器,我们把他们的 hash 值当作 node 节点按照某种平均分布算法被分配到这个环上面,我们按顺时针方向 把 Key 的哈希值与 node 节点的 hash 值比较,总是把 Key 节点保存到找到的第一个 hash 值大于 Key 节点的那个 node 节点服务器上:

现在假如我们有一台新的服务器加入进来(减少一个服务器同理),那么按照此前的算法,受影响的 Key 值只有下图黄色那部分的数据,从某种意义上甚至这样可以说,加入的服务器 node 节点越多,受影响的数据就越少 ,从而使这个动态的分布式系统中的数据稳定性达到最大,而这就是一致性哈希算法的精髓所在了:

Spymemcached 和 Xmemcached 都实现了一致性算法,这里要测试下在使用一致性哈希的情况下,增加节点,看不同散列函数下命中率和数据分布的变化情况,这个测试结果对于 Spymemcached 和 Xmemcached 是一样的,测试场景:
从一篇英文小说(《黄金罗盘》前三章)进行单词统计,并将最后的统计结果存储到 Memcached,以单词为 Key,以次数为 Value。单词个数为 3061,Memcached 原来节点数为10,运行在局域网内同一台服务器上的不同端口,在存储统计结果后,增加两个 Memcached 节点(也就是从 10个节点增加到12个节点),统计此时的缓存命中率并查看数据的分布情况。
结果如下表格,命中率一行表示增加节点后的命中率情况(增加前为100%),后续的行表示各个节点存储的单词数,CRC32_HASH 表示采用 CRC32 散列函数,KETAMA_HASH 是基于 md5 的散列函数也是默认情况下一致性哈希的推荐算法,FNV1_32_HASH 就是 FNV 32 位散列函数,NATIVE_HASH 就是 java.lang.String.hashCode() 方法返回的 long 取 32 位的结果,MYSQL_HASH 是 Xmemcached 添加的传说来自于 mysql 源码中的哈希函数。
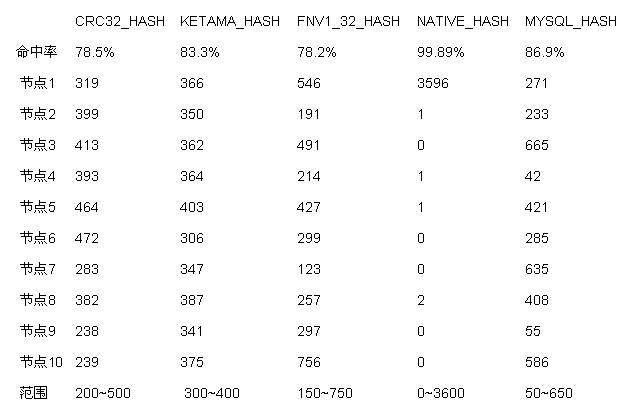
[结果分析]
1、命中率最高看起来是NATIVE_HASH,然而NATIVE_HASH情况下数据集中存储在第一个节点,显然没有实际使用价值。为什么会集中存储在第一个节点呢?这是由于在查找存储的节点的过程中,会比较hash(key)和hash(节点IP地址),而在采用了NATIVE_HASH的情况下,所有连接的hash值会呈现一个递增状况(因为String.hashCode是乘法散列函数),如:
192.168.0.100:12000 736402923
192.168.0.100:12001 736402924
192.168.0.100:12002 736402925
192.168.0.100:12003 736402926
如果这些值很大的会,那么单词的hashCode()会通常小于这些值的第一个,那么查找就经常只找到第一个节点并存储数据,当然,这里有测试的局限性,因为memcached都跑在一个台机器上只是端口不同造成了hash(节点IP地址)的连续递增,将分布不均匀的问题放大了。
2、从结果上看,KETAMA_HASH 维持了一个最佳平衡,在增加两个节点后还能访问到83.3%的单词,并且数据分布在各个节点上的数目也相对平均,难怪作为默认散列算法。
3、最后,单纯比较下散列函数的计算效率:
CRC32_HASH:3266
KETAMA_HASH:7500
FNV1_32_HASH:375
NATIVE_HASH:187
MYSQL_HASH:500
简单看以上算法的效率排序如下:
NATIVE_HASH > FNV1_32_HASH > MYSQL_HASH > CRC32_HASH > KETAMA_HASH
综上所述,大家可以比较清楚的看出哪种 hash 算法适合你所在的场景,对于分布式应用,本人比较推荐在 CRC32_HASH、FNV1_32_HASH、KETAMA_HASH 这三种算法中选择,至于你是注重算法效率还是命中率,这就需要根据具体的场景来选择了。另外,对于 PHP 客户端可以通过 Memcache 扩展如下配置(在 php.ini 中)来选择:
memcache.hash_function={crc32(default),fnv}
memcache.hash_strategy={consistent(default),standard}
然后通过 Memcache::addServer 函数即可添加服务器节点了,相当方便哦~















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









